DataFrame和Dataset
*DataFrame产生背景
*DataFrame简述
*DataFrame对比RDD
*DataFrame基本API常用操作
*DataFrame与RDD互操作
*DataFrame API操作案例
*Dataset简述
No.1 DataFrame产生背景
首先我们看一些图
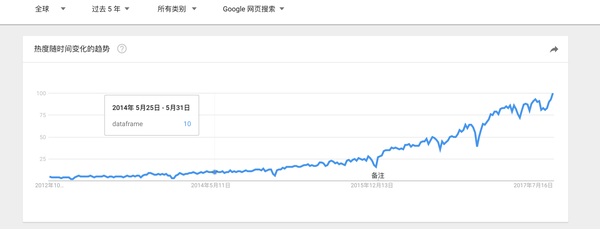
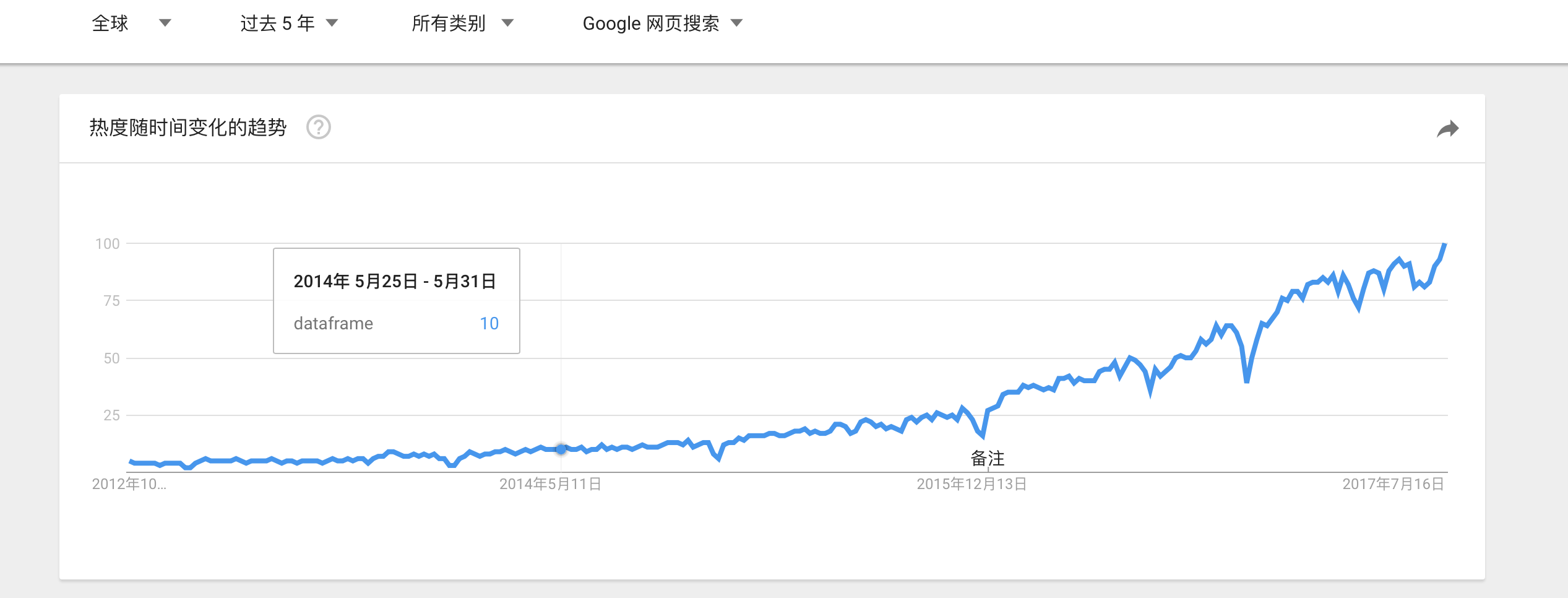
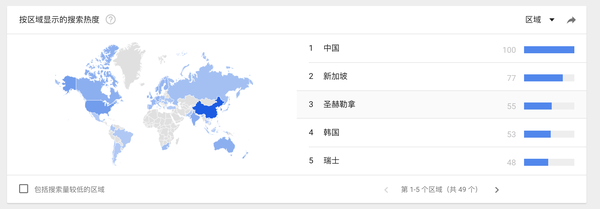
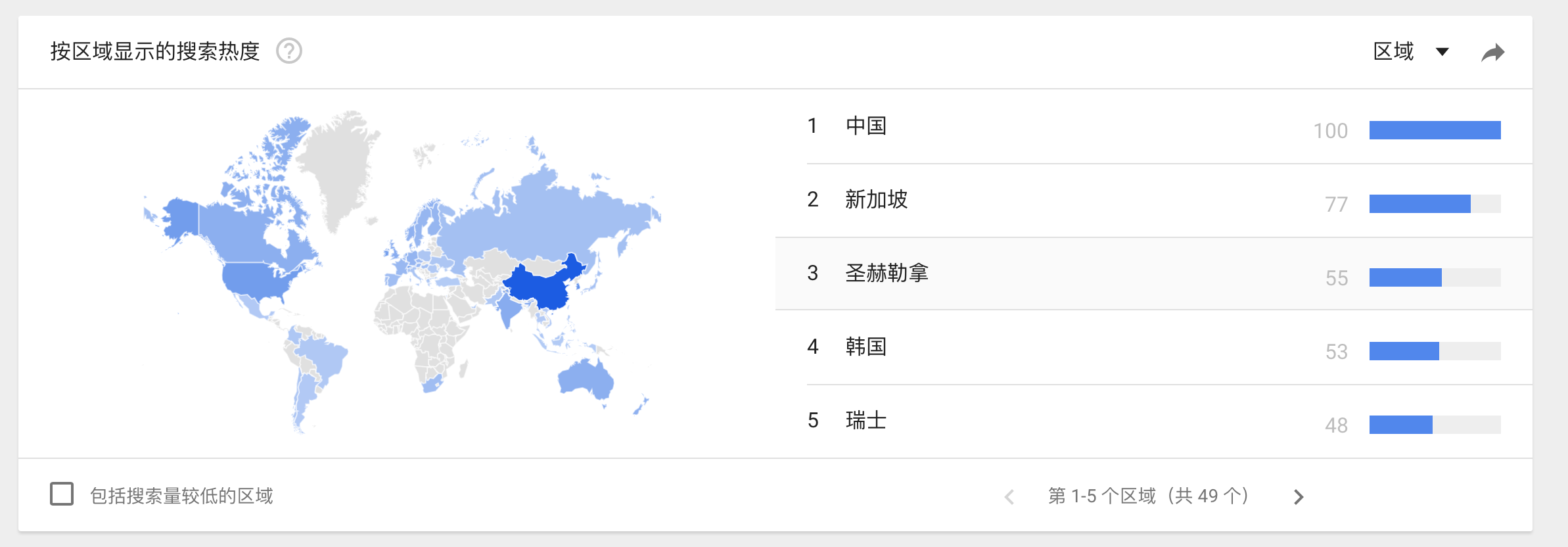
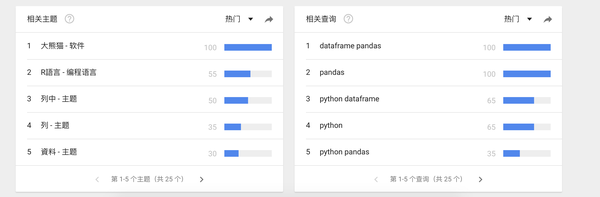
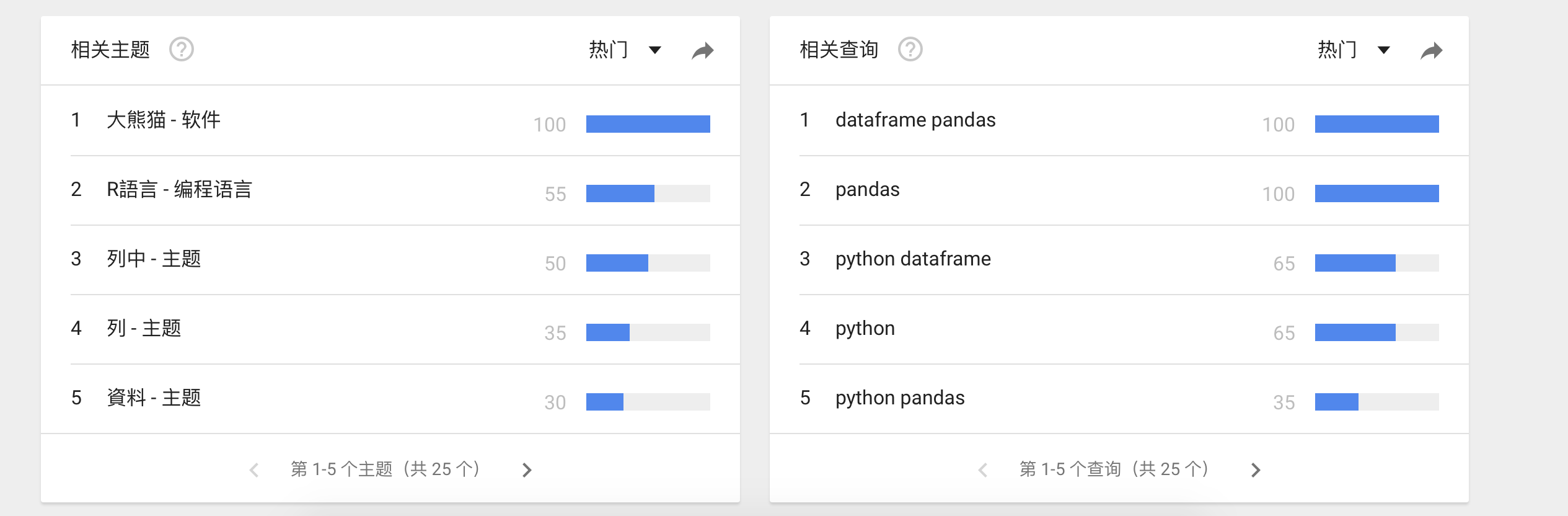
这些图是Google trends上面的趋势图,我们看到dataframe的搜索量是逐年增长,并且增长速度不慢,可以说还挺快的。以中国搜索最多,当然这或许和中国人口有关系,anyhow,dataframe正处于用户量快速增长,关注度不断提升的状态。就是说很火啊!这也是了解和学习它的一个重要原因!
Dataframe不是spark sql提出的,而是早期在R、pandas就已经有了的。
1、Spark RDD API 对比 MapReduce API
注:spark诞生之初很重要的目标就是给大数据生态圈提供基于通用语言的而且是简单易用的API,这个通用语言就包括java、scala、python、R。那么spark原来的RDD API它是通过函数式编程的模式可以把大数据当中的一些数据给他转换成分布式的数据集,RDD再进行编程。我们通过wordcount的案例对比就知道了,如果使用Hadoop的mapreduce来实现的话,它的代码量是非常多的,但是使用spark来处理代码量就大大的减少了。但是不管你代码量多或者少,你如果想要试用spark的RDD或者是mapreduce的API来进行编程的话,你势必要学习Scala、python、java语言,那么这个使用的成本以及门槛就会很高了。对于一般不懂开发的想要使用spark是比较困难的。
2、R/Pandas
注:在R和Pandas里面是有DataFrame这么一说,而且你像R语言是非常适合做一些数据统计和分析的一些操作,虽然这些年已经被python追平,但是不可否认R语言依然在数据圈占有着一席之地。但是有一点,这些语言的局限性非常的强,他仅仅能够支持单机的处理,随着互联网的快速发展,单机处理的日志、数据必然是很有限的,而且现在的日志/数据量是越来越大,随着spark的不断壮大,希望拥有更广泛的受众全体能够利用spark进行分布式的处理,当然这并不仅仅限与工程师,那么这个时候,在spark里面就出现了DataFrame的API,
这个API其实就是从R和Pandas里面借鉴过来的。
No.2 DataFrame简述
1、首先我们依然是看官方文档。
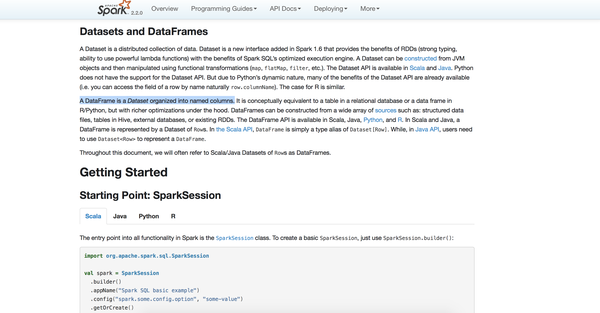
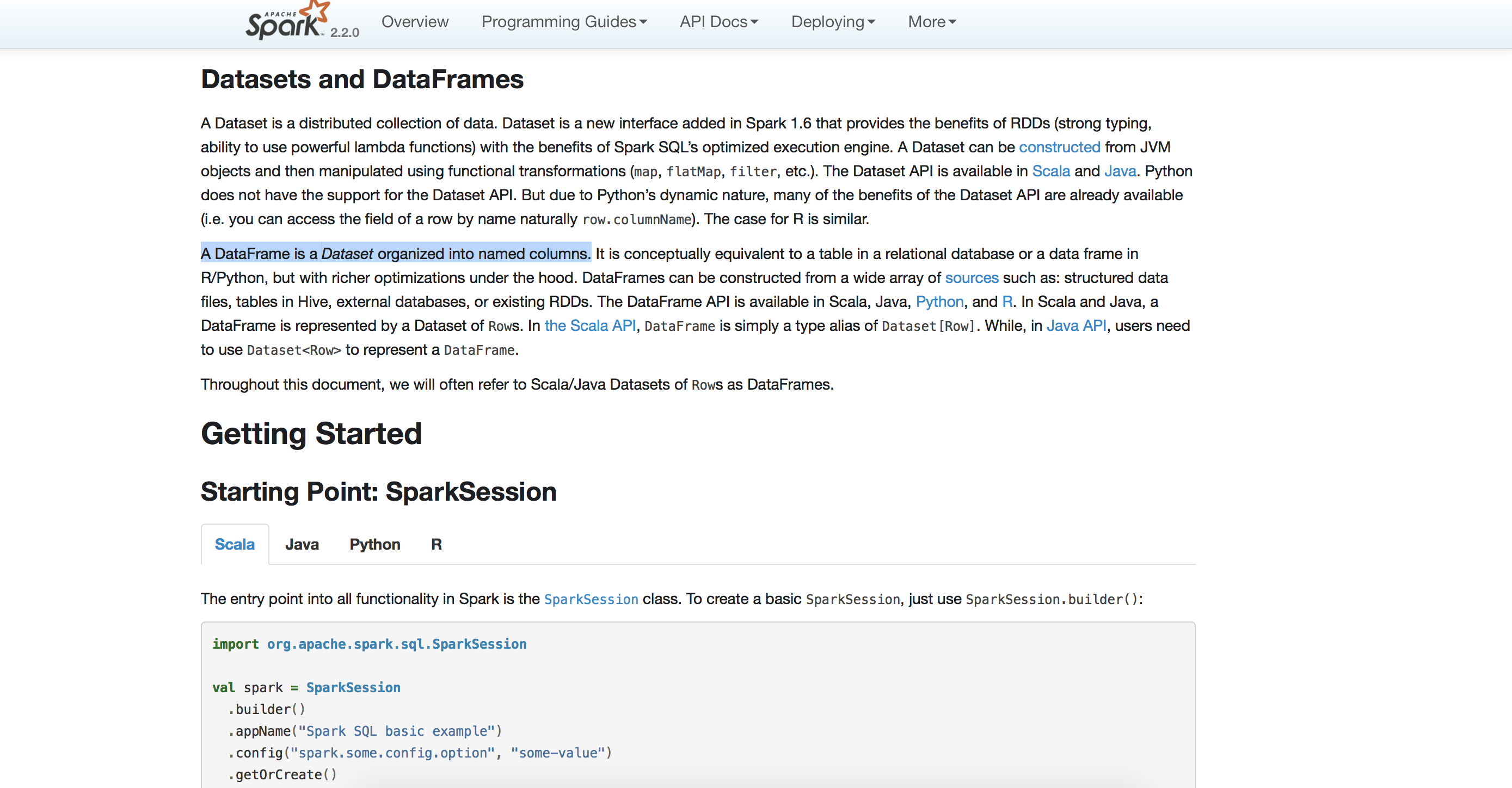
这里面有一句话非常重要:
A DataFrame is a Dataset organized into named columns.
DataFrame它是一个Dataset,这是什么意思?首先什么是Dataset,继续看文档。
上面一开始他介绍了:A Dataset is a distributed collection of data.
意思是说Dataset是一个分布式的数据集,那么DataFrame它是一个Dataset这个毋庸置疑,也就是说这个DataFrame它是一个分布式数据集,并且这个分布式数据集是怎么组织的?上面那句话就说了,他会被按照列进行组织,并且这个列是被取了一个名称的。
其实意思就是说:以列的形式构成的分布式数据集。
那么这个列,肯定会让人想到表,那么这个列就涉及到列名、列的类型以及列的值。
这个分布式的数据集是以列的形式构成的,肯定按照列赋予不同的名称。其实可以举一个简单的例子:
比如一张表
employees
id:int
name:stringh
city:string
我们看这张表是不是以列的形式构成的?以id name city这个列构成的分布式的数据集,你可以把一大张表看成一个数据集,分布式数据集就涉及到多个节点。
我们再往下看:
It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources such as: structured data files, tables in Hive, external databases, or existing RDDs. The DataFrame API is available in Scala, Java, Python, and R. In Scala and Java, a DataFrame is represented by a Dataset of Rows.
在概念层面你可以理解成是一个表,是关系型数据库里面的一张表,你可以给他等价起来理解。或者说他是R语言活着python语言里面的一个叫dataframe的一个概念,因为我们sparksql的dataframe的概念就是从这个语言里面转换过来的,非常类似的,但是呢在底层dataframe做了更多的优化,那么DataFrame能创建,通过哪些方式进行创建呢?可以由结构化的数据进行创建,比如一个文本文件、或者hive当中的一张表,还有一些其他的外部数据源比如mysql里面的数据或是其他关系型数据库里面的数据,也可以是nosql的数据比如hbase,甚至还可以通过已经存在的RDD给他转换过来,当然这就涉及到dataframe和RDD之间的相互操作了,这个后面说。那么DataFrame的API可以使用scala、java、python、R语言进行开发。官网上的对与DataFrame的介绍就说这么多。
2、我么来看一张图:


上面是DataFrame的操作,下面是已经存在的一些单节点的一些框架。对于下面的这些单机的处理框架,当数据量超过GB级别以后处理速度就会变得非常的慢,或者说已经处理不了了,但是对于spark的DataFrame来说,就不存在这个问题,他是分布式的,你可以通过添加机器,添加节点能够很好的对他进行扩展来提高计算能力。
No.3 DataFrame对比RDD
首先我们知道RDD是一个分布式的可以进行并行处理的一个集合,其实DataFrame和RDD非常的类似,他也是一个分布式的数据集,但是DataFrame它提供的更像是一个传统的数据库里面的表,他除了数据之外还能够知道更多的信息,比如说列名、列值和列的属性,这一点就和hive很类似了,而且他也能够支持一些复杂的数据格式。从API应用的角度来说DataFrame提供的API他的层次更高,比RDD编程还要方便,学习的门槛更低,由于R语言和Pandas里面他有DataFrame,所以会这些的哥们操作spark就非常方便了。他根本不需要感知你现在的编程到底是单机的还是分布式的,因为他们完全是一样的,我们来看一张图。
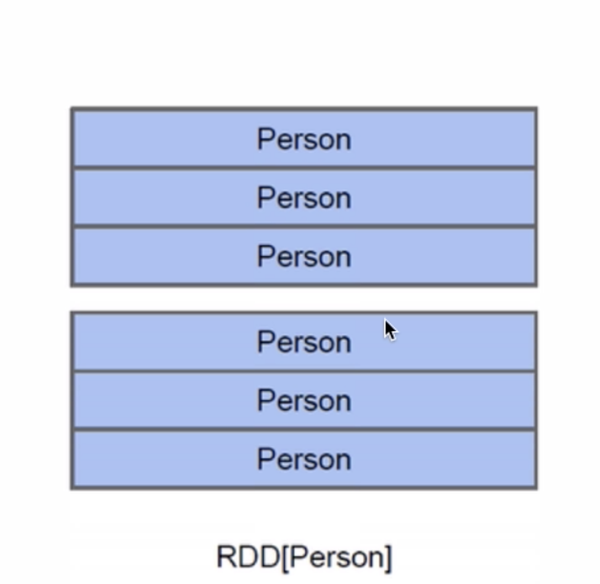
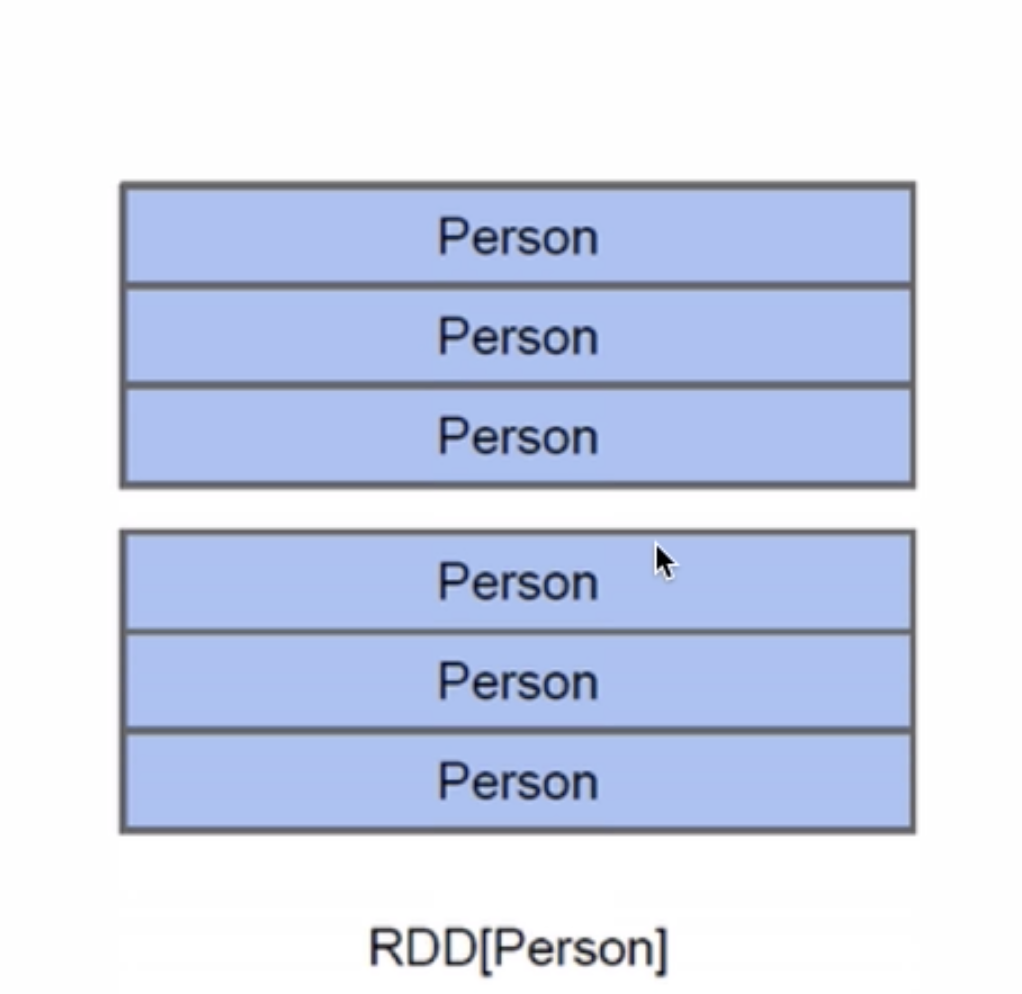
我们先来看RDD,假设RDD里面他支持的是一个person类型,那么每一条记录都相当于一个person,但是person里面到底有什么东西你知道吗?有ID吗?有name?有age?你根本不知道啊。我们再来看一张图。
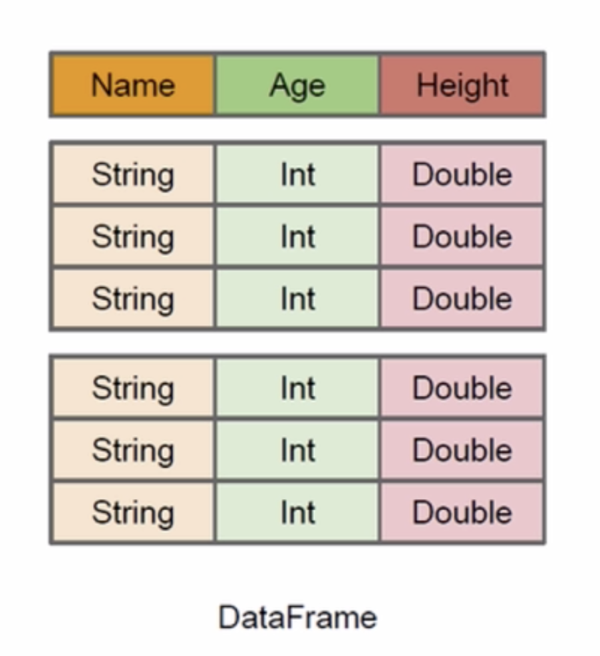
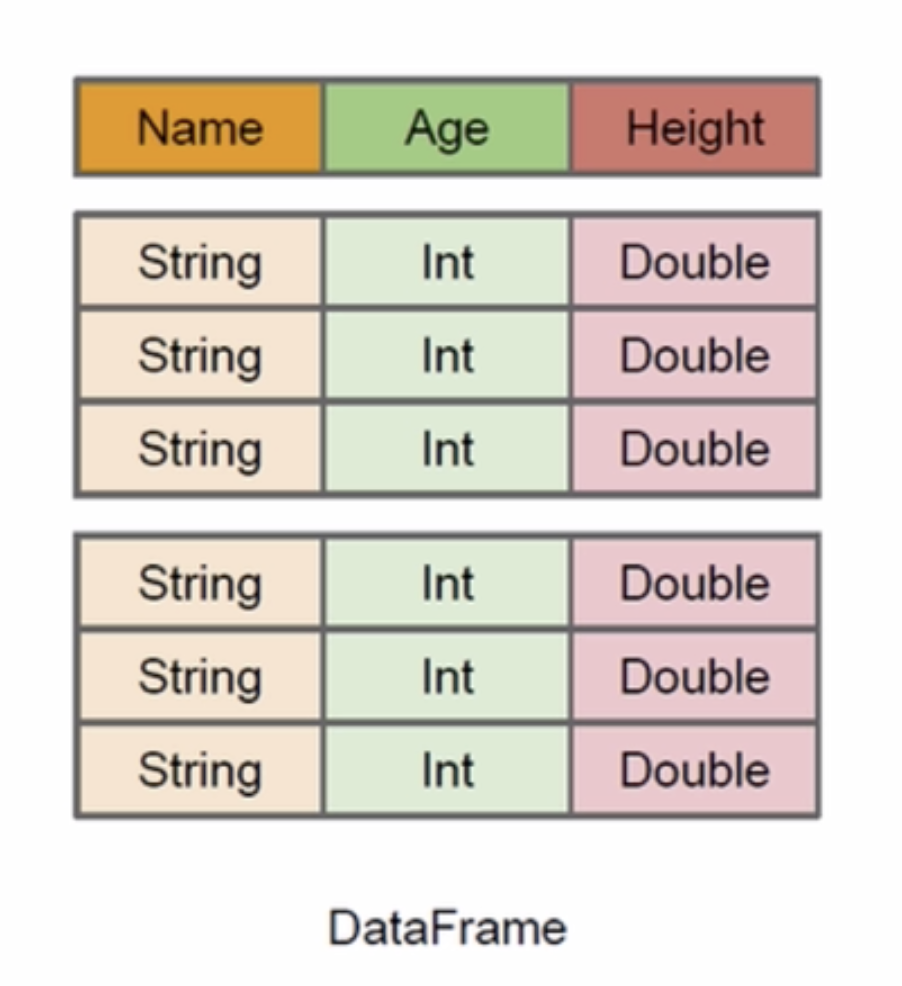
我们来看DataFrame,由于是按照列的形式组织的,我们必然知道他的列名、数据类型以及值。比如图中也是person,你能知道name、age、height。知道这些属性有什么好处呢?
这样的话sparksql执行的时候就能清楚的知道你这个数据集李敏啊有哪些列,每个列的名称和类型他都能够知道,在了解到这些信息以后,sparksql的查询优化器(Catalyst)能够更好的优化,比如你只是想要那么字段,它仅仅只需要把那么那一列取出来就可以了,age和height根本就不需要去读取了,有了这些信息以后在编译的时候能够做更多的优化。
总结:
RDD:
java/scala ==> jvm
python ==> python runtime
使用RDD的方式如果你用java/Scala那你需要运行在jvm上
python就是python runtime
那么你使用不同的语言性能是不一定对等的。
DataFrame:
java/python/scala ==> Logic Plan
不管你使用哪个语言最终都是转换成逻辑执行计划,那么最终的执行效果都是一样的,性能也是一样的。
No.4 DataFrame基本API常用操作
*Create DataFrame
*printSchema
*show
*select
*filter
我们进入IDEA新建一个Scala来操作。
首先操作的代码
关于这个people.json以及后面的people.txt自己创建一个就好了,然后把文件路径复制到代码中
下面是代码
package com.hadoop.spark
import org.apache.spark.sql.SparkSession
/**
* DataFrame API 基本操作
*/
object DataFrameApp {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("DataFrameApp").master("local[2]").getOrCreate()
//把json文件加载成DataFrame
val peopledataframe = spark.read.format("json").load("file:///Users/chandler/Documents/Projects/SparkProjects/people.json")
//输出dataframe对应的Schema信息
peopledataframe.
spark.stop()
}
}
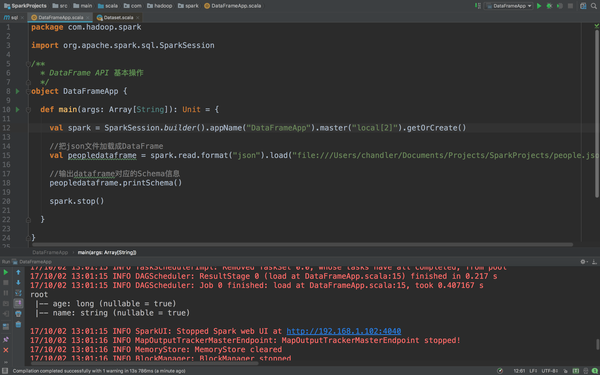
看到没有,它的输出很直观,很友好,我们可以看看printSchema()这个方法的源码介绍。


他说会在控制台consoleprint出来这个schema以一个nice的树的格式,果不其然嘛,我们输出很nice很tree啊!
好了,那如果我们需要里面的内容呢?我们想要得到某些列的数据呢?按照某些条件查询呢?进行分组聚合呢?这些都是可以实现的。上代码
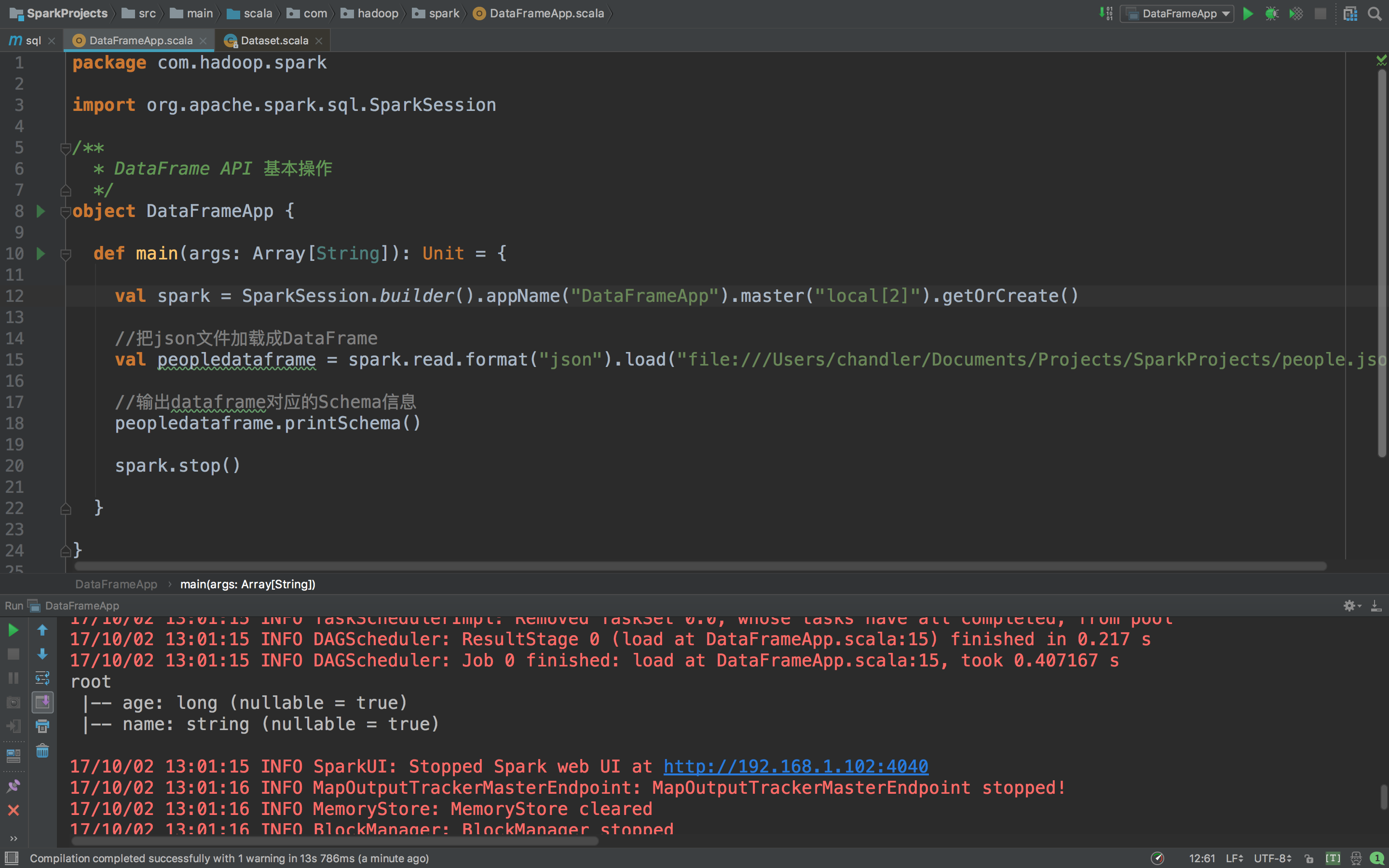
package com.hadoop.spark
import org.apache.spark.sql.SparkSession
/**
* DataFrame API 基本操作
*/
object DataFrameApp {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("DataFrameApp").master("local[2]").getOrCreate()
//把json文件加载成DataFrame
val peopledataframe = spark.read.format("json").load("file:///Users/chandler/Documents/Projects/SparkProjects/people.json")
//输出dataframe对应的Schema信息
peopledataframe.printSchema()
//show的方法来得到我们的内容(注意show方法默认只显示20条数据,要想显示多少可以自己指定,在括号内输入多少条就可以了)
peopledataframe.show()
//只输出name这一列:select name from table
peopledataframe.select("name").show()
//查询某几列数据,并且对列进行计算:select name, age+10 as age2 from table
peopledataframe.select(peopledataframe.col("name"), (peopledataframe.col("age")+10).as("age2")).show()
//查询年龄大于20岁,也就是过滤数据:select * from table where age > 19
peopledataframe.filter(peopledataframe.col("age") > 20).show()
//根据某一列进行分组,然后再进行聚合操作:select age,count(1) from table group by age
peopledataframe.groupBy("age").count().show()
spark.stop()
}
}看看运行结果,查看Schema信息我们刚刚看过来,下面就只放后面的操作结果截图。
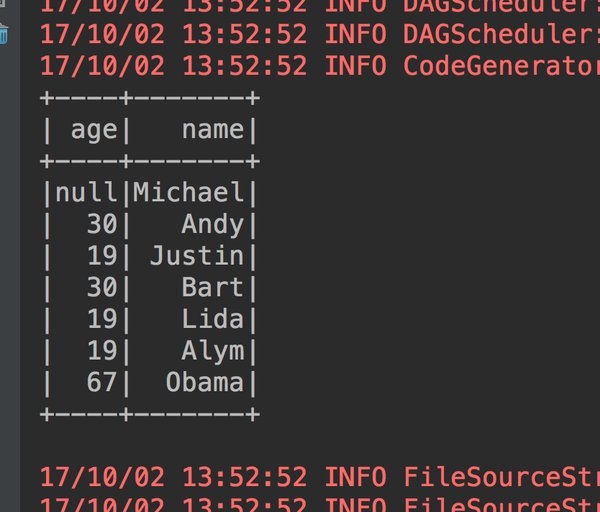
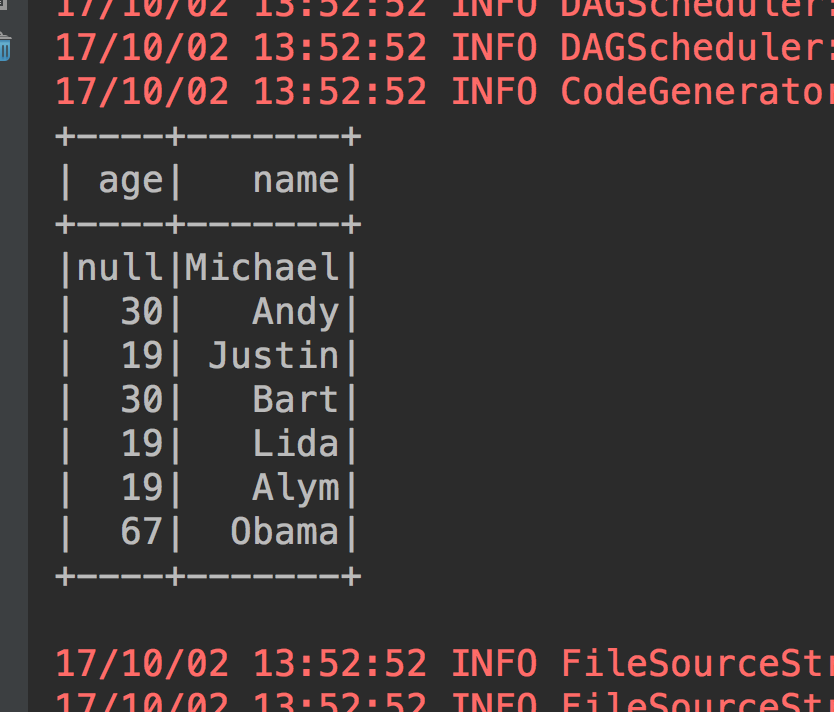
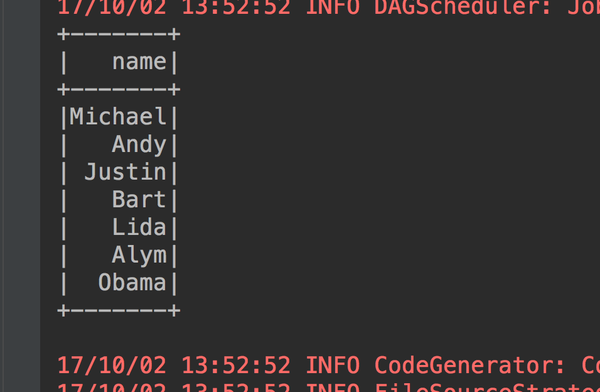
1、show的方法来得到我们的内容(注意show方法默认只显示20条数据,要想显示多少可以自己指定,在括号内输入多少条就可以了)
2、只输出name这一列:select name from table
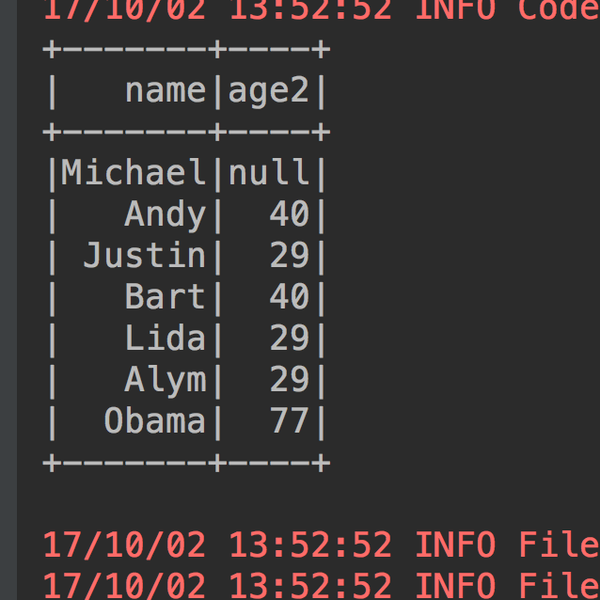
3、查询某几列数据,并且对列进行计算:select name, age+10 as age2 from table
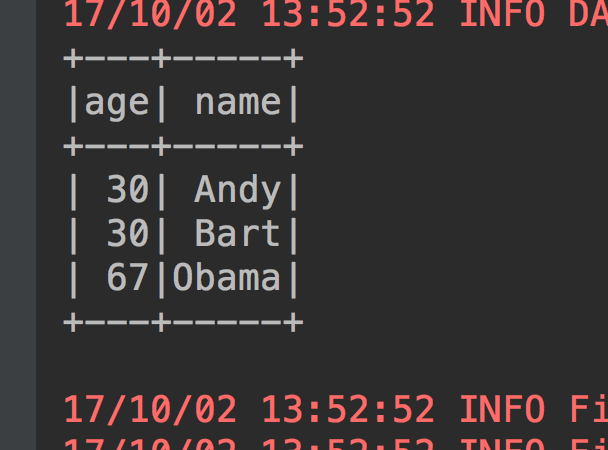
4、查询年龄大于20岁,也就是过滤数据:select * from table where age > 20
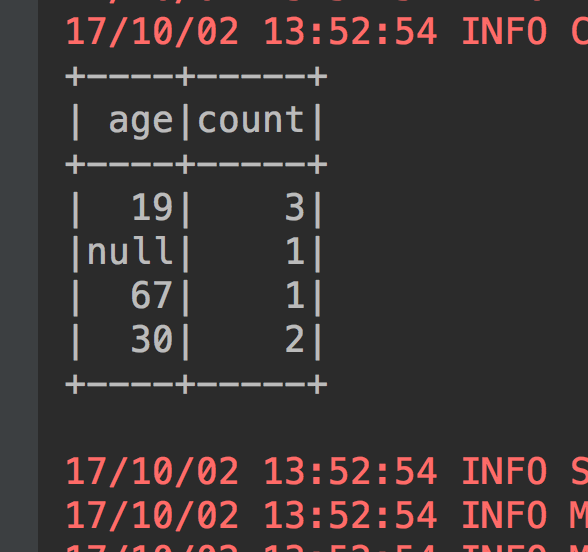
5、根据某一列进行分组,然后再进行聚合操作:select age,count(1) from table group by age
No.5 DataFrame与RDD互操作
1、DataFrame与RDD互操作之一:反射方式
一样的我们进入官网
看到下面d饿截图,其实官网说的很清楚了,可以自己去看一下,这些英文都是很简单的,没有什么晦涩难懂的词汇和长难句什么的,大概查查字典什么的都能看懂!
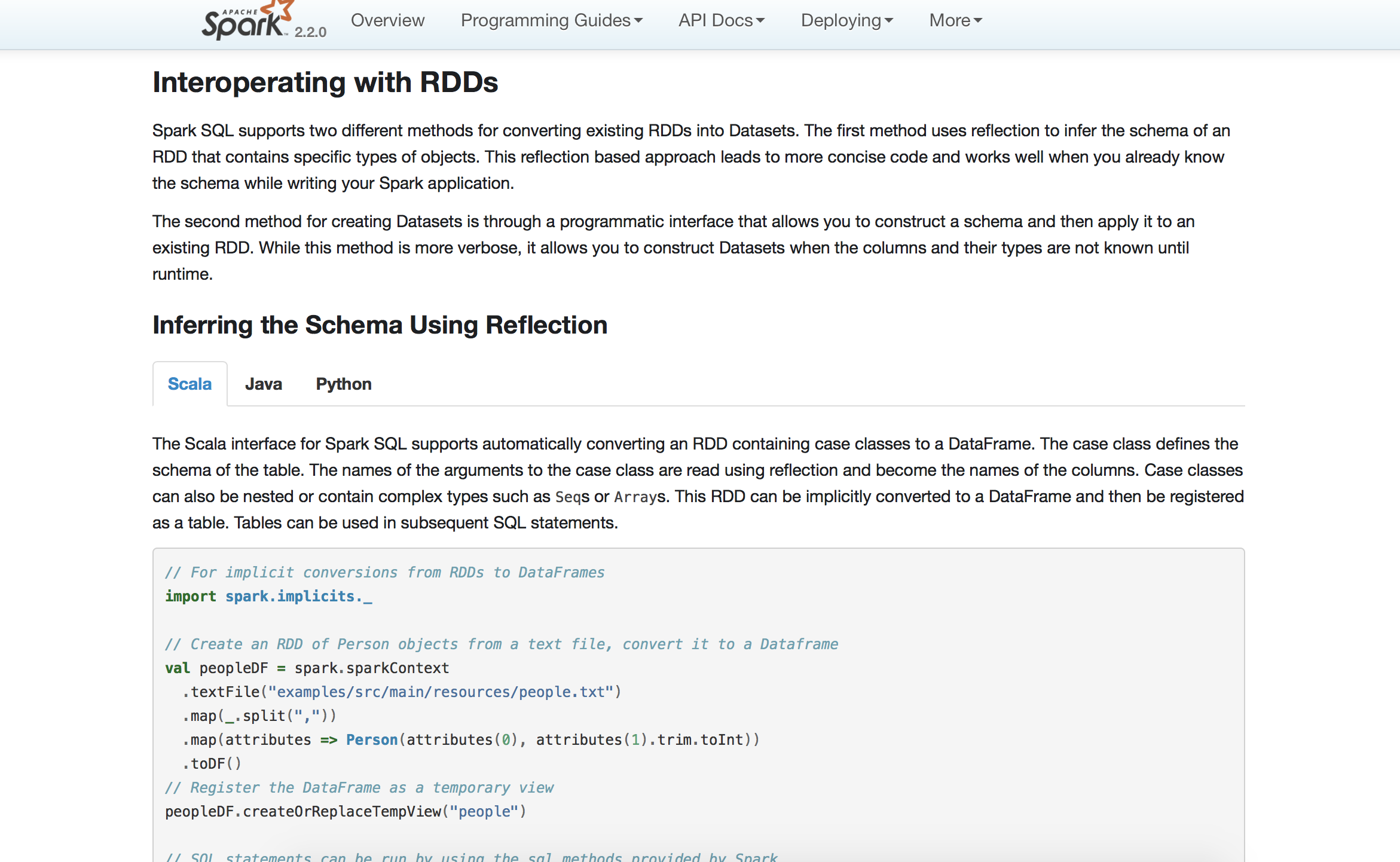
官网提供了一个反射方式的案例。
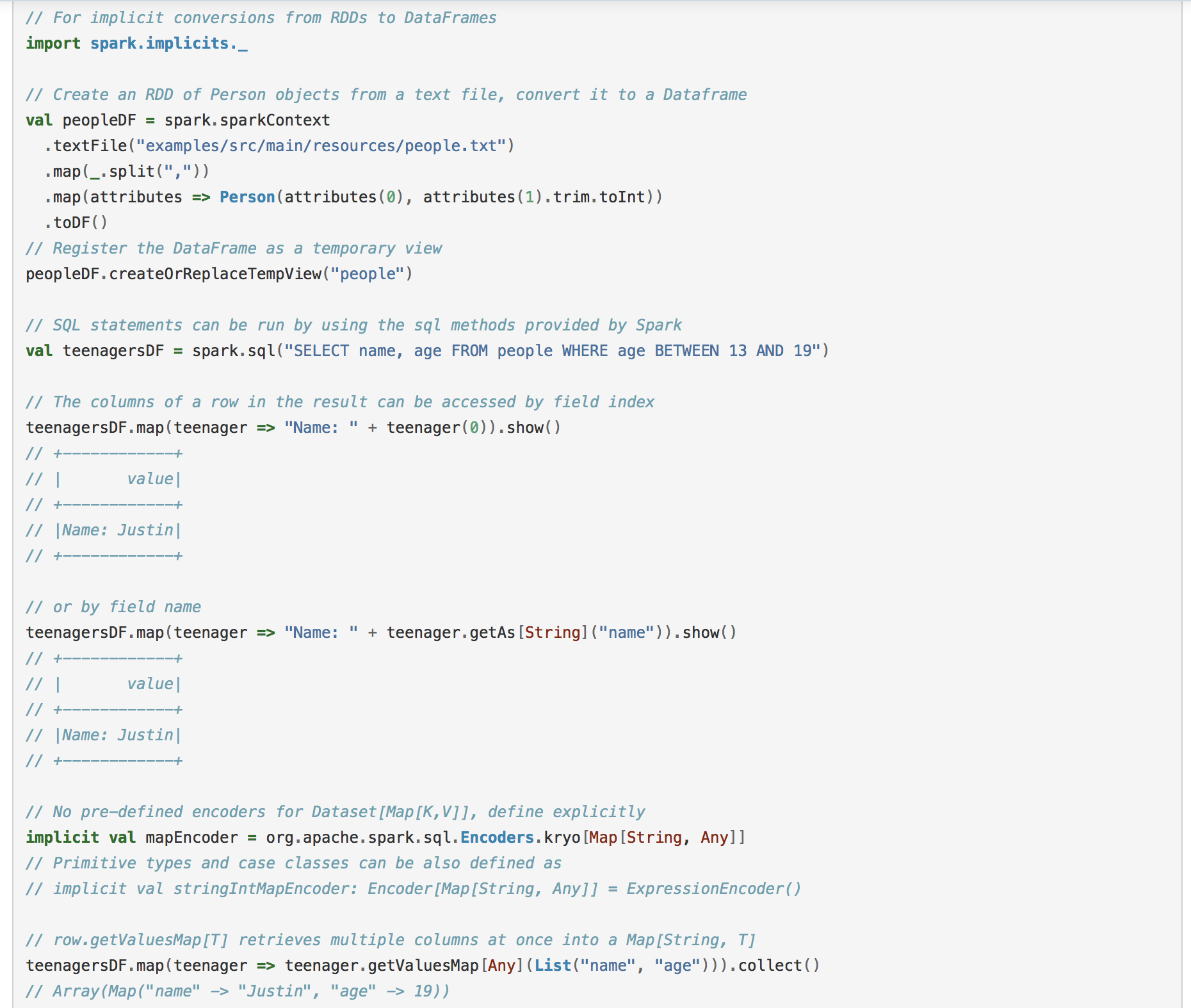
我们根据这个案例来自己操作,进入IDEA新建DataFrameRDDApp。
首先是我们创建的people.txt
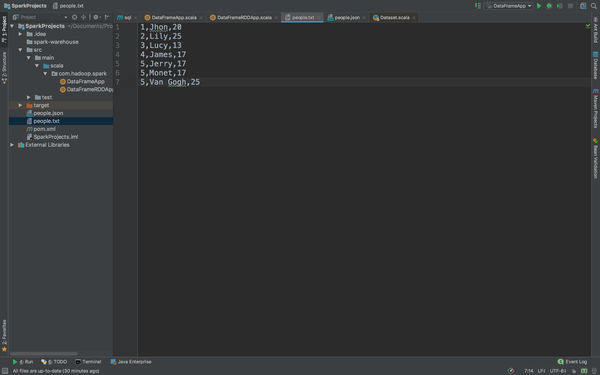
我们需要把他转换成DataFrame。上代码
package com.hadoop.spark
import org.apache.spark.sql.SparkSession
/**
* DataFrame和RDD的互操作
*/
object DataFrameRDDApp {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("DataFrameRDDApp").master("local[2]").getOrCreate()
//RDD ==> DataFrame
val rdd = spark.sparkContext.textFile("file:///Users/chandler/Documents/Projects/SparkProjects/people.txt")
//导入隐式转换
import spark.implicits._
val peopledataframe = rdd.map(_.split(",")).map(line => Info(line(0).toInt, line(1), line(2).toInt)).toDF()
peopledataframe.show()
spark.stop()
}
case class Info(id: Int, name: String, age: Int)
}
查看执行结果
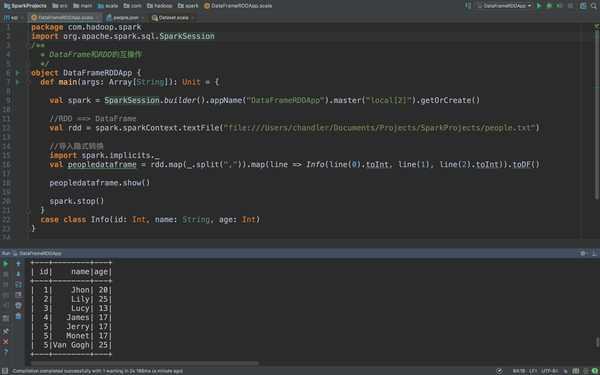
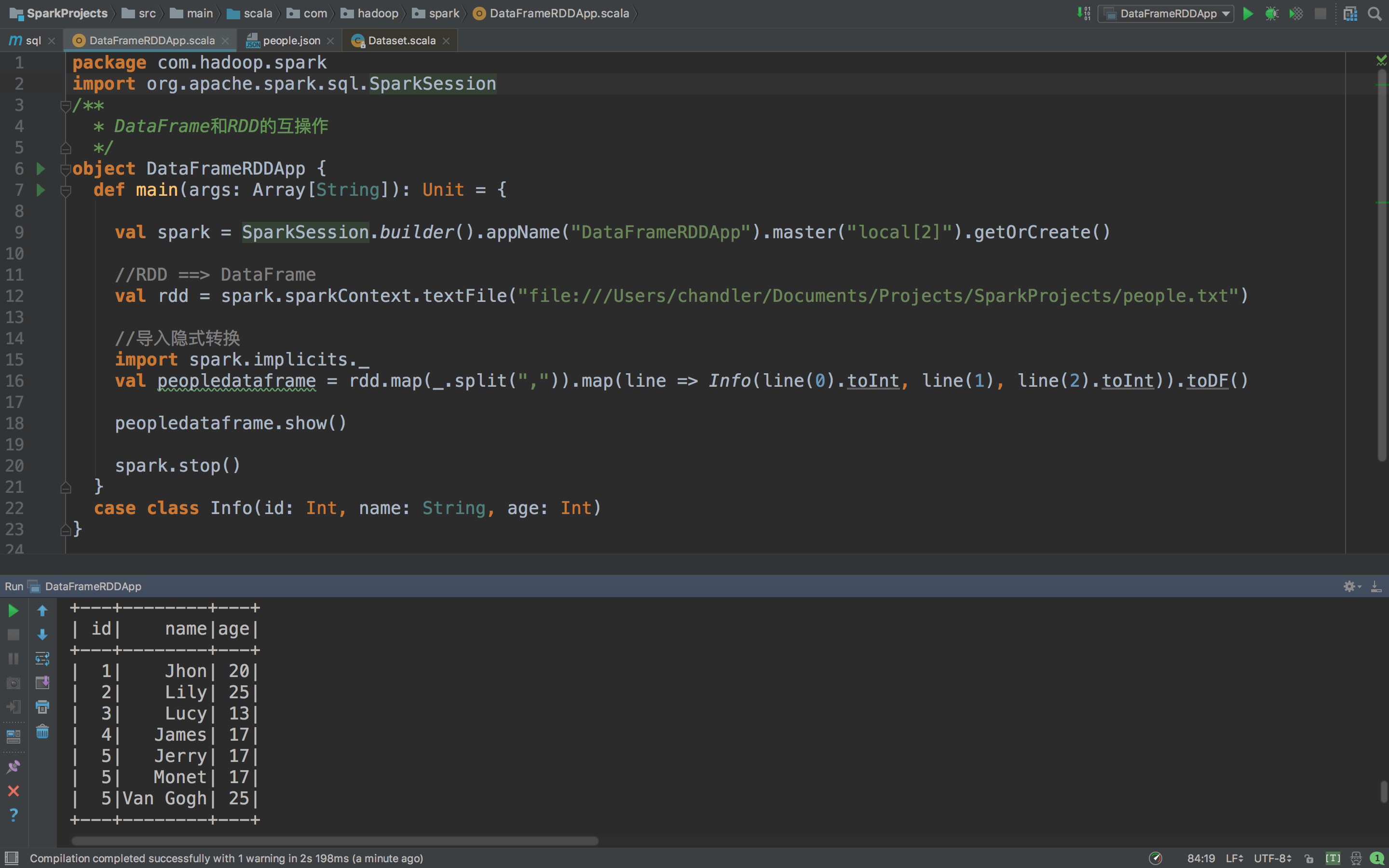
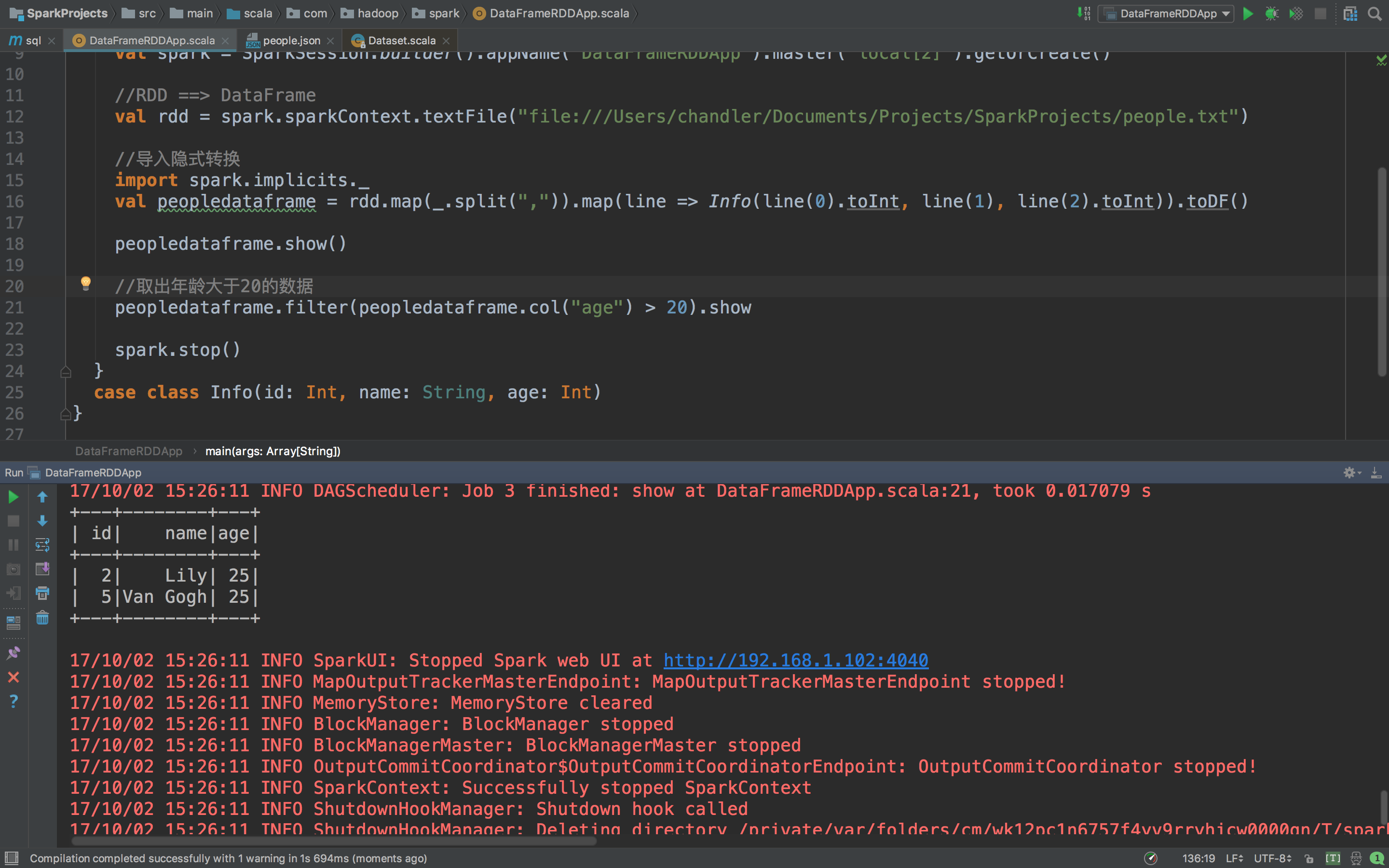
是不是典型的一个DataFrame呢。下面你要操作就简单了,你要数据要过滤筛选什么的都随意啊。比如我们取出年龄大于20的数据,只要一句代码就好了
peopledataframe.filter(peopledataframe.col("age") > 20).show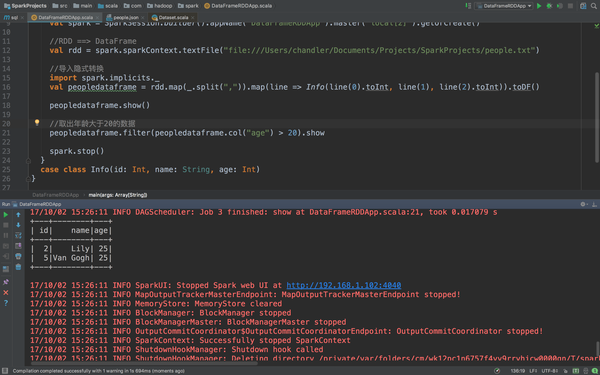
那我们可不可以直接用SQL的方式来查询数据呢?肯定是可以的,上代码
//用sparkSQL的方式来查询数据
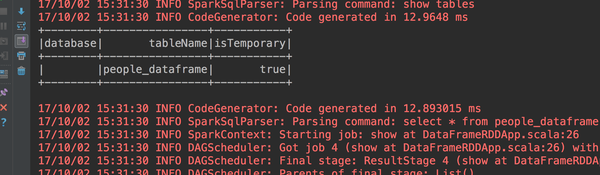
peopledataframe.createOrReplaceTempView("people_dataframe")
spark.sql("show tables").show()
spark.sql("select * from people_dataframe where age > 20").show()首先把peopledataframe创建成一个people_dataframe的表,我们看看是否创建成功。
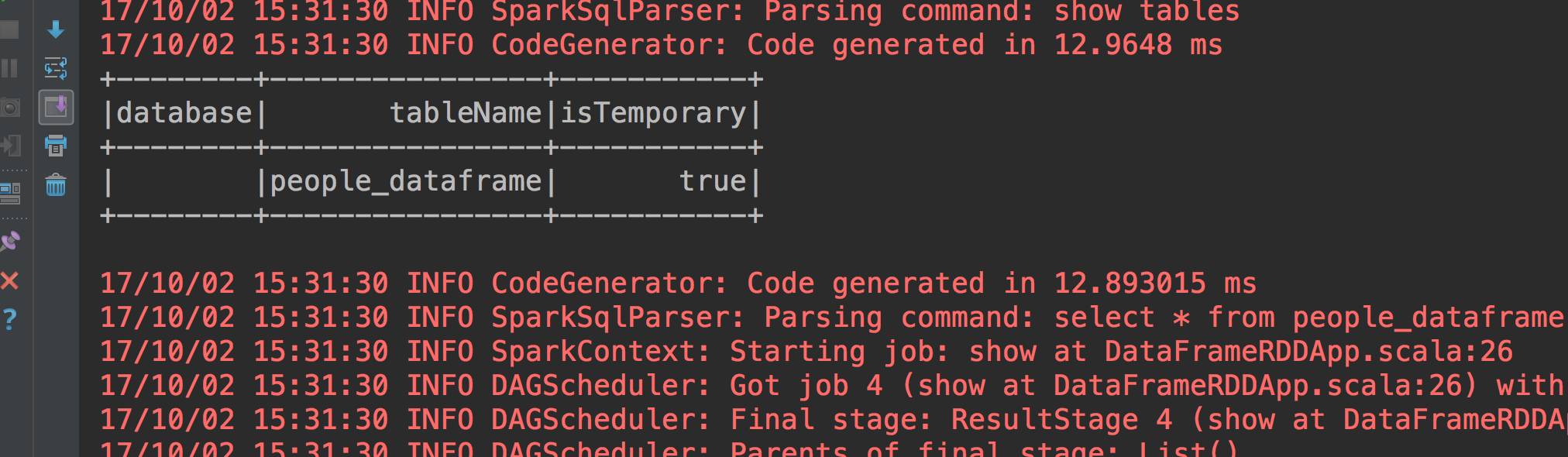
创建好了,那么我们执行SQL语句select * from people_dataframe where age > 20
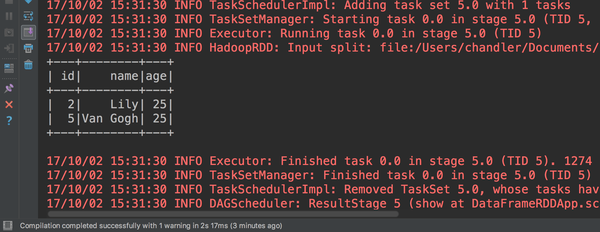
成功执行了看到没。
总结:
*使用反射来推断包含了特定数据类型的RDD的元数据,这个元数据就是个case class
*使用DataFrame API或者SQL方式编程
2、DataFrame与RDD互操作之二:编程方式
依然是官网的介绍
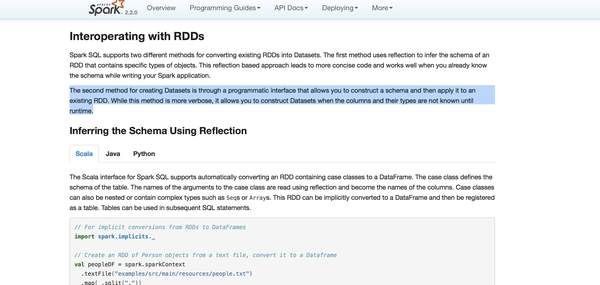
第二种编程方式是比第一种反射方式要复杂的,但是这第二种他允许你构建一个DataFrame/Dataset,什么条件下呢?就是当你事先不知道这些列和他们的类型除非等到运行的时候才知道。我们看看官网的案例
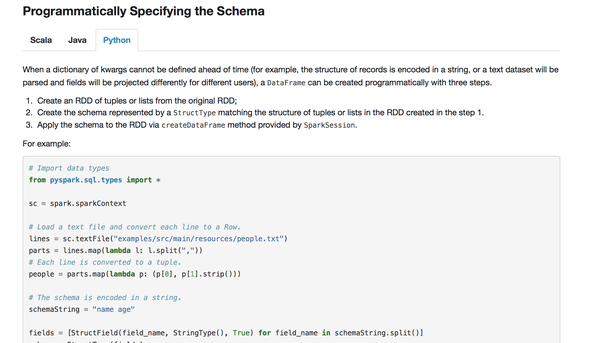
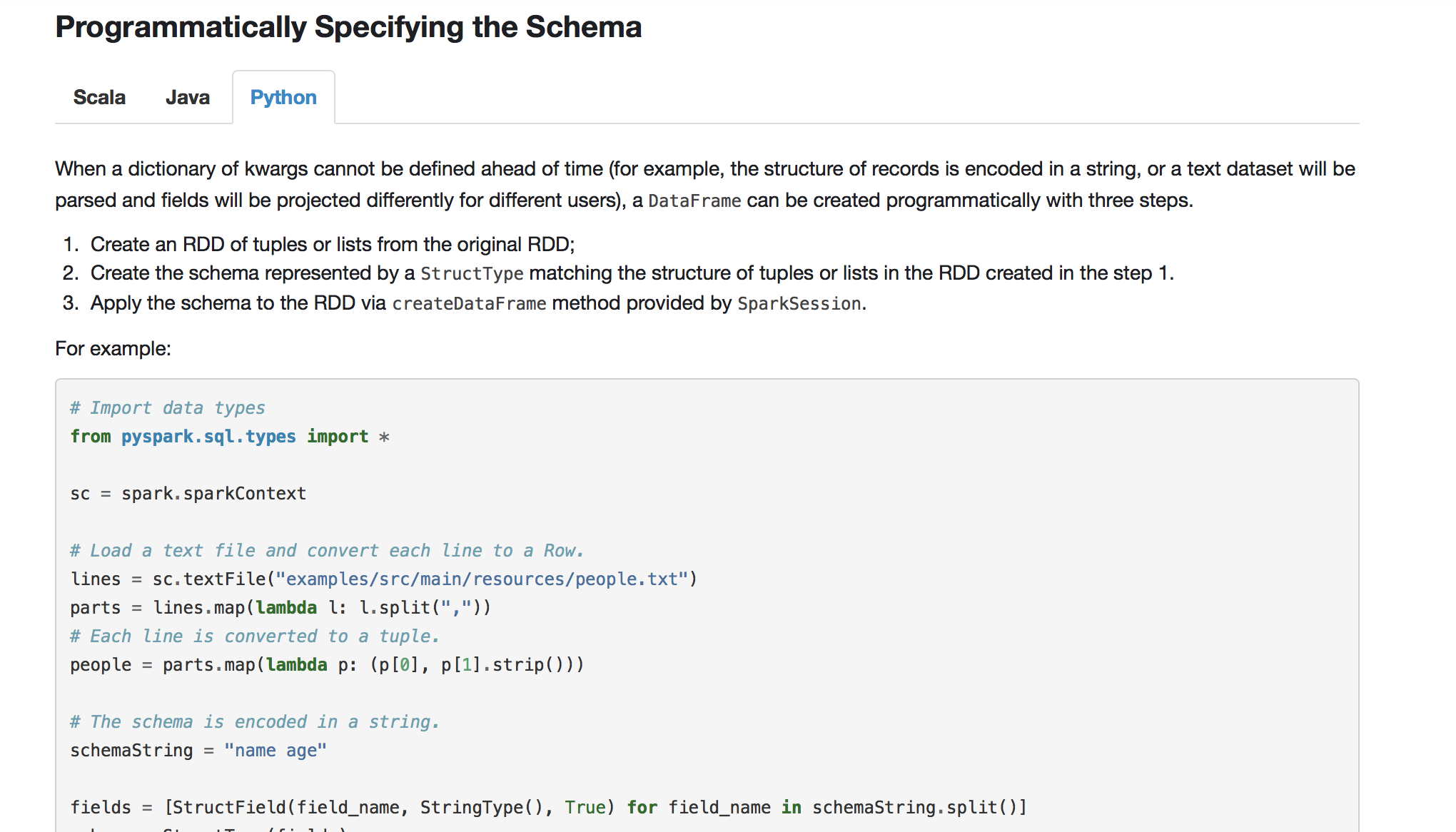
首先官网说了,当我们的case class不能提前定义的时候就需要使用这一种方式了,这个方式我们必须要遵从下面三个步骤:
- 创建一个RDD,我们用RowS来创建
- 定义一个Schema,我们用StructType来定义
- 把这个Schema作用到RDD的RowS上面通过createDataFrame这个方法来实现,当然这个方法是通过SaprkSession来提供的
我们继续进入IDEA进行编程。
def programe(spark: SparkSession): Unit = {
//RDD ==> DataFrame
val rdd = spark.sparkContext.textFile("file:///Users/chandler/Documents/Projects/SparkProjects/people.txt")
//1、创建一个RDD,我们用RowS来创建
val peopleRDD = rdd.map(_.split(",")).map(line => Row(line(0).toInt, line(1), line(2).toInt))
//2、定义一个Schema,我们用StructType来定义
val structType = StructType(Array(StructField("id", IntegerType, true),
StructField("name", StringType, true),
StructField("age", IntegerType, true)))
//3、把这个Schema作用到RDD的RowS上面通过createDataFrame这个方法来实现,当然这个方法是通过SaprkSession来提供的
val peopledataframe = spark.createDataFrame(peopleRDD, structType)
peopledataframe.printSchema()
peopledataframe.show()
}按照上面说的3个步骤进行编程。我们看看执行结果。


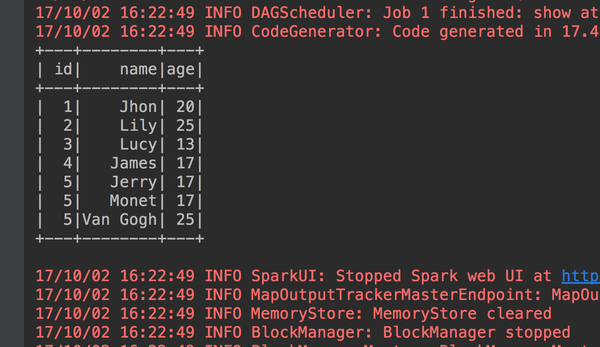
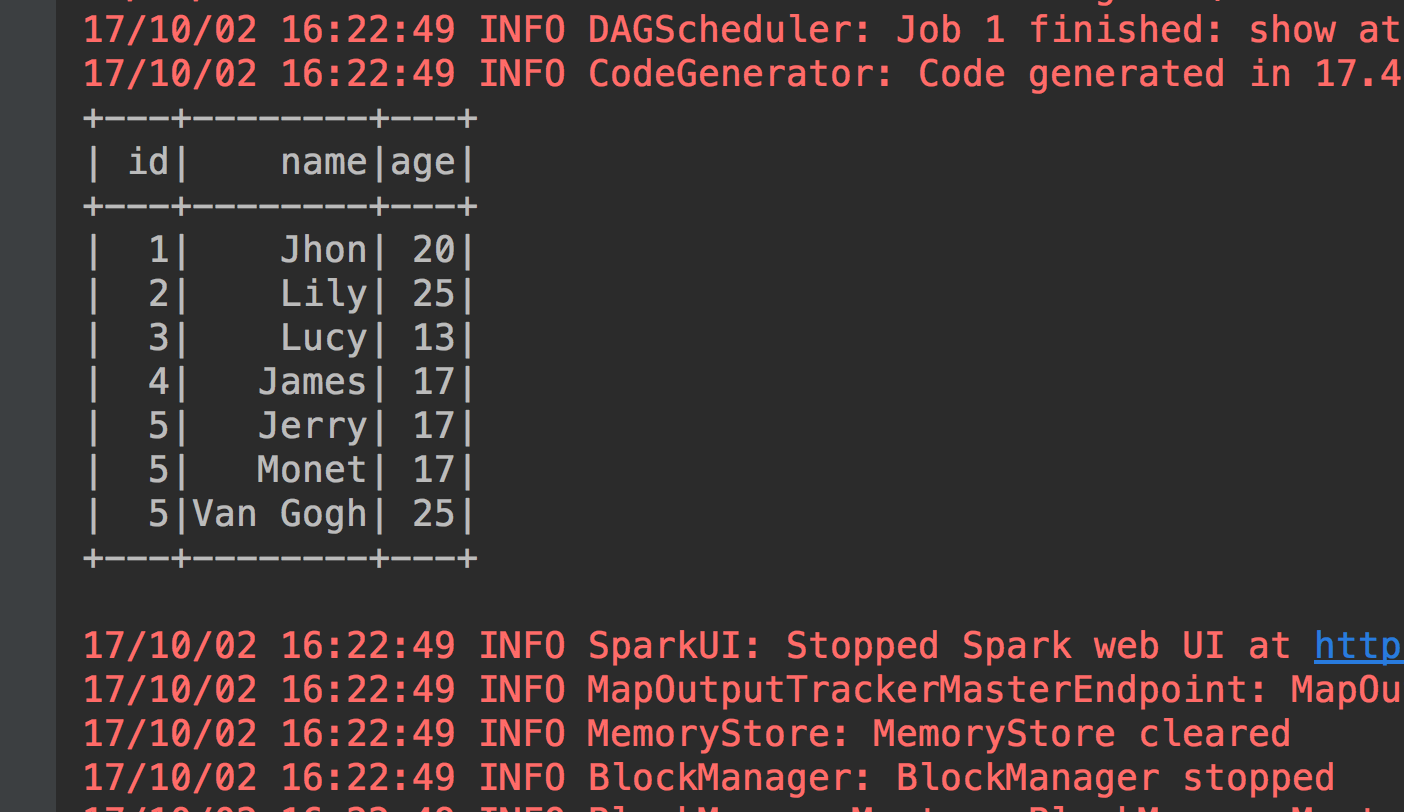
执行没有问题。那些面你想怎么操作,获取数据也好,过滤你想要的数据也好都一样的。
把这两种方法的代码整合起来
package com.hadoop.spark
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
/**
* DataFrame和RDD的互操作
*/
object DataFrameRDDApp {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("DataFrameRDDApp").master("local[2]").getOrCreate()
//通过反射的方式
//peopleReflection(spark)
//通过编程的方式
//programe(spark)
spark.stop()
}
//1、通过编程的方式
def programe(spark: SparkSession): Unit = {
//RDD ==> DataFrame
val rdd = spark.sparkContext.textFile("file:///Users/chandler/Documents/Projects/SparkProjects/people.txt")
//1、创建一个RDD,我们用RowS来创建
val peopleRDD = rdd.map(_.split(",")).map(line => Row(line(0).toInt, line(1), line(2).toInt))
//2、定义一个Schema,我们用StructType来定义
val structType = StructType(Array(StructField("id", IntegerType, true),
StructField("name", StringType, true),
StructField("age", IntegerType, true)))
//3、把这个Schema作用到RDD的RowS上面通过createDataFrame这个方法来实现,当然这个方法是通过SaprkSession来提供的
val peopledataframe = spark.createDataFrame(peopleRDD, structType)
peopledataframe.printSchema()
peopledataframe.show()
}
//2、通过反射的方式
private def peopleReflection(spark: SparkSession) = {
//RDD ==> DataFrame
val rdd = spark.sparkContext.textFile("file:///Users/chandler/Documents/Projects/SparkProjects/people.txt")
//导入隐式转换
import spark.implicits._
val peopledataframe = rdd.map(_.split(",")).map(line => Info(line(0).toInt, line(1), line(2).toInt)).toDF()
peopledataframe.show()
//取出年龄大于20的数据
peopledataframe.filter(peopledataframe.col("age") > 20).show
//用sparkSQL的方式来查询数据
peopledataframe.createOrReplaceTempView("people_dataframe")
spark.sql("show tables").show()
spark.sql("select * from people_dataframe where age > 20").show()
}
case class Info(id: Int, name: String, age: Int)
}
总结:
DataFrame和RDD互操作的两个方式:
1、反射:case class 前提:事先需要知道你的字段、字段类型
2、编程:Row 如果第一种情况不能满足你的要求(事先不知道列)
3、选型:优先考虑第一种
No.6 DataFrame API操作案例
*学生信息统计案例
基于一份学生的信息做一个案例操作,首先我们看这份信息
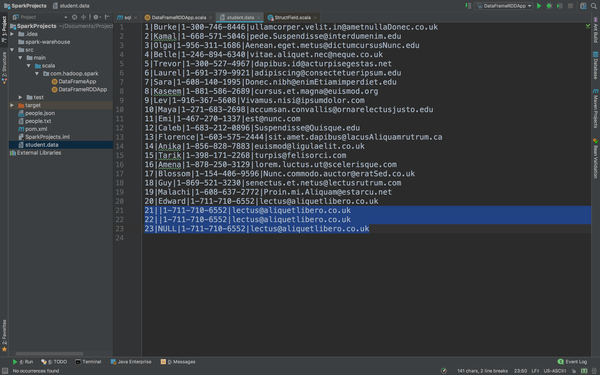
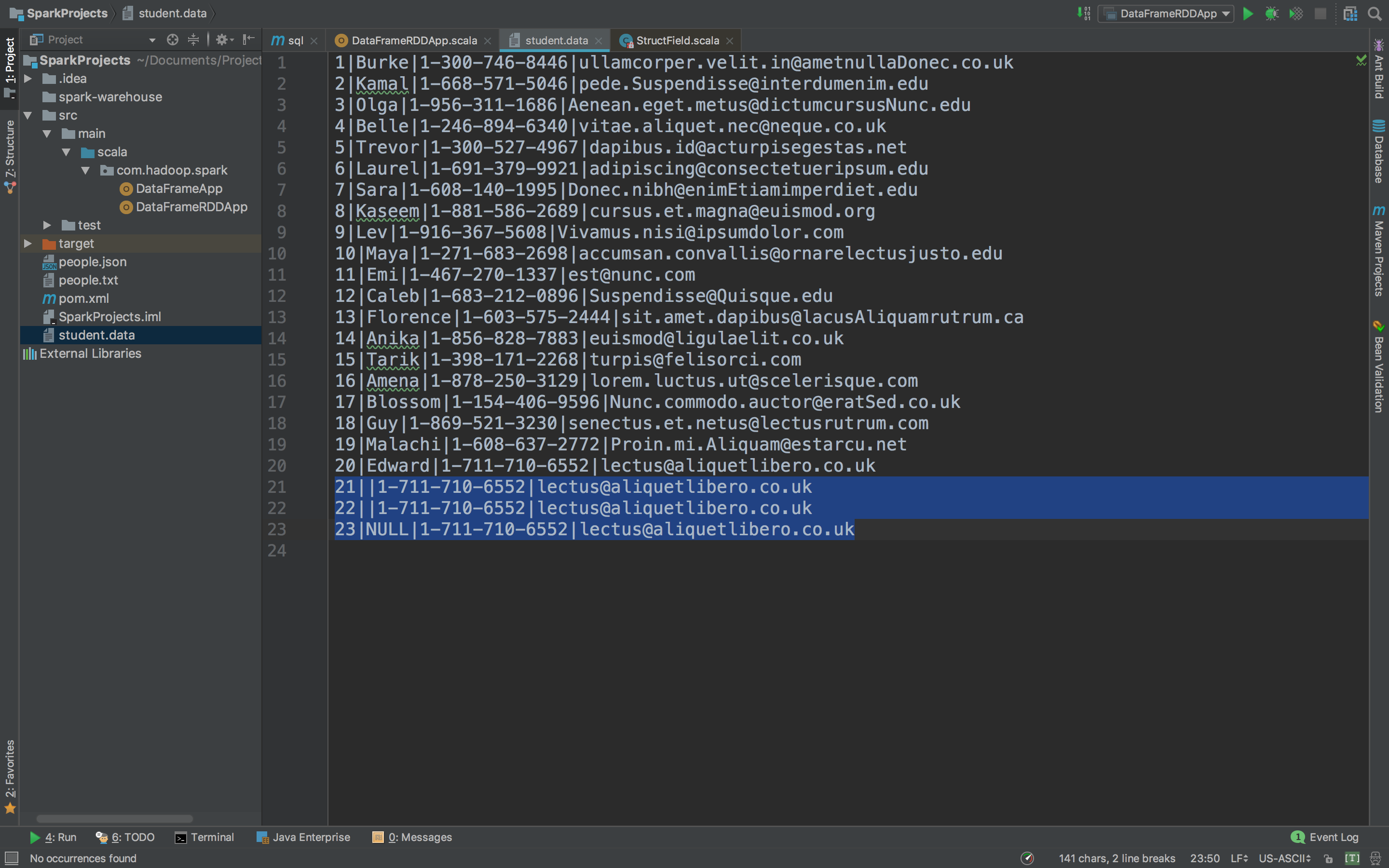
看蓝色标记部分,这个数据是存在缺失的,在操作过程中肯定要把这些有问题并且无法操作的一些数据拿掉。
我们进入IDEA进行编程。当然首先新建一个DataFrameCase。
上代码
package com.hadoop.spark
import org.apache.spark.sql.SparkSession
/**
* DataFrame中的操作(使用第一种反射的方式)
*/
object DataFrameCase {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("DataFrameRDDApp").master("local[2]").getOrCreate()
//RDD ==> DataFrame
val rdd = spark.sparkContext.textFile("file:///Users/chandler/Documents/Projects/SparkProjects/student.data")
//导入隐式转换
import spark.implicits._
val studentdataframe = rdd.map(_.split("\\|")).map(line => Student(line(0).toInt, line(1), line(2), line(3))).toDF()
//显示前23条数据
studentdataframe.show(23, false)
//我们筛选出名字是NULL和没有名字的数据
studentdataframe.filter("name='' or name='NULL'").show(false)
//name以B开头的人
studentdataframe.filter("SUBSTR(name,0,1)='B'").show(false)
//按照名字升序排序
studentdataframe.sort(studentdataframe("name")).show(23, false)
//按照名字倒序排序
studentdataframe.sort(studentdataframe("name").desc).show(23, false)
//如果name完全相同的按照id升序排序(这个数据里面只有两个没有名字的记录完全相同)
studentdataframe.sort("name", "id").show(23, false)
//按照name升序id降序排序
studentdataframe.sort(studentdataframe("name").asc, studentdataframe("id").desc).show(23, false)
//更改列名
studentdataframe.select(studentdataframe("name").as("student_name")).show(23, false)
//进行join操作(作为测试让这个表自己和自己join)
val studentdataframe_test = rdd.map(_.split("\\|")).map(line => Student(line(0).toInt, line(1), line(2), line(3))).toDF()
studentdataframe.join(studentdataframe_test, studentdataframe.col("id") === studentdataframe_test.col("id")).show(23, false)
spark.stop()
}
case class Student(id: Int, name: String, phone: String, email: String)
}
我们看每一个操作的结果
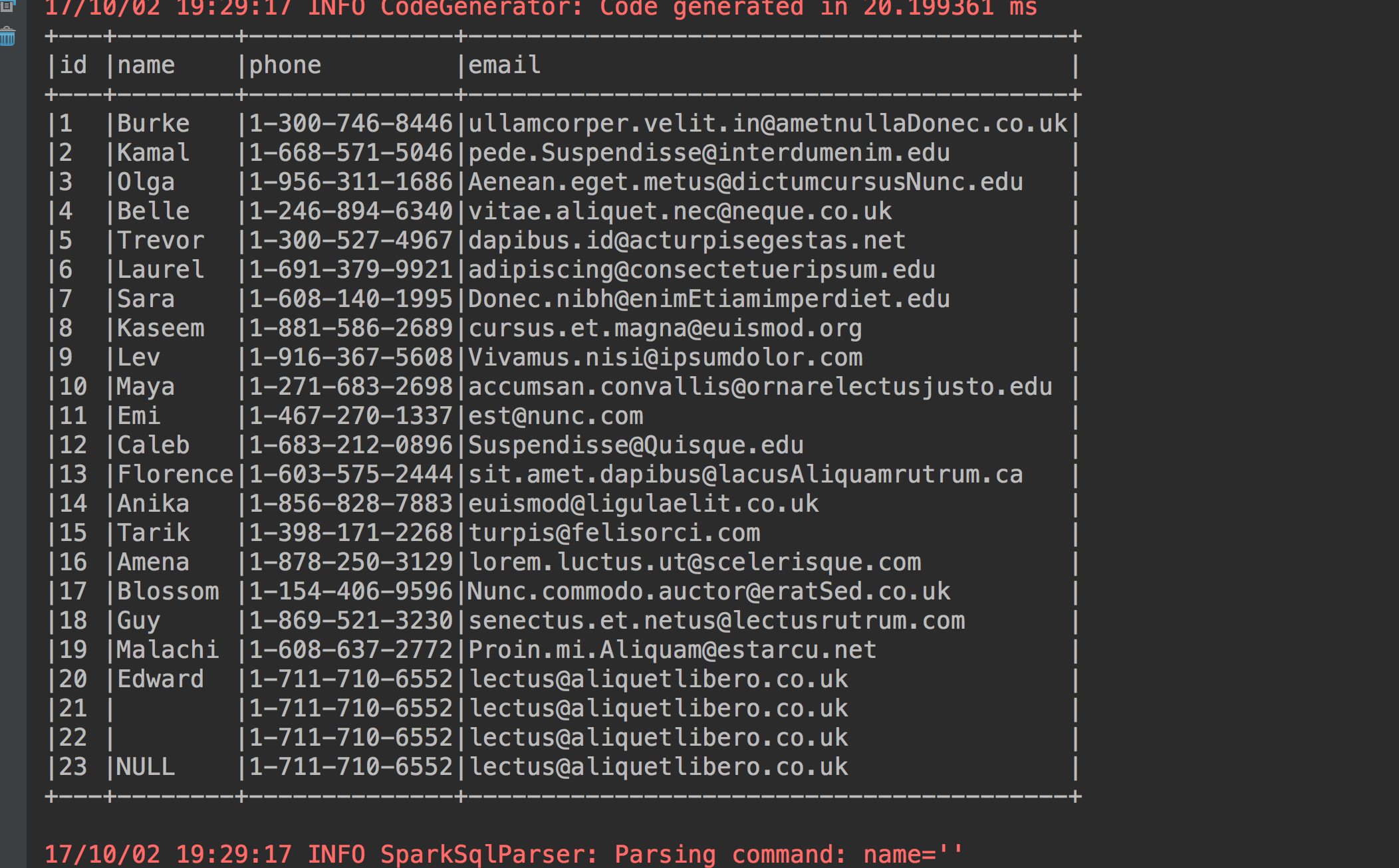
1、显示前23条数据
studentdataframe.show(23, false)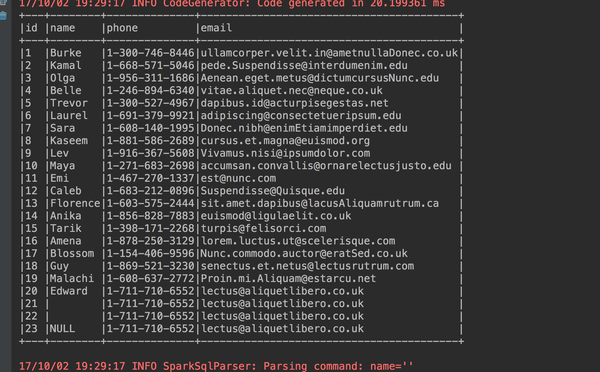
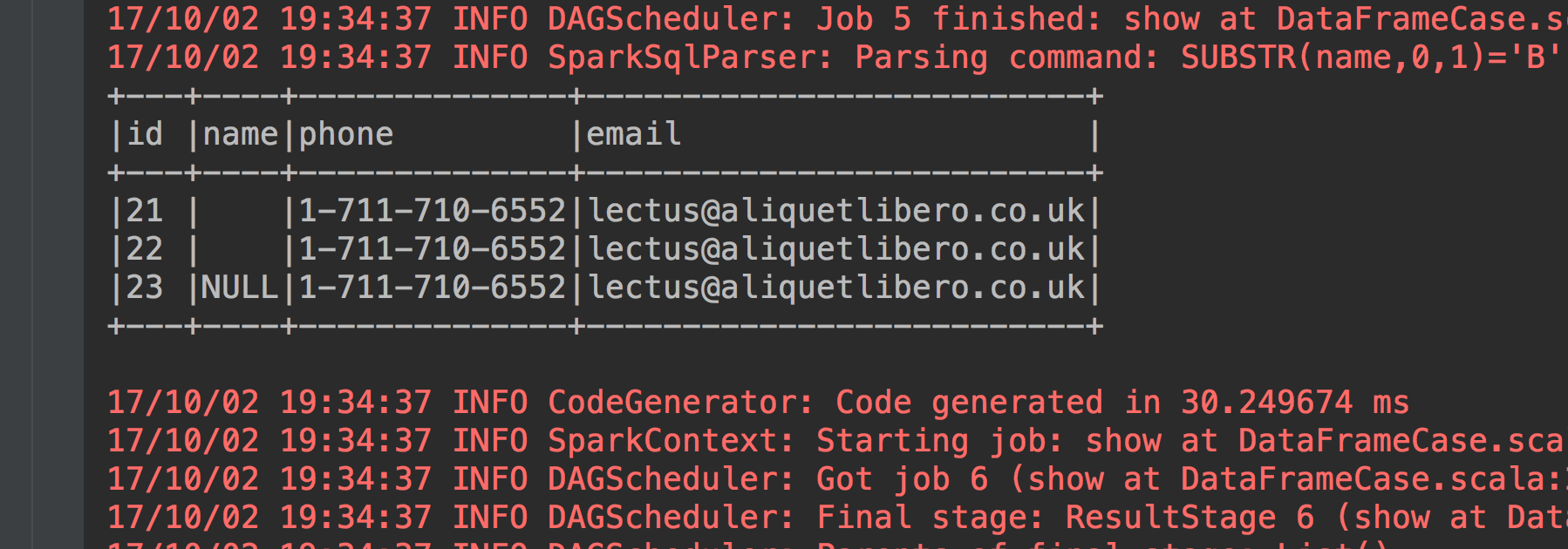
2、我们筛选出名字是NULL和没有名字的数据
studentdataframe.filter("name='' or name='NULL'").show(false)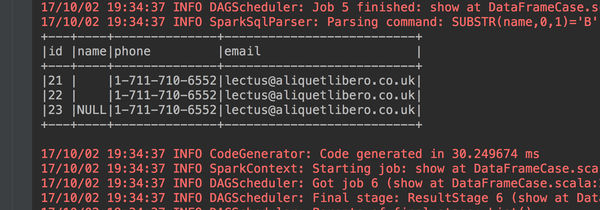
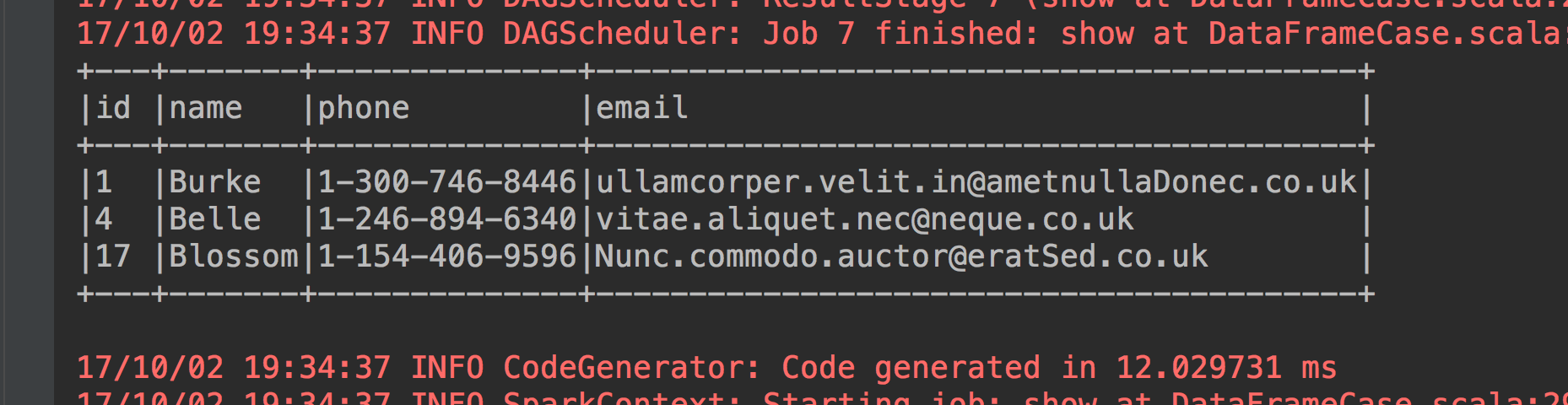
3、name以B开头的人
studentdataframe.filter("SUBSTR(name,0,1)='B'").show(false)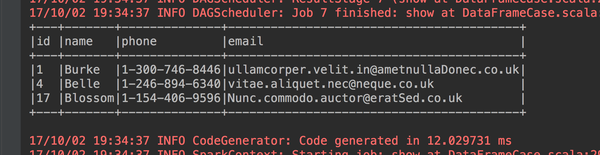
4、按照名字升序排序
studentdataframe.sort(studentdataframe("name")).show(23, false)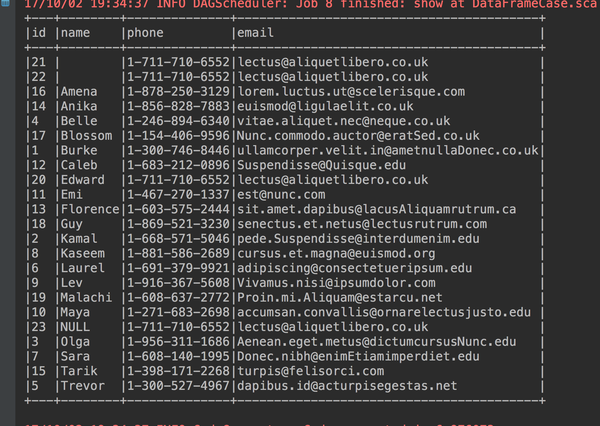
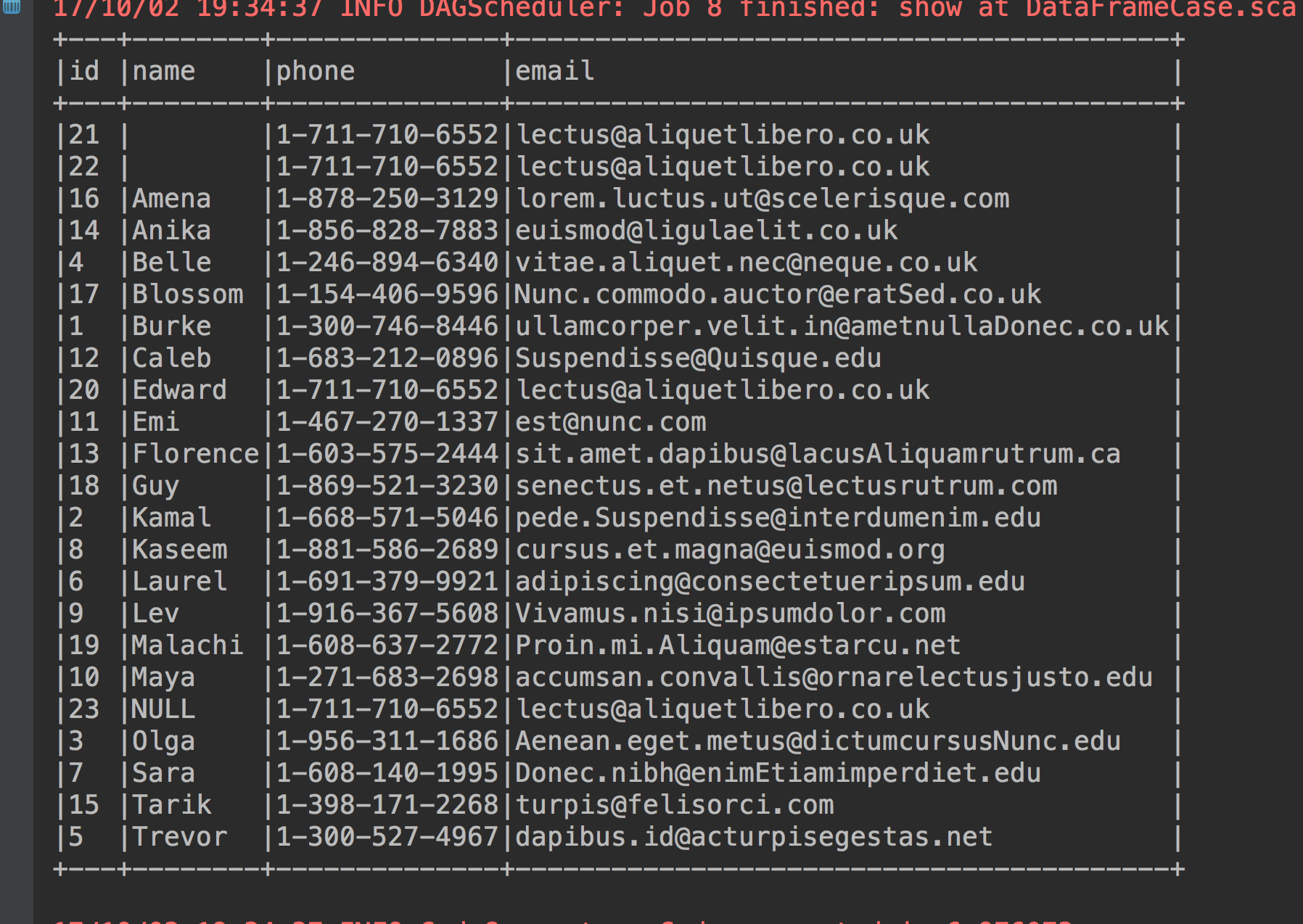
5、按照名字倒序排序
studentdataframe.sort(studentdataframe("name").desc).show(23, false)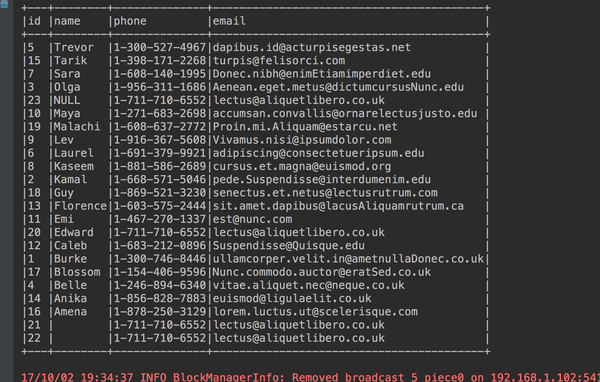
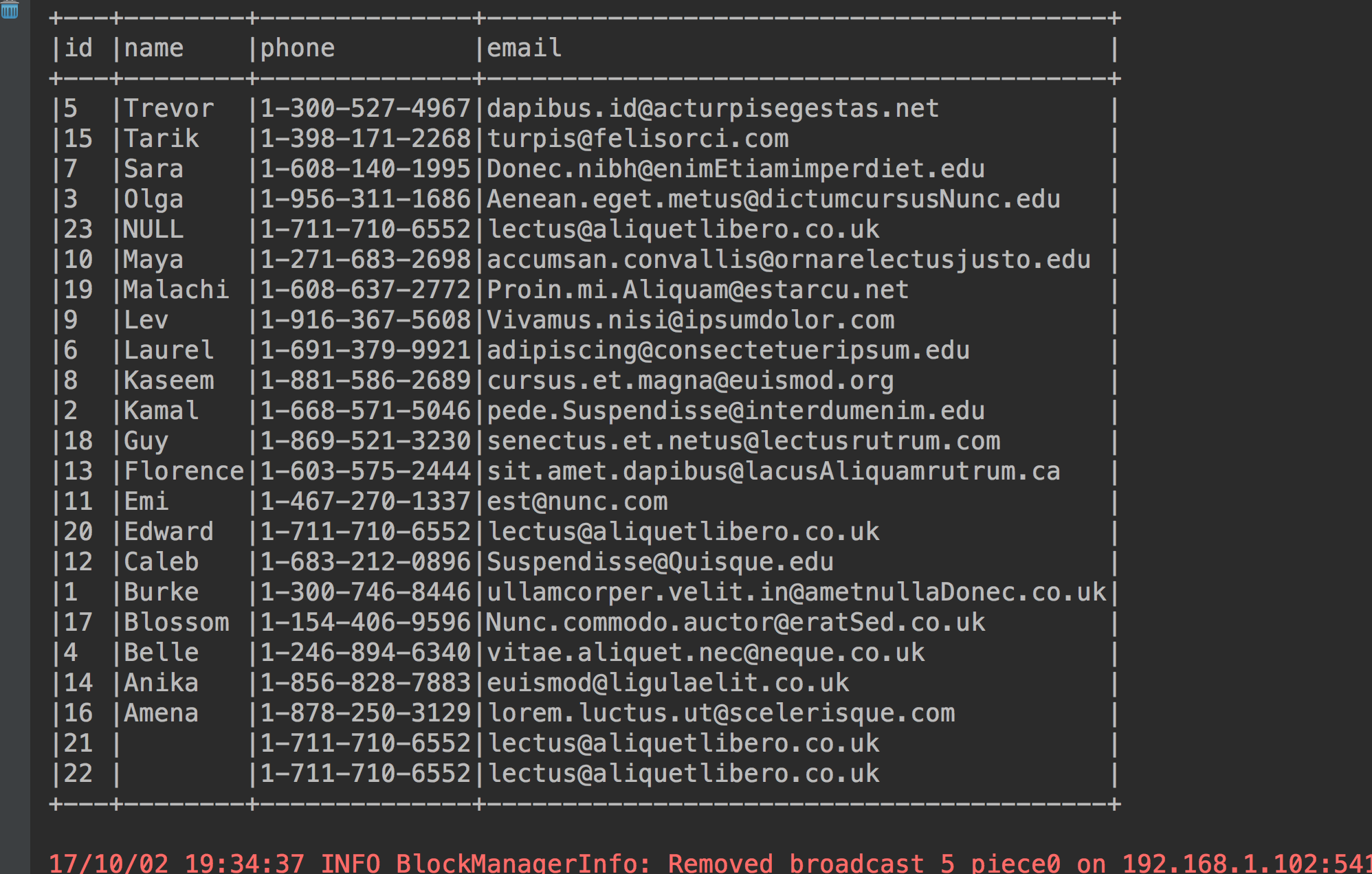
6、如果name完全相同的按照id升序排序(这个数据里面只有两个没有名字的记录完全相同)
studentdataframe.sort("name", "id").show(23, false)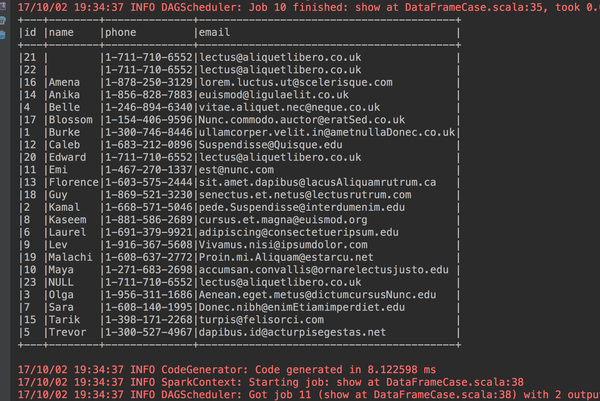
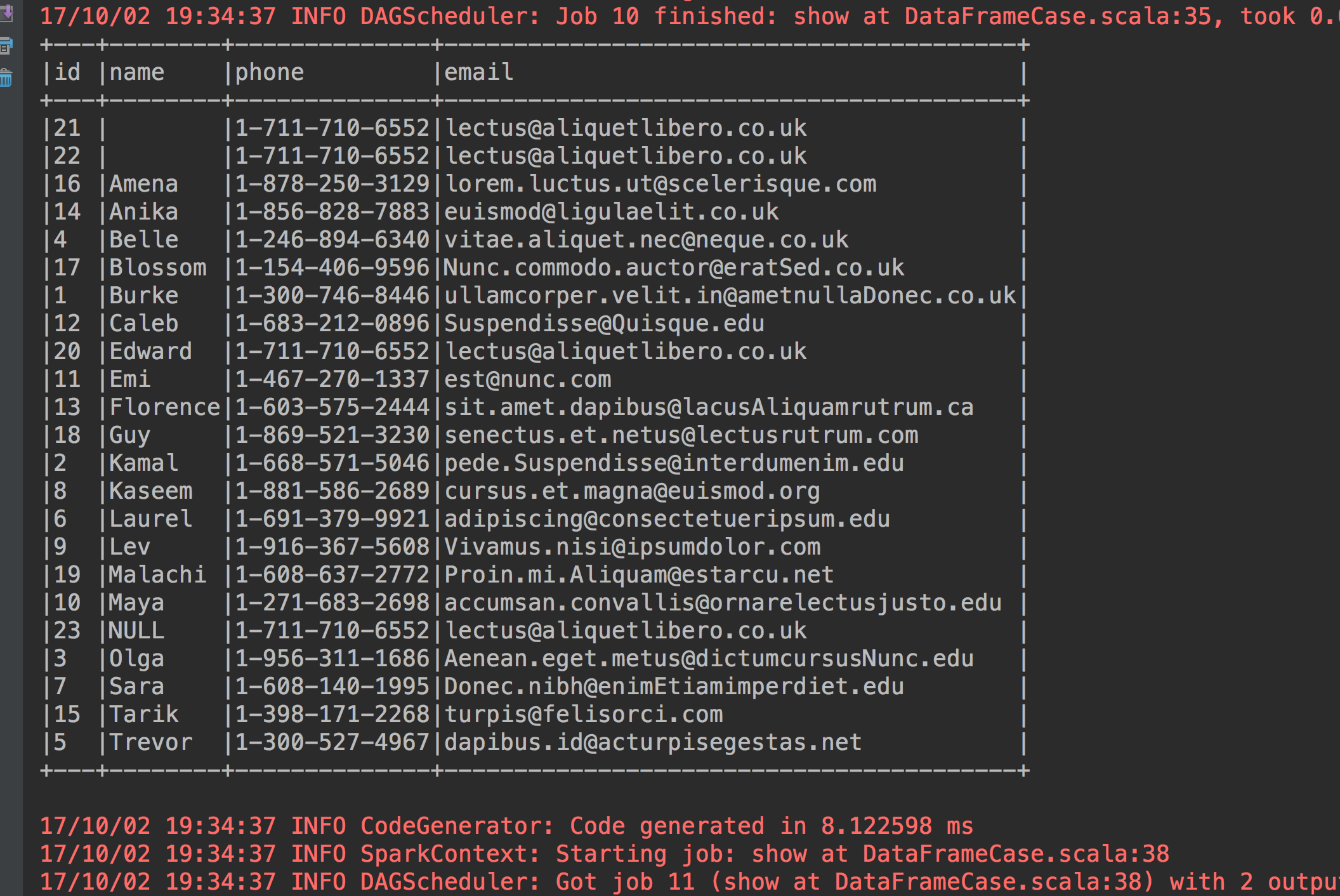
7、按照name升序id降序排序
studentdataframe.sort(studentdataframe("name").asc, studentdataframe("id").desc).show(23, false)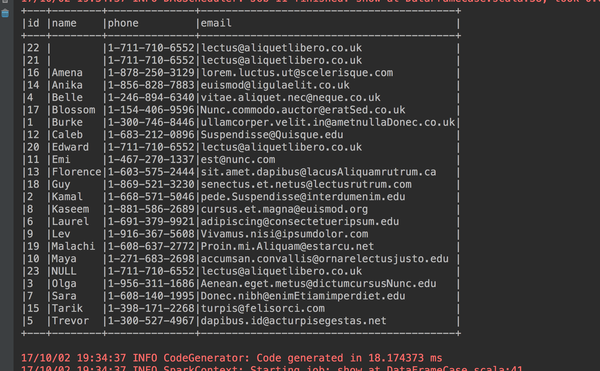
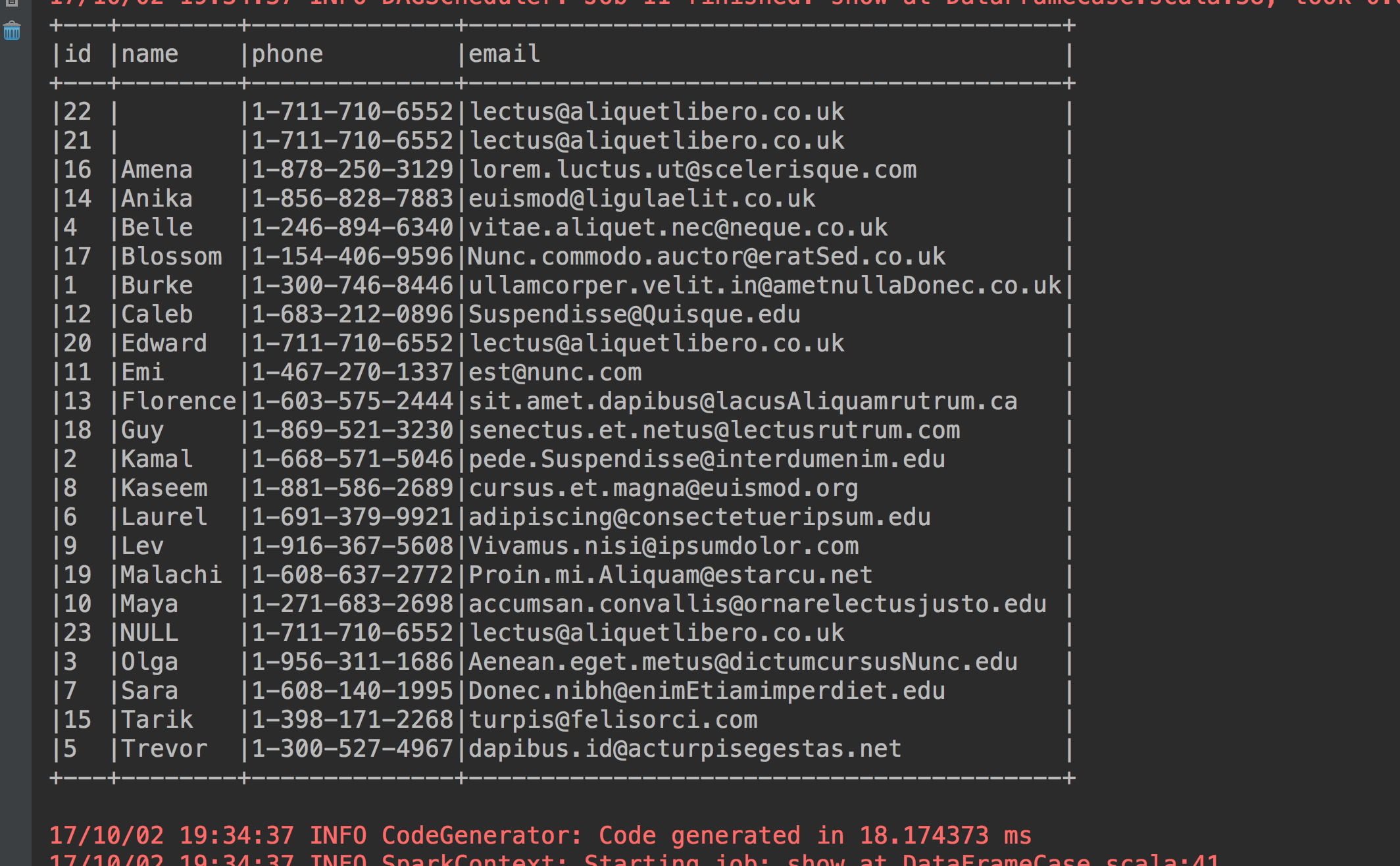
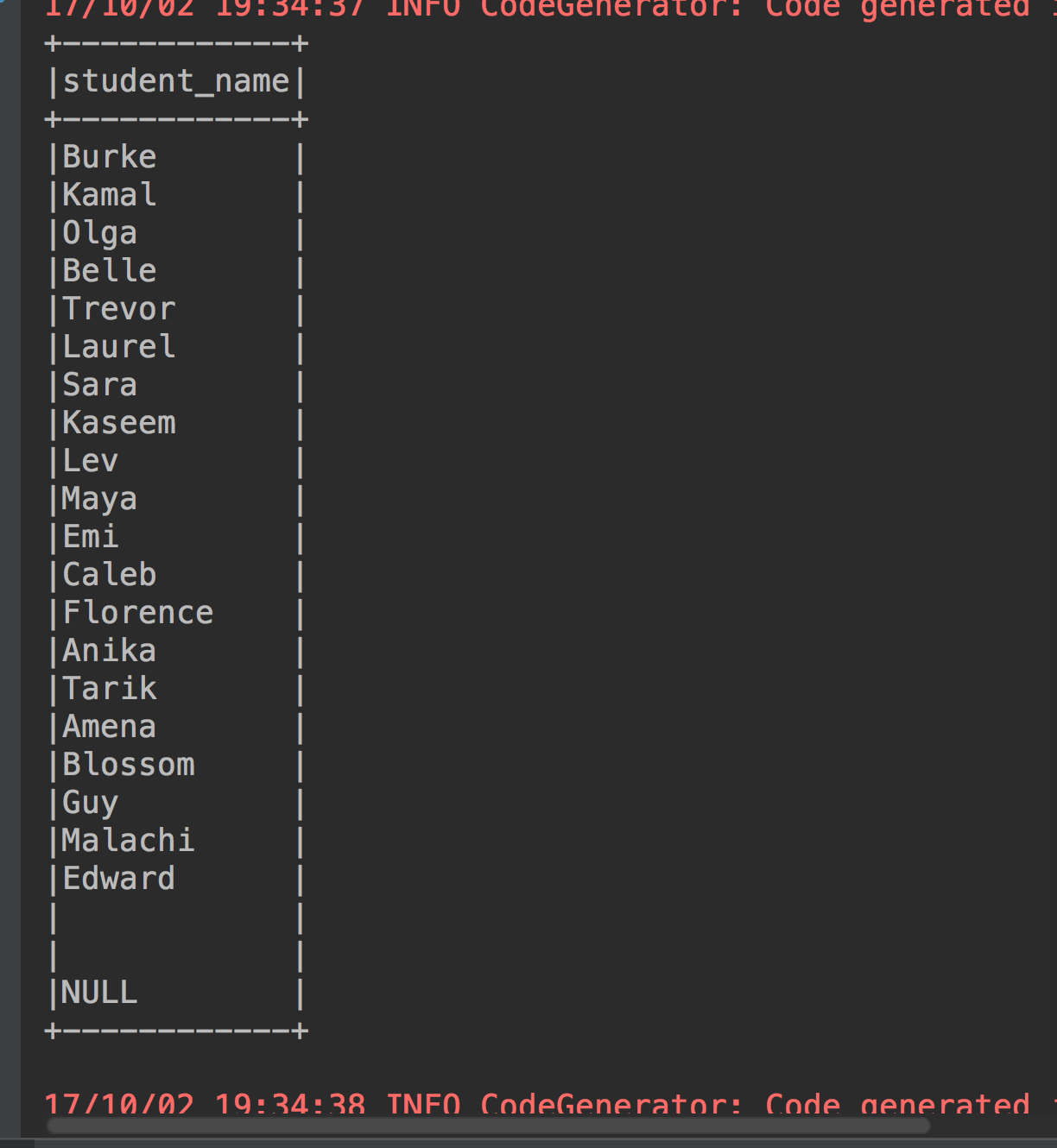
8、更改列名
studentdataframe.select(studentdataframe("name").as("student_name")).show(23, false)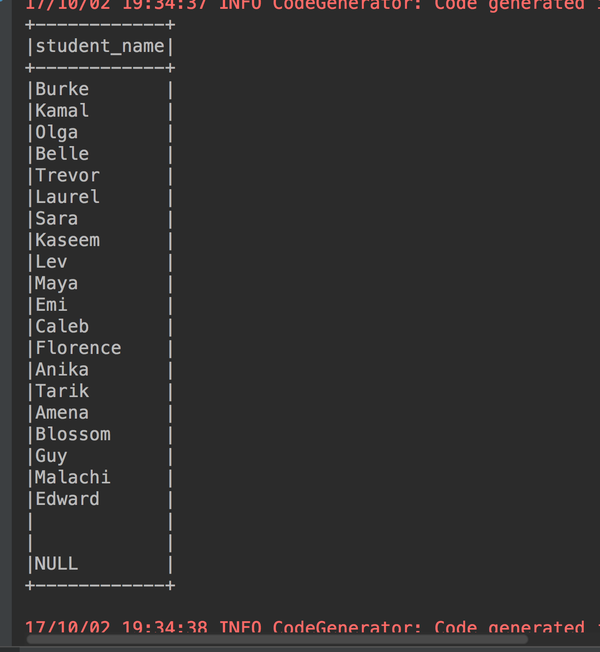
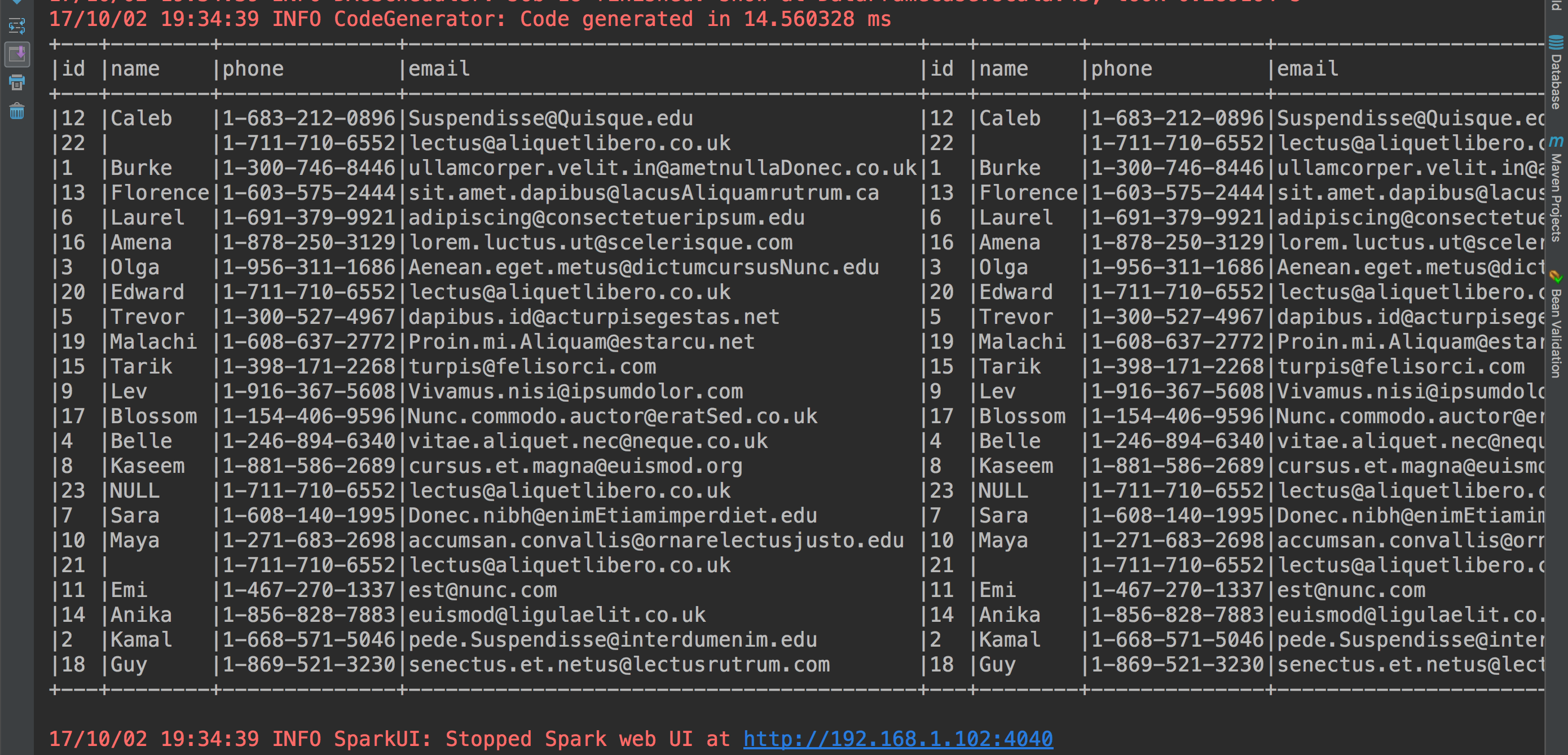
9、进行join操作(作为测试让这个表自己和自己join)
val studentdataframe_test = rdd.map(_.split("\\|")).map(line => Student(line(0).toInt, line(1), line(2), line(3))).toDF()
studentdataframe.join(studentdataframe_test, studentdataframe.col("id") === studentdataframe_test.col("id")).show(23, false)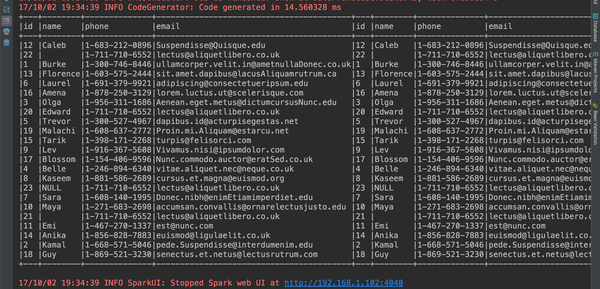
No.7 Dataset简述
还是看官网


官网说了,一个Dataset是一个分布式的数据集,而且它是一个新的接口,这个新的接口是在Spark1.6版本里面才被添加进来的,所以要注意DataFrame是先出来的,然后在1.6版本才出现的Dataset,他有什么优点呢,提供了哪些优点呢?比如强类型,支持lambda表达式,还有还提供了sparksql执行引擎的一些优化,DataFrame里面大部分东西在Dataset里面都是能用的,Dataset它能够通过哪些方式构建?一个是jvm对象,还有一些函数表达式比如map、flatMap、filter等等。这个Dataset可以使用在java和scala语言里面,注意python暂时还不能支持Dataset的API,如果你使用python开发,那就老老实实使用DataFrame的API。
在Scala API中,DataFrame就可以等于Dataset[Row]。不多说,还是用代码来说明,我们来看看Dataset的操作,我们进入IDEA。
新建一个DatasetApp
我们来操作一份csv文件
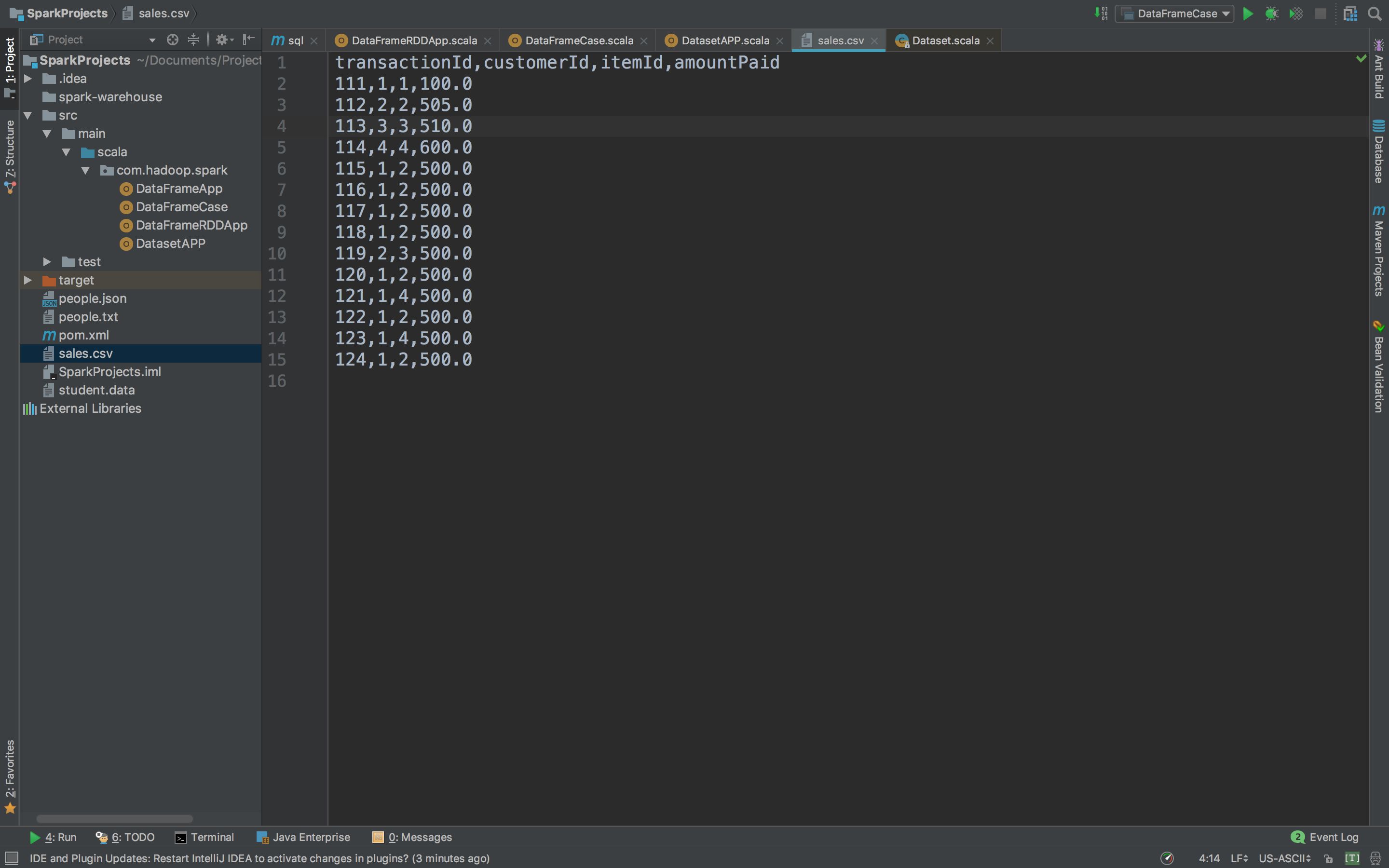
把这份文件转换成Dataset
package com.hadoop.spark
import org.apache.spark.sql.SparkSession
/**
* Dataset的操作
*/
object DatasetAPP {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("DatasetAPP").master("local[2]").getOrCreate()
//csv文件路径
val path = "file:///Users/chandler/Documents/Projects/SparkProjects/sales.csv"
//导入隐式转换
import spark.implicits._
//spark如何解析csv文件(外部数据源功能)
val csv_dataframe = spark.read.option("header","true").option("inferSchema","true").csv(path)
csv_dataframe.show
//把csv_dataframe转换成Dataset
val csv_dataset = csv_dataframe.as[Sales]
csv_dataset.map(line => line.itemId).show
spark.stop()
}
//把csv文件的列名拷贝进来
case class Sales(transactionId:Int,customerId:Int,itemId:Int,amountPaid:Double)
}
首先把csv文件加载成DataFrame然后把csv_dataframe转换成Dataset。
我们知拿出itemId这一列数据,执行结果
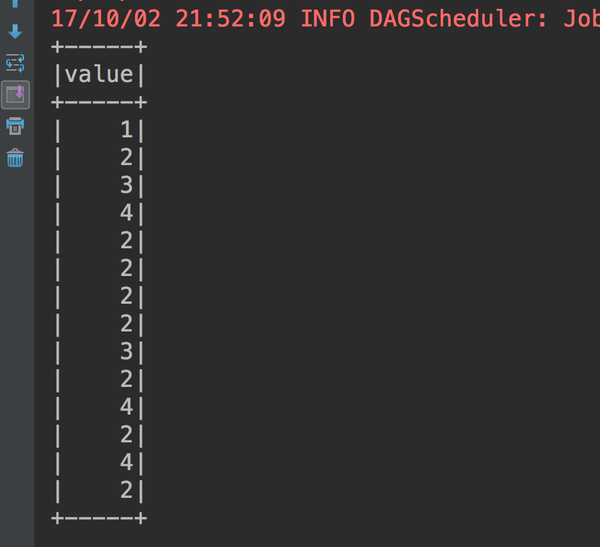
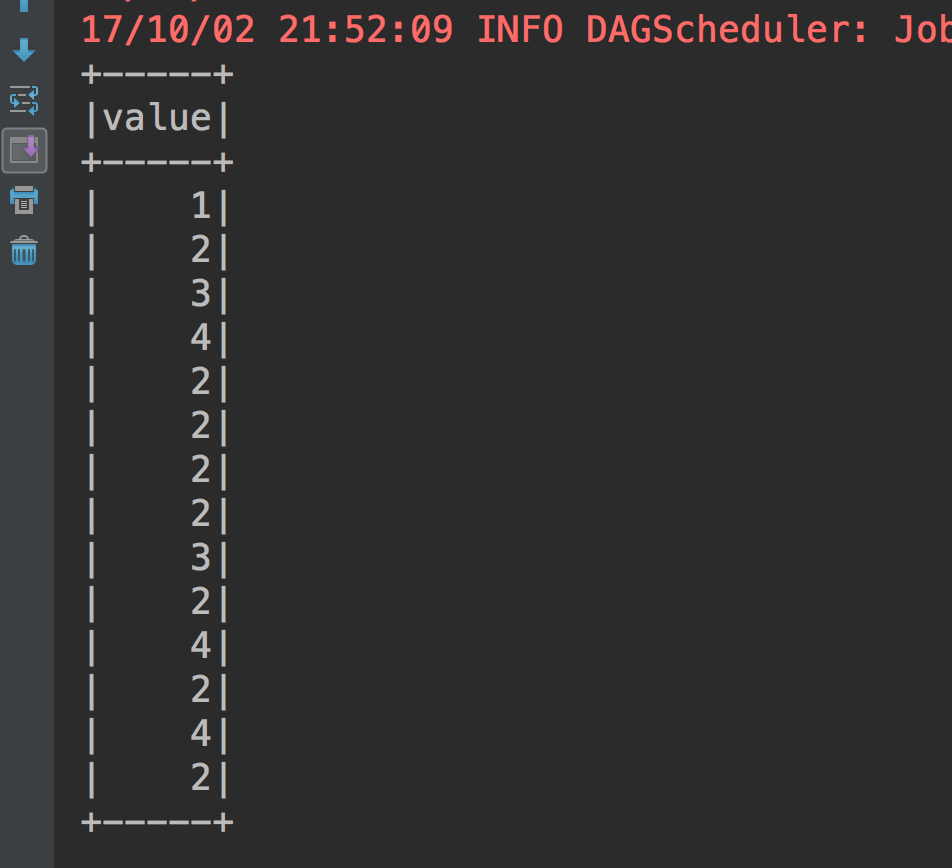
Dataset概述:
*静态类型(Static-typing)和运行时类型安全(runtime type-safety)
这是什么意思呢?我们来看一张图。
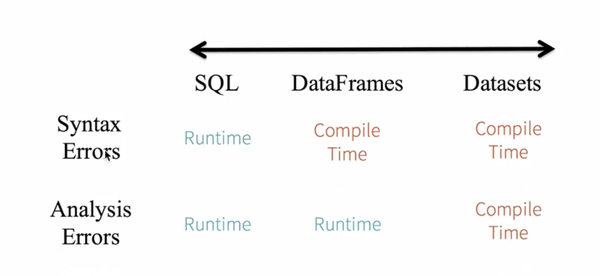

这三种sparksql编程方式,在两种状态下各自的状态是不一样的,
第一个语法的解析上面,对于sql来说,在你运行的时候再解析你的sql写的对不对,编译的时候他不知道你写的对不对,比如说一个sql语句你写错了,seletc name from people,这句sql单词写错了,很明显,但是编程的时候编译是可以过的,但是结果肯定是过不了。
但是DataFrame呢,比如本来你要select("name"),你select写错了编译都过不了。
但是,比如你这么写select("naame"),这显然是不对的,因为运行会告诉你错误,找不到这个字段,可是编译的时候他不会报naame这个字段错误。
再来看Dataset,这一句代码csv_dataset.map(line => line.itemId).show,只要itemId写错了一定编译报错。所以说上图,Dataset不管是哪种状态都是安全的,就是所谓的静态类型和运行时类型安全。因为两个状态他都可以把错误抛出来。
好了Dataset就说到这里。
---------------------------------------------------------------------------------------
END


