HBase-2.x支持7种Region自动拆分Region的策略,类图如下:
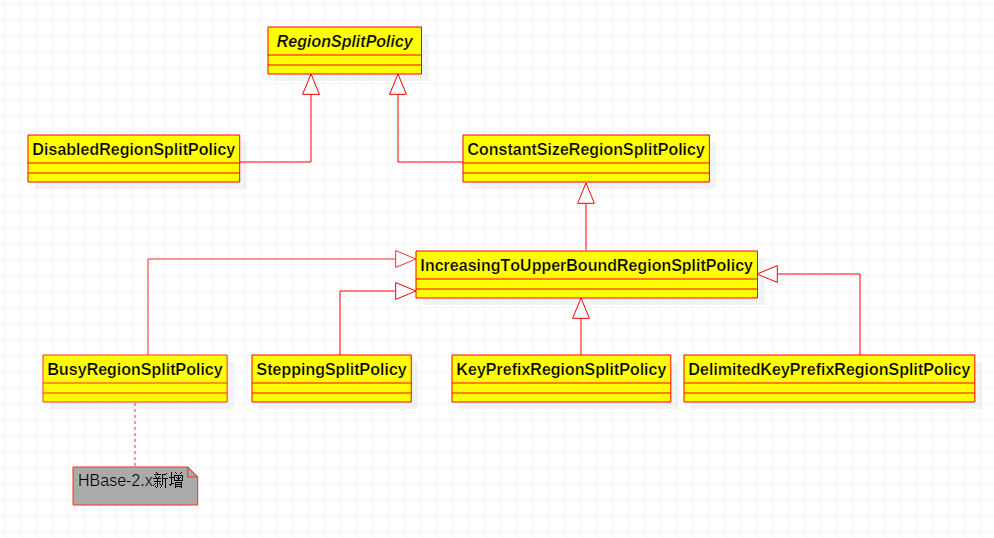
其中BusyRegionSplitPolicy是HBase-2.x新增的策略,其他6种在HBase-1.2.x中也可以使用。
设置自动拆分策略的关键配置如下:
hbase.regionserver.region.split.policy
description: Region自动拆分的策略
default:
HBase-1.2.x: org.apache.hadoop.hbase.regionserver.IncreasingToUpperBoundRegionSplitPolicy
HBase-2.x: org.apache.hadoop.hbase.regionserver.SteppingSplitPolicy
option:
org.apache.hadoop.hbase.regionserver.DisabledRegionSplitPolicy
org.apache.hadoop.hbase.regionserver.ConstantSizeRegionSplitPolicy
org.apache.hadoop.hbase.regionserver.IncreasingToUpperBoundRegionSplitPolicy
org.apache.hadoop.hbase.regionserver.SteppingSplitPolicy
org.apache.hadoop.hbase.regionserver.KeyPrefixRegionSplitPolicy
org.apache.hadoop.hbase.regionserver.DelimitedKeyPrefixRegionSplitPolicy
org.apache.hadoop.hbase.regionserver.BusyRegionSplitPolicy (HBase-2.x Only)配置方法:
- 在hbase-site.xml中配置,例如:
<property>
<name>hbase.regionserver.region.split.policy</name>
<value>org.apache.hadoop.hbase.regionserver.IncreasingToUpperBoundRegionSplitPolicy</value>
</property>- 在HBase Configuration中配置
private static Configuration conf = HBaseConfiguration.create();
conf.set("hbase.regionserver.region.split.policy", "org.apache.hadoop.hbase.regionserver.SteppingSplitPolicy");- 在创建表的时候配置 Region的拆分策略需要根据表的属性来合理的配置,所以建议不要使用前两种方法来配置拆分策略,关于在建表的时候怎么配置,会在下面解释每种策略的时候说明。
接下来将详细介绍这7种Region自动拆分的策略。
1. ConstantSizeRegionSplitPolicy
策略描述
这种策略非常简单,只要Region的大小达到了hbase.hregion.max.filesize所定义的大小,就进行拆分。
相关参数
hbase.hregion.max.filesize
default: 10737418240 (10GB)
description: 当一个Region的容量达到这个配置定义的大小后,就会拆分Region
hbase.server.thread.wakefrequency
default: 10000 (10s)
description: 检测Region的大小是否超过限制的时间间隔部分源码
/** Conf key for the max file size after which we split the region */
public static final String HREGION_MAX_FILESIZE = "hbase.hregion.max.filesize";
/** Default maximum file size */
public static final long DEFAULT_MAX_FILE_SIZE = 10 * 1024 * 1024 * 1024L;
/**
* 获取拆分上限值
*/
protected void configureForRegion(HRegion region) {
Configuration conf = getConf();
HTableDescriptor desc = region.getTableDesc();
if (desc != null) {
// 如果用户在建表时指定了该表的单个Region的上限, 取用户定义的这个值
this.desiredMaxFileSize = desc.getMaxFileSize();
}
// 如果用户没有定义, 取'hbase.hregion.max.filesize'这个配置定义的值, 如果这个配置没有定义, 取默认值 10G
if (this.desiredMaxFileSize <= 0) {
this.desiredMaxFileSize = conf.getLong(HConstants.HREGION_MAX_FILESIZE,
HConstants.DEFAULT_MAX_FILE_SIZE);
}
...
}
/**
* 判断是否进行拆分
*/
protected boolean shouldSplit() {
boolean force = region.shouldForceSplit();
boolean foundABigStore = false;
for (Store store : region.getStores()) {
// 如果有任何一个Region此时不能被拆分(例如还有一些代码或者线程在访问它), 那么返回false
if ((!store.canSplit())) {
return false;
}
// 如果Region的大小已经大于desiredMaxFileSize这个值, 返回true
if (store.getSize() > desiredMaxFileSize) {
foundABigStore = true;
}
}
return foundABigStore || force;
// 只要shouldSplit()方法返回true, 就进行Region的拆分
}拆分效果
经过这种策略的拆分后,Region的大小是均匀的,例如一个10G的Region,拆分为两个Region后,这两个新的Region的大小是相差不大的,理想状态是每个都是5G。
设置方法
HTableDescriptor tableDesc = new HTableDescriptor(TableName.valueOf("tableName"));
tableDesc.setRegionSplitPolicyClassName("org.apache.hadoop.hbase.regionserver.ConstantSizeRegionSplitPolicy");
// 以下配置根据需要配置或者不配置
tableDesc.setMaxFileSize(1048576000);
tableDesc.addFamily(...)
admin.createTable(tableDesc);2. IncreasingToUpperBoundRegionSplitPolicy
策略描述
这种拆分策略是HBase-1.2.x的默认使用的拆分策略,Region的前几次拆分的阈值不是固定的数值,是需要进行计算得到,计算过程在源码中说明。
相关配置
hbase.hregion.memstore.flush.size
default: 134217728 (128MB)
description: 如果Memstore的大小超过这个字节数,它将被刷新到磁盘.
hbase.increasing.policy.initial.size
default: none
description: IncreasingToUpperBoundRegionSplitPolicy拆分策略下用于计算Region阈值的一个初始值部分源码
protected long getSizeToCheck(final int tableRegionsCount) {
return tableRegionsCount == 0 || tableRegionsCount > 100
? getDesiredMaxFileSize()
: Math.min(getDesiredMaxFileSize(),
initialSize * tableRegionsCount * tableRegionsCount * tableRegionsCount);
}如果表目前的Region个数为0或者大于100,那么Region拆分上限值是10G,因为getDesiredMaxFileSize()方法是父类ConstantSizeRegionSplitPolicy的方法,而我们上面分析过,上限大小默认是10G。
如果表目前的Region个数在[1,100]之间,那么使用以下公式来确定Region的上限大小:
Math.min(
getDesiredMaxFileSize(),
initialSize * tableRegionsCount * tableRegionsCount * tableRegionsCount
)initialSize的计算过程如下:
public static final String HREGION_MEMSTORE_FLUSH_SIZE = "hbase.hregion.memstore.flush.size";
public static final long DEFAULT_MEMSTORE_FLUSH_SIZE = 1024*1024*128L;
protected void configureForRegion(HRegion region) {
Configuration conf = getConf();
// 如果配置了'hbase.increasing.policy.initial.size', 取这个值
initialSize = conf.getLong("hbase.increasing.policy.initial.size", -1);
if (initialSize > 0) {
return;
}
// 如果设置了MemStoreFlushSize, initialSize的值为该值 * 2
HTableDescriptor desc = region.getTableDesc();
if (desc != null) {
initialSize = 2 * desc.getMemStoreFlushSize();
}
// 如果用户没有设置MemStoreFlushSize,配置文件中也没有'hbase.increasing.policy.initial.size'这个配置
// 那么initialSize = 2 * hbase.hregion.memstore.flush.size的值
if (initialSize <= 0) {
initialSize = 2 * conf.getLong(HConstants.HREGION_MEMSTORE_FLUSH_SIZE,
HTableDescriptor.DEFAULT_MEMSTORE_FLUSH_SIZE);
}
}根据以上内容我们可以得知,在默认情况,即我们什么都没有配置的情况下,使用IncreasingToUpperBoundRegionSplitPolicy策略拆分Region的过程是:
- 某张表刚开始只有一个Region, 此时
tableRegionsCount = 1
initialSize = 2 * 128M = 256M
getDesiredMaxFileSize() = 10G
min(getDesiredMaxFileSize(), initialSize * tableRegionsCount * tableRegionsCount * tableRegionsCount) = min(10G, 256M) = 256M
即当第一个Region达到256M的时候开始拆分 - 拆分后这张表有两个Region
tableRegionsCount = 2
initialSize = 2 * 128M = 256M
getDesiredMaxFileSize() = 10G
min(getDesiredMaxFileSize(), initialSize * tableRegionsCount * tableRegionsCount * tableRegionsCount)
= min(10G, 2 * 2 * 2 * 256M)
= min(10G, 2G)
= 2G
即当Region大小达到2GB时开始拆分- 以此类推,当表有3个Region的时候,Region的最大容量为6.75G
- 当表有4个Region的时候,计算出来的结果大于10GB,所以使用10GB作为以后的拆分上限
总结一下就是,使用IncreasingToUpperBoundRegionSplitPolicy策略,Region最大容量为: 256M -> 2GB -> 6.75GB -> 10GB -> 10GB -> ...
设置方法
HTableDescriptor tableDesc = new HTableDescriptor(TableName.valueOf("tableName"));
tableDesc.setRegionSplitPolicyClassName("org.apache.hadoop.hbase.regionserver.IncreasingToUpperBoundRegionSplitPolicy");
// 以下配置根据需要配置或者不配置
tableDesc.setValue("hbase.increasing.policy.initial.size", "1048576000");
tableDesc.setMaxFileSize(1048576000);
tableDesc.setMemStoreFlushSize(1048576000);
tableDesc.addFamily(...)
admin.createTable(tableDesc);拆分效果
均匀拆分
3. KeyPrefixRegionSplitPolicy
策略描述
除了简单粗暴地根据大小来拆分,我们还可以自己定义拆分点。KeyPrefixRegionSplitPolicy是IncreasingToUpperBoundRegionSplitPolicy的子类,在前者的基础上增加了对拆分点(splitPoint,拆分点就是Region被拆分处的rowkey)的定义。它保证了有相同前缀的rowkey不会被拆分到两个不同的Region里面。
相关配置
KeyPrefixRegionSplitPolicy.prefix_length
# 注意,有的博客中这个配置是
# prefix_split_key_policy.prefix_length
# 这个配置在HBase-1.2.x版本中已经标志为 Deprecated以上参数指定了在rowkey中,取前几个字符作为前缀,例如这个设置这个值为5,那么在rowkey中,如果前5个字符是相同的,拆分后也一定会在一个Region中。
拆分效果
- 普通的拆分
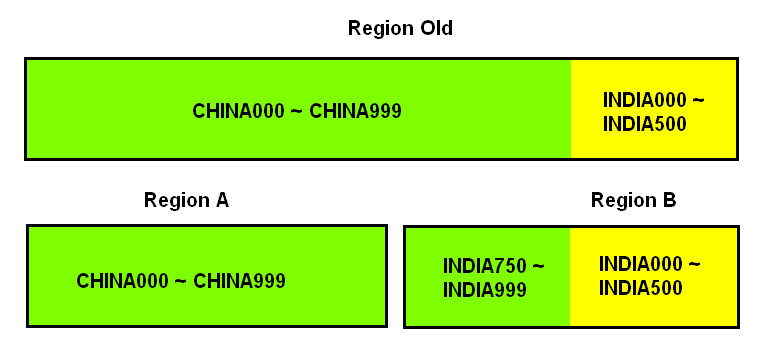
- 按照Rowkey前缀拆分

设置方法
HTableDescriptor tableDesc = new HTableDescriptor(TableName.valueOf(tableNameStr));
tableDesc.setRegionSplitPolicyClassName("org.apache.hadoop.hbase.regionserver.KeyPrefixRegionSplitPolicy");
tableDesc.setValue("KeyPrefixRegionSplitPolicy.prefix_length", "5");
// 以下配置根据需要配置或者不配置
tableDesc.setValue("hbase.increasing.policy.initial.size", "1048576000");
tableDesc.setMaxFileSize(1048576000);
tableDesc.setMemStoreFlushSize(1048576000);
tableDesc.addFamily(...)
admin.createTable(tableDesc);说明
KeyPrefixRegionSplitPolicy是IncreasingToUpperBoundRegionSplitPolicy类的子类,就是按照rowkey的前缀去拆分Region,但是什么时候拆分,原Region容量的最大值是多少还是需要使用IncreasingToUpperBoundRegionSplitPolicy的方法去计算。SteppingSplitPolicy、DelimitedKeyPrefixRegionSplitPolicy、BusyRegionSplitPolicy (HBase-2.x Only),他们获取Region的拆分阈值的方式都是继承自IncreasingToUpperBoundRegionSplitPolicy。
适用场景
如果你的所有数据都只有一两个前缀,那么采用默认的策略较好。 如果你的前缀划分的比较细,你的查询就比较容易发生跨Region查询的情况,此时采用KeyPrefixRegionSplitPolicy较好。 所以这个策略适用的场景是:
- 数据有多种前缀。
- 查询多是针对前缀,较少跨越多个前缀来查询数据。
4. DelimitedKeyPrefixRegionSplitPolicy
拆分策略
该策略也是继承自IncreasingToUpperBoundRegionSplitPolicy,它也是根据你的rowkey前缀来进行拆分的。唯一的不同就是:KeyPrefixRegionSplitPolicy是根据rowkey的固定前几位字符来进行判断,而DelimitedKeyPrefixRegionSplitPolicy是根据分隔符来判断的。
在有些系统中rowkey的前缀可能不一定都是定长的,比如你拿服务器的名字来当前缀,有的服务器叫host12有的叫host1。这些场景下严格地要求所有前缀都定长可能比较难,而且这个定长如果未来想改也不容易。DelimitedKeyPrefixRegionSplitPolicy就给了你一个定义长度字符前缀的自由。
相关配置
DelimitedKeyPrefixRegionSplitPolicy.delimiter使用该参数定义的分隔符分隔rowkey,分隔后的前部分相同的rowkey拆分后一定会在一个Region中。
配置方法
HTableDescriptor tableDesc = new HTableDescriptor(TableName.valueOf(tableNameStr));
tableDesc.setRegionSplitPolicyClassName("org.apache.hadoop.hbase.regionserver.DelimitedKeyPrefixRegionSplitPolicy");
tableDesc.setValue("DelimitedKeyPrefixRegionSplitPolicy.delimiter", "_");
...拆分效果
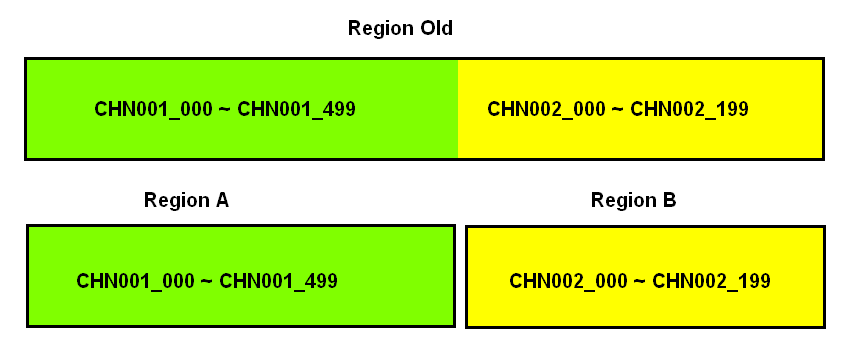
5. SteppingSplitPolicy
策略描述
这种策略和IncreasingToUpperBoundRegionSplitPolicy策略很相似,但更简单,第一个Region容量的上限为256M,之后都是10G,这个策略考虑到IncreasingToUpperBoundRegionSplitPolicy会多拆分几个Region(256M -> 2G -> 6.75G -> 10G),所以进行了简化,它的源码只有一个方法,其他都是继承自IncreasingToUpperBoundRegionSplitPolicy类
源码
protected long getSizeToCheck(final int tableRegionsCount) {
return tableRegionsCount == 1 ? this.initialSize : getDesiredMaxFileSize();
}设置方法
HTableDescriptor tableDesc = new HTableDescriptor(TableName.valueOf(tableNameStr));
tableDesc.setRegionSplitPolicyClassName("org.apache.hadoop.hbase.regionserver.SteppingSplitPolicy");6. BusyRegionSplitPolicy (HBase-2.x Only)
策略描述
此前的拆分策略都没有考虑热点问题。所谓热点问题就是数据库中的Region被访问的频率并不一样,某些Region在短时间内被访问的很频繁,承载了很大的压力,这些Region就是热点Region。
相关配置
hbase.busy.policy.blockedRequests
default: 0.2f
description: 请求阻塞率,即请求被阻塞的严重程度。
取值范围是[0.0, 1.0],默认是0.2,即20%的请求被阻塞的意思。
hbase.busy.policy.minAge
default: 600000 (10min)
description: 拆分最小年龄。
当Region的年龄比这个小的时候不拆分,这是为了防止在判断是否要拆分的时候出现了短时间的访问频率波峰,结果没必要拆分的Region被拆分了,因为短时间的波峰会很快地降回到正常水平。单位毫秒,默认值是600000,即10分钟。
hbase.busy.policy.aggWindow
default: 300000 (5min)
description: 计算是否繁忙的时间窗口,单位毫秒,默认值是300000,即5分钟。
用以控制计算的频率。如何确定为热点Region(Busy Region)
如果"当前时间 – 上次检测时间" >= hbase.busy.policy.aggWindow,则进行如下计算:
请求的被阻塞率(aggBlockedRate) = 这段时间被阻塞的请求 / 这段时间的总请求
如果 aggBlockedRate > hbase.busy.policy.blockedRequests 且该Region的 hbase.busy.policy.minAge > 10min,则判断该Region为Busy Region
当Region被判定为Busy Region,就会被拆分。
设置方法
HTableDescriptor tableDesc = new HTableDescriptor(TableName.valueOf(tableNameStr));
tableDesc.setRegionSplitPolicyClassName("org.apache.hadoop.hbase.regionserver.BusyRegionSplitPolicy");
# 以下配置根据需要适当修改
tableDesc.setValue("hbase.busy.policy.blockedRequests", "0.2");
tableDesc.setValue("hbase.busy.policy.minAge", "600000");
tableDesc.setValue("hbase.busy.policy.aggWindow", "300000");适用场景
如果你的系统常常会出现热点Region,而你对性能有很高的追求,那么这种策略可能会比较适合你。它会通过拆分热点Region来缓解热点Region的压力,但是根据热点来拆分Region也会带来很多不确定性因素,因为你也不知道下一个被拆分的Region是哪个。
7. DisabledRegionSplitPolicy
策略描述
禁止Region拆分,这个策略是极少使用的,因为就算是你按照自己数据的特性在建表的时候合理的进行了预拆分(即还没有写入的数据的时候就已经手动分好了Region),但是后续随着数据的持续写入,我们自己预先分好的Region的大小也一定会达到阈值,那时候还是要依靠HBase的自动拆分策略去拆分Region。
当然,这种策略也有它的用途:
假如我们有一批数据,根据它的用途我们知道它分为几个Region或者在什么时候拆分最合适,例如有一批数据,rowkey是手机号,而且每个手机号码前缀下(手机号码前三位)的数据量都差不多,而且这批数据主要是用于查询,要求查询的性能好一些,而且这批数据是一批静态数据,即一次存入后以后不会再加入新数据,而且这批数据的量很大,那么此时预先设置好拆分点(比如每个相同的手机号前缀一定要分到一个Region下),设置拆分策略为禁止拆分,然后导入数据即可。
在使用禁止自动拆分策略的诸多条件中,数据量大是很重要的一点,因为当使用自动拆分时,无论你设置了哪种拆分策略,一开始数据进入HBase的时候都只会往一个Region塞数据。必须要等到一个Region的大小膨胀到某个阀值的时候才会根据拆分策略来进行拆分。但是当大量的数据涌入的时候,可能会出现一边拆分一边写入大量数据的情况,由于拆分要占用大量IO,此时HBase数据库的压力是很大的。
设置方法
HTableDescriptor tableDesc = new HTableDescriptor(TableName.valueOf(tableNameStr));
tableDesc.setRegionSplitPolicyClassName("org.apache.hadoop.hbase.regionserver.DisabledRegionSplitPolicy");关于Region的预拆分,HBase Region 预拆分(还没有写...)一文中将会详细说明。
