Region自动切分是HBase能够拥有良好扩张性的最重要因素之一,也必然是所有分布式系统追求无限扩展性的一副良药。HBase系统中Region自动切分是如何实现的?这里面涉及很多知识点,比如Region切分的触发条件是什么?Region切分的切分点在哪里?如何切分才能最大的保证Region的可用性?如何做好切分过程中的异常处理?切分过程中要不要将数据移动?等等,这篇文章将会对这些细节进行基本的说明,一方面可以让大家对HBase中Region自动切分有更加深入的理解,另一方面如果想实现类似的功能也可以参考HBase的实现方案。
Region切分触发策略
在最新稳定版(1.2.6)中,HBase已经有多达6种切分触发策略。当然,每种触发策略都有各自的适用场景,用户可以根据业务在表级别选择不同的切分触发策略。常见的切分策略如下图:
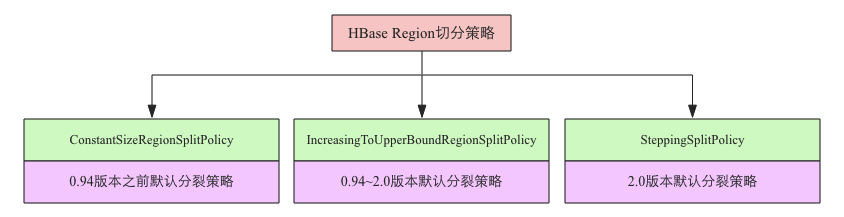
- ConstantSizeRegionSplitPolicy:0.94版本前默认切分策略。这是最容易理解但也最容易产生误解的切分策略,从字面意思来看,当region大小大于某个阈值(hbase.hregion.max.filesize)之后就会触发切分,实际上并不是这样,真正实现中这个阈值是对于某个store来说的,即一个region中最大store的大小大于设置阈值之后才会触发切分。另外一个大家比较关心的问题是这里所说的store大小是压缩后的文件总大小还是未压缩文件总大小,实际实现中store大小为压缩后的文件大小(采用压缩的场景)。ConstantSizeRegionSplitPolicy相对来来说最容易想到,但是在生产线上这种切分策略却有相当大的弊端:切分策略对于大表和小表没有明显的区分。阈值(hbase.hregion.max.filesize)设置较大对大表比较友好,但是小表就有可能不会触发分裂,极端情况下可能就1个,这对业务来说并不是什么好事。如果设置较小则对小表友好,但一个大表就会在整个集群产生大量的region,这对于集群的管理、资源使用、failover来说都不是一件好事。
- IncreasingToUpperBoundRegionSplitPolicy: 0.94版本~2.0版本默认切分策略。这种切分策略微微有些复杂,总体来看和ConstantSizeRegionSplitPolicy思路相同,一个region中最大store大小大于设置阈值就会触发切分。但是这个阈值并不像ConstantSizeRegionSplitPolicy是一个固定的值,而是会在一定条件下不断调整,调整规则和region所属表在当前regionserver上的region个数有关系 :(#regions) * (#regions) * (#regions) * flush size * 2,当然阈值并不会无限增大,最大值为用户设置的MaxRegionFileSize。这种切分策略很好的弥补了ConstantSizeRegionSplitPolicy的短板,能够自适应大表和小表。而且在大集群条件下对于很多大表来说表现很优秀,但并不完美,这种策略下很多小表会在大集群中产生大量小region,分散在整个集群中。而且在发生region迁移时也可能会触发region分裂。
- SteppingSplitPolicy: 2.0版本默认切分策略。这种切分策略的切分阈值又发生了变化,相比IncreasingToUpperBoundRegionSplitPolicy简单了一些,依然和待分裂region所属表在当前regionserver上的region个数有关系,如果region个数等于1,切分阈值为flush size * 2,否则为MaxRegionFileSize。这种切分策略对于大集群中的大表、小表会比IncreasingToUpperBoundRegionSplitPolicy更加友好,小表不会再产生大量的小region,而是适可而止。
另外,还有一些其他分裂策略,比如使用DisableSplitPolicy:可以禁止region发生分裂;而KeyPrefixRegionSplitPolicy,DelimitedKeyPrefixRegionSplitPolicy对于切分策略依然依据默认切分策略,但对于切分点有自己的看法,比如KeyPrefixRegionSplitPolicy要求必须让相同的PrefixKey待在一个region中。
在用法上,一般情况下使用默认切分策略即可,也可以在cf级别设置region切分策略,命令为:
create ’table’, {NAME => ‘cf’, SPLIT_POLICY => ‘org.apache.hadoop.hbase.regionserver. ConstantSizeRegionSplitPolicy'}
Region切分准备工作-寻找SplitPoint
region切分策略会触发region切分,切分开始之后的第一件事是寻找切分点-splitpoint。所有默认切分策略,无论是ConstantSizeRegionSplitPolicy、IncreasingToUpperBoundRegionSplitPolicy抑或是SteppingSplitPolicy,对于切分点的定义都是一致的。当然,用户手动执行切分时是可以指定切分点进行切分的,这里并不讨论这种情况。
那切分点是如何定位的呢?整个region中最大store中的最大文件中最中心的一个block的首个rowkey。这是一句比较消耗脑力的语句,需要细细品味。另外,HBase还规定,如果定位到的rowkey是整个文件的首个rowkey或者最后一个rowkey的话,就认为没有切分点。
什么情况下会出现没有切分点的场景呢?最常见的就是一个文件只有一个block,执行split的时候就会发现无法切分。很多新同学在测试split的时候往往都是新建一张新表,然后往新表中插入几条数据并执行一下flush,再执行split,奇迹般地发现数据表并没有真正执行切分。原因就在这里,这个时候仔细的话你翻看debug日志是可以看到这样的日志滴:

Region核心切分流程
HBase将整个切分过程包装成了一个事务,意图能够保证切分事务的原子性。整个分裂事务过程分为三个阶段:prepare – execute – (rollback) ,操作模版如下:
- prepare阶段:在内存中初始化两个子region,具体是生成两个HRegionInfo对象,包含tableName、regionName、startkey、endkey等。同时会生成一个transaction journal,这个对象用来记录切分的进展,具体见rollback阶段。
- execute阶段:切分的核心操作。见下图(来自Hortonworks):
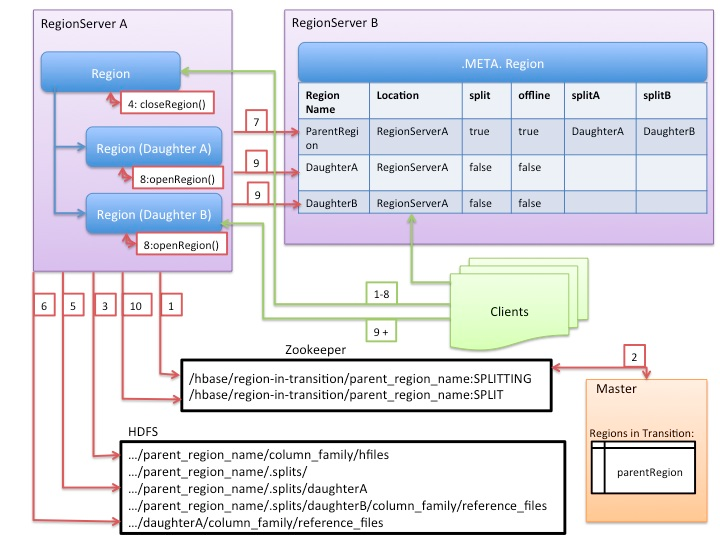
- regionserver 更改ZK节点 /region-in-transition 中该region的状态为SPLITING。
- master通过watch节点/region-in-transition检测到region状态改变,并修改内存中region的状态,在master页面RIT模块就可以看到region执行split的状态信息。
- 在父存储目录下新建临时文件夹.split保存split后的daughter region信息。
- 关闭parent region:parent region关闭数据写入并触发flush操作,将写入region的数据全部持久化到磁盘。此后短时间内客户端落在父region上的请求都会抛出异常NotServingRegionException。
- 核心分裂步骤:在.split文件夹下新建两个子文件夹,称之为daughter A、daughter B,并在文件夹中生成reference文件,分别指向父region中对应文件。这个步骤是所有步骤中最核心的一个环节,生成reference文件日志如下所示:
2017-08-12 11:53:38,158 DEBUG [StoreOpener-0155388346c3c919d3f05d7188e885e0-1] regionserver.StoreFileInfo: reference 'hdfs://hdfscluster/hbase-rsgroup/data/default/music/0155388346c3c919d3f05d7188e885e0/cf/d24415c4fb44427b8f698143e5c4d9dc.00bb6239169411e4d0ecb6ddfdbacf66' to region=00bb6239169411e4d0ecb6ddfdbacf66 hfile=d24415c4fb44427b8f698143e5c4d9dc。
其中reference文件名为d24415c4fb44427b8f698143e5c4d9dc.00bb6239169411e4d0ecb6ddfdbacf66,格式看起来比较特殊,那这种文件名具体什么含义呢?那来看看该reference文件指向的父region文件,根据日志可以看到,切分的父region是00bb6239169411e4d0ecb6ddfdbacf66,对应的切分文件是d24415c4fb44427b8f698143e5c4d9dc,可见reference文件名是个信息量很大的命名方式,如下所示:

除此之外,还需要关注reference文件的文件内容,reference文件是一个引用文件(并非linux链接文件),文件内容很显然不是用户数据。文件内容其实非常简单,主要有两部分构成:其一是切分点splitkey,其二是一个boolean类型的变量(true或者false),true表示该reference文件引用的是父文件的上半部分(top),而false表示引用的是下半部分 (bottom)。为什么存储的是这两部分内容?且听下文分解。
看官可以使用hadoop命令亲自来查看reference文件的具体内容:
hadoop dfs -cat /hbase-rsgroup/data/default/music/0155388346c3c919d3f05d7188e885e0/cf/d24415c4fb44427b8f698143e5c4d9dc.00bb6239169411e4d0ecb6ddfdbacf66
6. 父region分裂为两个子region后,将daughter A、daughter B拷贝到HBase根目录下,形成两个新的region。
7. parent region通知修改 hbase.meta 表后下线,不再提供服务。下线后parent region在meta表中的信息并不会马上删除,而是标注split列、offline列为true,并记录两个子region。为什么不立马删除?且听下文分解。

8. 开启daughter A、daughter B两个子region。通知修改 hbase.meta 表,正式对外提供服务。

- rollback阶段:如果execute阶段出现异常,则执行rollback操作。为了实现回滚,整个切分过程被分为很多子阶段,回滚程序会根据当前进展到哪个子阶段清理对应的垃圾数据。代码中使用 JournalEntryType 来表征各个子阶段,具体见下图:

Region切分事务性保证
整个region切分是一个比较复杂的过程,涉及到父region中HFile文件的切分、两个子region的生成、系统meta元数据的更改等很多子步骤,因此必须保证整个切分过程的事务性,即要么切分完全成功,要么切分完全未开始,在任何情况下也不能出现切分只完成一半的情况。
为了实现事务性,hbase设计了使用状态机(见SplitTransaction类)的方式保存切分过程中的每个子步骤状态,这样一旦出现异常,系统可以根据当前所处的状态决定是否回滚,以及如何回滚。遗憾的是,目前实现中这些中间状态都只存储在内存中,因此一旦在切分过程中出现regionserver宕机的情况,有可能会出现切分处于中间状态的情况,也就是RIT状态。这种情况下需要使用hbck工具进行具体查看并分析解决方案。在2.0版本之后,HBase实现了新的分布式事务框架Procedure V2(HBASE-12439),新框架将会使用HLog存储这种单机事务(DDL操作、Split操作、Move操作等)的中间状态,因此可以保证即使在事务执行过程中参与者发生了宕机,依然可以使用HLog作为协调者对事务进行回滚操作或者重试提交,大大减少甚至杜绝RIT现象。这也是是2.0在可用性方面最值得期待的一个亮点!!!
Region切分对其他模块的影响
通过region切分流程的了解,我们知道整个region切分过程并没有涉及数据的移动,所以切分成本本身并不是很高,可以很快完成。切分后子region的文件实际没有任何用户数据,文件中存储的仅是一些元数据信息-切分点rowkey等,那通过引用文件如何查找数据呢?子region的数据实际在什么时候完成真正迁移?数据迁移完成之后父region什么时候会被删掉?
1. 通过reference文件如何查找数据?
这里就会看到reference文件名、文件内容的实际意义啦。整个流程如下图所示:

(1)根据reference文件名(region名+真实文件名)定位到真实数据所在文件路径
(2)定位到真实数据文件就可以在整个文件中扫描待查KV了么?非也。因为reference文件通常都只引用了数据文件的一半数据,以切分点为界,要么上半部分文件数据,要么下半部分数据。那到底哪部分数据?切分点又是哪个点?还记得上文又提到reference文件的文件内容吧,没错,就记录在文件中。
2. 父region的数据什么时候会迁移到子region目录?
答案是子region发生major_compaction时。我们知道compaction的执行实际上是将store中所有小文件一个KV一个KV从小到大读出来之后再顺序写入一个大文件,完成之后再将小文件删掉,因此compaction本身就需要读取并写入大量数据。子region执行major_compaction后会将父目录中属于该子region的所有数据读出来并写入子region目录数据文件中。可见将数据迁移放到compaction这个阶段来做,是一件顺便的事。
3. 父region什么时候会被删除?
实际上HMaster会启动一个线程定期遍历检查所有处于splitting状态的父region,确定检查父region是否可以被清理。检测线程首先会在meta表中揪出所有split列为true的region,并加载出其分裂后生成的两个子region(meta表中splitA列和splitB列),只需要检查此两个子region是否还存在引用文件,如果都不存在引用文件就可以认为该父region对应的文件可以被删除。现在再来看看上文中父目录在meta表中的信息,就大概可以理解为什么会存储这些信息了:

4. split模块在生产线的一些坑?
有些时候会有同学反馈说集群中部分region处于长时间RIT,region状态为spliting。通常情况下都会建议使用hbck看下什么报错,然后再根据hbck提供的一些工具进行修复,hbck提供了部分命令对处于split状态的rit region进行修复,主要的命令如下:
-fixSplitParents Try to force offline split parents to be online. -removeParents Try to offline and sideline lingering parents and keep daughter regions. -fixReferenceFiles Try to offline lingering reference store files
其中最常见的问题是 :
ERROR: Found lingering reference file hdfs://mycluster/hbase/news_user_actions/3b3ae24c65fc5094bc2acfebaa7a56de/meta/0f47cda55fa44cf9aa2599079894aed6.b7b3faab86527b88a92f2a248a54d3dc”
简单解释一下,这个错误是说reference文件所引用的父region文件不存在了,如果查看日志的话有可能看到如下异常:
java.io.IOException: java.io.IOException: java.io.FileNotFoundException: File does not exist:/hbase/news_user_actions/b7b3faab86527b88a92f2a248a54d3dc/meta/0f47cda55fa44cf9aa2599079894aed
父region文件为什么会莫名其妙不存在?经过和朋友的讨论,确认有可能是因为官方bug导致,详见HBASE-13331。这个jira是说HMaster在确认父目录是否可以被删除时,如果检查引用文件(检查是否存在、检查是否可以正常打开)抛出IOException异常,函数就会返回没有引用文件,导致父region被删掉。正常情况下应该保险起见返回存在引用文件,保留父region,并打印日志手工介入查看。如果大家也遇到类似的问题,可以看看这个问题,也可以将修复patch打到线上版本或者升级版本。
