MapReduce简介
MapReduce是面向大数据并行处理的计算模型、框架和平台,它隐含了以下三层含义:
1)MapReduce是一个基于集群的高性能并行计算平台(Cluster Infrastructure)。它允许用市场上普通的商用服务器构成一个包含数十、数百至数千个节点的分布和并行计算集群。
2)MapReduce是一个并行计算与运行软件框架(Software Framework)。它提供了一个庞大但设计精良的并行计算软件框架,能自动完成计算任务的并行化处理,自动划分计算数据和计算任务,在集群节点上自动分配和执行任务以及收集计算结果,将数据分布存储、数据通信、容错处理等并行计算涉及到的很多系统底层的复杂细节交由系统负责处理,大大减少了软件开发人员的负担。
3)MapReduce是一个并行程序设计模型与方法(Programming Model & Methodology)。它借助于函数式程序设计语言Lisp的设计思想,提供了一种简便的并行程序设计方法,用Map和Reduce两个函数编程实现基本的并行计算任务,提供了抽象的操作和并行编程接口,以简单方便地完成大规模数据的编程和计算处理。
什么是数据倾斜及数据倾斜是怎么产生
简单来说数据倾斜就是数据的key 的分化严重不均,造成一部分数据很多,一部分数据很少的局面。
举个 word count 的入门例子,它的map 阶段就是形成 (“aaa”,1)的形式,然后在reduce 阶段进行 value 相加,得出 “aaa” 出现的次数。若进行 word count 的文本有100G,其中 80G 全部是 “aaa” 剩下 20G 是其余单词,那就会形成 80G 的数据量交给一个 reduce 进行相加,其余 20G 根据 key 不同分散到不同 reduce 进行相加的情况。如此就造成了数据倾斜,临床反应就是 reduce 跑到 99%然后一直在原地等着 那80G 的reduce 跑完。
如下图:
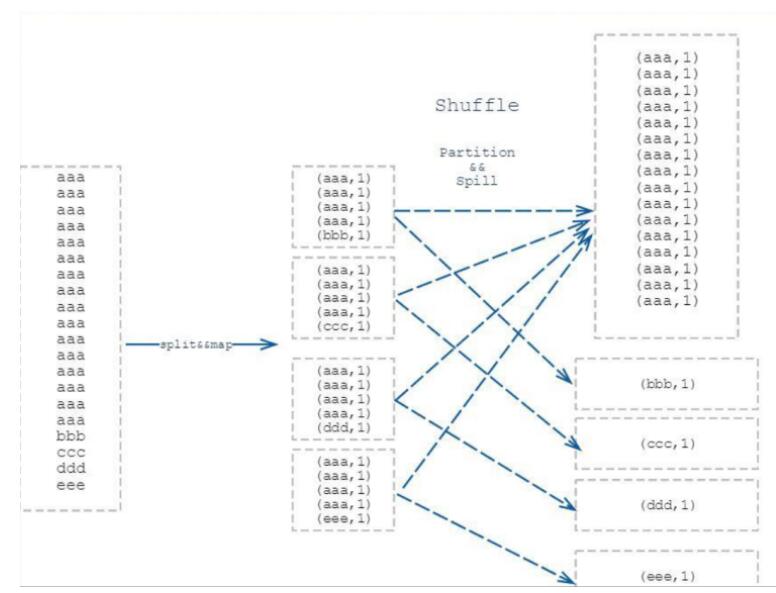
这样就能清楚看到,数据经过 map后,由于不同key 的数据量分布不均,在shuffle 阶段中通过 partition 将相同的 key 的数据打上发往同一个 reducer 的标记,然后开始 spill (溢写)写入磁盘,最后merge成最终map阶段输出文件。
如此一来 80G 的 aaa 将发往同一个 reducer ,由此就可以知道 reduce 最后 1% 的工作在等什么了。
为什么说数据倾斜与业务逻辑和数据量有关
从另外角度看数据倾斜,其本质还是在单台节点在执行那一部分数据reduce任务的时候,由于数据量大,跑不动,造成任务卡住。若是这台节点机器内存够大,CPU、网络等资源充足,跑 80G 左右的数据量和跑10M 数据量所耗时间不是很大差距,那么也就不存在问题,倾斜就倾斜吧,反正机器跑的动。所以机器配置和数据量存在一个合理的比例,一旦数据量远超机器的极限,那么不管每个key的数据如何分布,总会有一个key的数据量超出机器的能力,造成 reduce 缓慢甚至卡顿。
业务逻辑造成的数据倾斜会多很多,日常使用过程中,容易造成数据倾斜的原因可以归纳为几点:
容易造成数据倾斜的原因
分组 注:group by 优于distinct group
情形:group by 维度过小,某值的数量过多
后果:处理某值的reduce非常耗时
去重 distinct count(distinct xx)
情形:某特殊值过多
后果:处理此特殊值的reduce耗时
连接 join
情形1:其中一个表较小,但是key集中
后果1:分发到某一个或几个Reduce上的数据远高于平均值
情形2:大表与大表,但是分桶的判断字段0值或空值过多
后果2:这些空值都由一个reduce处理,非常慢
数据倾斜的影响
hadoop 中数据倾斜会极大影响性能和效率。
数据分布(导致数据倾斜)
正常的数据分布理论上都是倾斜的,就是我们所说的20-80原理:80%的财富集中在20%的人手中, 80%的用户只使用20%的功能 , 20%的用户贡献了80%的访问量 , 不同的数据字段可能的数据倾斜一般有两种情况:
一种是唯一值非常少,极少数值有非常多的记录值(唯一值少于几千)
一种是唯一值比较多,这个字段的某些值有远远多于其他值的记录数,但是它的占比也小于百分之一或千分之一
或是这么说:
1. 数据频率倾斜——某一个区域的数据量要远远大于其他区域。
2. 数据大小倾斜——部分记录的大小远远大于平均值。
分区
常见的mapreduce分区方式为hash 和range ,
hash partition 的好处是比较弹性,跟数据类型无关,实现简单(设定reduce个数就好,一般不需要自己实现)
range partition 需要实现者自己了解数据分布, 有时候需要手工做sample取样. 同时也不够弹性, 表现在几个方面:
1. 对同一个表的不同字段都需要实现不同的range partition, 对于时间这种字段根据查询类型的不同或者过滤条件的不同切分range 的大小都不一定.
2 .有时候可能设计使用多个字段组合的情况, 这时候又不能使用之前单个字段的partition 类, 并且多个字段组合之间有可能有隐含的联系,比如出生日期和星座,商品和季节.
3. 手工做sample 非常耗时间,需要使用者对查询使用的数据集的分布有领域知识.
4. 分配方式是死的,reduce 个数是确定的,一旦某种情况下发生倾斜,调整参数
其他的分区类型还有hbase 的hregionpartitioner 或者totalorder partitioner 等.
解决方案一
1、调优参数
set hive.map.aggr=true;
set hive.groupby.skewindata=true;
hive.map.aggr=true:在map中会做部分聚集操作,效率更高但需要更多的内存。
hive.groupby.skewindata=true:数据倾斜时负载均衡,当选项设定为true,生成的查询计划会有两个MRJob。第一个MRJob 中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的GroupBy Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MRJob再根据预处理的数据结果按照GroupBy Key分布到Reduce中(这个过程可以保证相同的GroupBy Key被分布到同一个Reduce中),最后完成最终的聚合操作。
由上面可以看出起到至关重要的作用的其实是第二个参数的设置,它使计算变成了两个mapreduce,先在第一个中在 shuffle 过程 partition 时随机给 key 打标记,使每个key 随机均匀分布到各个 reduce 上计算,但是这样只能完成部分计算,因为相同key没有分配到相同reduce上,所以需要第二次的mapreduce,这次就回归正常 shuffle,但是数据分布不均匀的问题在第一次mapreduce已经有了很大的改善,因此基本解决数据倾斜。
2、在 key 上面做文章,在 map 阶段将造成倾斜的key 先分成多组,例如 aaa 这个 key,map 时随机在 aaa 后面加上 1,2,3,4 这四个数字之一,把 key 先分成四组,先进行一次运算,之后再恢复 key 进行最终运算。
3、能先进行 group 操作的时候先进行 group 操作,把 key 先进行一次 reduce,之后再进行 count 或者 distinct count 操作。
4、join 操作中,使用 map join 在 map 端就先进行 join ,免得到reduce 时卡住。
以上4中方式,都是根据数据倾斜形成的原因进行的一些变化。要么将 reduce 端的隐患在 map 端就解决,要么就是对 key 的操作,以减缓reduce 的压力。总之了解了原因再去寻找解决之道就相对思路多了些,方法肯定不止这4种。
看了其他的博客
解决方案二
1. 增加reduce 的jvm内存
2. 增加reduce 个数
3. customer partition
4. 其他优化的讨论.
5. reduce sort merge排序算法的讨论
6. 正在实现中的hive skewed join.
7. pipeline
8. distinct
9. index 尤其是bitmap index
方式1
既然reduce 本身的计算需要以合适的内存作为支持,在硬件环境容许的情况下,增加reduce 的内存大小显然有改善数据倾斜的可能,这种方式尤其适合数据分布第一种情况,单个值有大量记录, 这种值的所有纪录已经超过了分配给reduce 的内存,无论你怎么样分区这种情况都不会改变. 当然这种情况的限制也非常明显,
1. 内存的限制存在
2. 可能会对集群其他任务的运行产生不稳定的影响.
方式2
这个对于数据分布第二种情况有效,唯一值较多,单个唯一值的记录数不会超过分配给reduce 的内存. 如果发生了偶尔的数据倾斜情况,增加reduce 个数可以缓解偶然情况下的某些reduce 不小心分配了多个较多记录数的情况. 但是对于第一种数据分布无效.
方式3
一种情况是某个领域知识告诉你数据分布的显著类型,比如hadoop definitive guide 里面的温度问题,一个固定的组合(观测站点的位置和温度) 的分布是固定的, 对于特定的查询如果前面两种方式都没用,实现自己的partitioner 也许是一个好的方式.
方式5
reduce 分配的内存远小于处理的数据量时,会产生multi-pass sort 的情况是瓶颈,那么就要问
1. 这种排序是有必要的嘛?
2. 是否有其他排序算法或优化可以根据特定情况降低他瓶颈的阈值?
3. map reduce 适合处理这种情况嘛?
关于问题1. 如果是group by , 那么对于数据分布情况1 ,hash 比sort 好非常多,即使某一个reduce 比其他reduce 处理多的多的数据,hash 的计算方式也不会差距太大.
问题2. 一个是如果实现block shuffle 肯定会极大的减少排序本身的成本, 另外,如果分区之后的reduce 不是使用copy –> sort-merge –> reduce 的计算方式, 在copy 之后将每个block 的头部信息保存在内存中,不用sort – merge 也可以直接计算reduce, 只不过这时候变成了随机访问,而不是现在的sort-merge 之后的顺序访问. block shuffle 的实现有两种类型,一种是当hadoop 中真正有了列数据格式的时候,数据有更大的机会已经排过序并且按照block 来切分,一般block 为1M ( 可以关注avro-806 ) , 这时候的mapper 什么都不做,甚至连计算分区的开销都小了很多倍,直接进入reduce 最后一步,第二种类型为没有列数据格式的支持,需要mapper 排序得到之后的block 的最大最小值,reduce 端在内存中保存最大最小值,copy 完成后直接用这个值来做随机读然后进行reduce. ( block shuffle 的实现可以关注 MAPREDUCE-4039 , hash 计算可以关注 MAPREDUCE-1639)
问题3 . map reduce 只有两个函数,一个map 一个 reduce, 一旦发生数据倾斜就是partition 失效了,对于join 的例子,某一个key 分配了过多的记录数,对于只有一次partittion的机会,分配错了数据倾斜的伤害就已经造成了,这种情况很难调试,但是如果你是基于map-reduce-reduce 的方式计算,那么对于同一个key 不需要分配到同一个reduce 中,在第一个reduce 中得到的结果可以在第二个reduce 才汇总去重,第二个reduce 不需要sort – merge 的步骤,因为前一个reduce 已经排过序了,中间的reduce 处理的数据不用关心partition 怎么分,处理的数据量都是一样大,而第二个reduce 又不使用sort-merge 来排序,不会遇到现在的内存大小的问题,对于skewed join 这种情况瓶颈自然小很多.
方式6
目前hive 有几个正在开发中的处理skewed join 情况的jira case, HIVE-3086 , HIVE-3286 ,HIVE-3026 . 简单介绍一下就是facebook 希望通过手工处理提前枚举的方式列出单个倾斜的值,在join 的时候将这些值特殊列出当作map join 来处理,对于其他值使用原来的方式. 我个人觉得这太不伸缩了,值本身没有考虑应用过滤条件和优化方式之后的数据量大小问题,他们提前列出的值都是基于整个分区的. join key 如果为组合key 的情况也应该没有考虑,对metastore 的储存问题有限制,对输入的大表和小表都会scan 两次( 一次处理非skew key , 一次处理skew key 做map join), 对输出表也会scan 两次(将两个结果进行merge) , skew key 必须提前手工列出这又存在额外维护的成本,目前因为还没有完整的开发完到能够投入生产的情况,所以等所有特性处理完了有了文档在看看这个处理方式是否有效,我个人认为的思路应该是接着bucked map join 的思路往下走,只不过不用提前处理cluster key 的问题, 这时候cluster key 的选择应该是join key + 某个能分散join key 的列, 这等于将大表的同一个key 的值分散到了多个不同的reduce 中,而小表的join key 也必须cluster 到跟大表对应的同一个key , join 中对于数据分布第二种情况不用太难,增加reduce 个数就好,主要是第一种,需要大表的join key 能够分散,对于同样join key 的小表又能够匹配到所有大表中的记录. 这种思路就是不用扫描大表两遍或者结果输出表,不需要提前手工处理,数据是动态sample 的应用了过滤条件之后的数据,而不是提前基于统计数据的不准确结果. 这个基本思路跟tenzing 里面描述的distributed hash join 是一样的,想办法切成合适的大小然后用hash 和 map join .
方式7
当同时出现join 和group 的时候, 那么这两个操作应该是以pipeline (管道) 的方式执行. 在join 的时候就可以直接使用group 的操作符减少大量的数据,而不是等待join 完成,然后写入磁盘,group 又读取磁盘做group操作. HIVE-2206 正在做这个优化. hive 里面是没有pipeline 这个概念的. 像是cloudera 的crunch 或者twitter 的Scalding 都是有这种概念的.
方式8
distinct 本身就是group by 的一种简写,我原先以为count(distinct x)这种跟group by 是一样的,但是发现hive 里面distinct 明显比group by 要慢,可能跟group by 会有map 端的combiner有关, 另外观察到hive 在预估count(distinct x) 的reduce 个数比group by 的个数要少 , 所以hive 中使用count(distinct x) , 要么尽量把reduce 个数设置大,直接设置reduce 个数或者hive.exec.reducers.bytes.per.reducer 调小,我个人比较喜欢调后面一个,hive 目前的reduce 个数没有统计信息的情况下就是用map端输入之前的数值, 如果你是join 之后还用count(distinct x) 的话,这个默认值一般都会悲剧,如果有where 条件并能过滤一定数量的数据,那么默认reduce 个数可能就还好一点. 不管怎样,多浪费一点reduce slot 总比等十几甚至几十分钟要好, 或者转换成group by 的写法也不错,写成group by 的时候distributed by 也很有帮助.
方式9
hive 中的index 就是物化视图,对于group by 和distinct 的情况等于变成了map 端在做计算,自然不存在倾斜. 尤其是bitmap index , 对于唯一值比较少的列优势更大,不过index 麻烦的地方在于需要判断你的sql 是不是常用sql , 另外如果create index 的时候没有选你查询的时候用的字段,这个index 是不能用的( hive 中是永远不可能有DBMS中的用index 去lookup 或者join 原始表这种概念的)
总结
数据倾斜没有一劳永逸的方式可以解决,了解你的数据集的分布情况,然后了解你所使用计算框架的运行机制和瓶颈,针对特定的情况做特定的优化,做多种尝试,观察是否有效.
参考博文:
https://www.zhihu.com/question/27593027
