我们知道,在 JVM 中,一个类加载的过程大致分为加载、链接(验证、准备、解析)、初始化5个阶段。而我们通常提到类的加载,就是指利用类加载器(ClassLoader)通过类的全限定名来获取定义此类的二进制字节码流,进而构造出类的定义。
Flink 作为基于 JVM 的框架,在 flink-conf.yaml 中提供了控制类加载策略的参数 classloader.resolve-order,可选项有 child-first(默认)和 parent-first。本文来简单分析一下这个参数背后的含义。
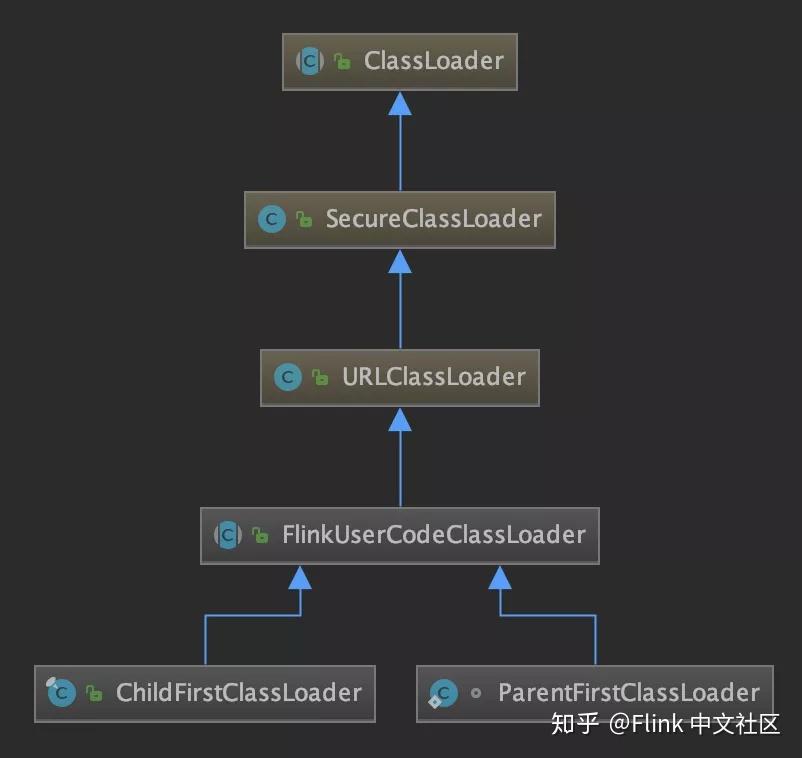
parent-first 类加载策略
ParentFirstClassLoader 和 ChildFirstClassLoader 类的父类均为 FlinkUserCodeClassLoader 抽象类,先来看看这个抽象类,代码很短。
public abstract class FlinkUserCodeClassLoader extends URLClassLoader {
public static final Consumer<Throwable> NOOP_EXCEPTION_HANDLER = classLoadingException -> {};
private final Consumer<Throwable> classLoadingExceptionHandler;
protected FlinkUserCodeClassLoader(URL[] urls, ClassLoader parent) {
this(urls, parent, NOOP_EXCEPTION_HANDLER);
}
protected FlinkUserCodeClassLoader(
URL[] urls,
ClassLoader parent,
Consumer<Throwable> classLoadingExceptionHandler) {
super(urls, parent);
this.classLoadingExceptionHandler = classLoadingExceptionHandler;
}
@Override
protected final Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException {
try {
return loadClassWithoutExceptionHandling(name, resolve);
} catch (Throwable classLoadingException) {
classLoadingExceptionHandler.accept(classLoadingException);
throw classLoadingException;
}
}
protected Class<?> loadClassWithoutExceptionHandling(String name, boolean resolve) throws ClassNotFoundException {
return super.loadClass(name, resolve);
}
}FlinkUserCodeClassLoader 继承自 URLClassLoader。因为 Flink App 的用户代码在运行期才能确定,所以通过 URL 在 JAR 包内寻找全限定名对应的类是比较合适的。而 ParentFirstClassLoader 仅仅是一个继承 FlinkUserCodeClassLoader 的空类而已。
static class ParentFirstClassLoader extends FlinkUserCodeClassLoader { ParentFirstClassLoader(URL[] urls, ClassLoader parent, Consumer<Throwable> classLoadingExceptionHandler) {
super(urls, parent, classLoadingExceptionHandler);
}
}这样就相当于 ParentFirstClassLoader 直接调用了父加载器的 loadClass() 方法。之前已经讲过,JVM 中类加载器的层次关系和默认 loadClass() 方法的逻辑由双亲委派模型(parents delegation model)来体现,复习一下含义:
如果一个类加载器要加载一个类,它首先不会自己尝试加载这个类,而是把加载的请求委托给父加载器完成,所有的类加载请求最终都应该传递给最顶层的启动类加载器。只有当父加载器无法加载到这个类时,子加载器才会尝试自己加载。
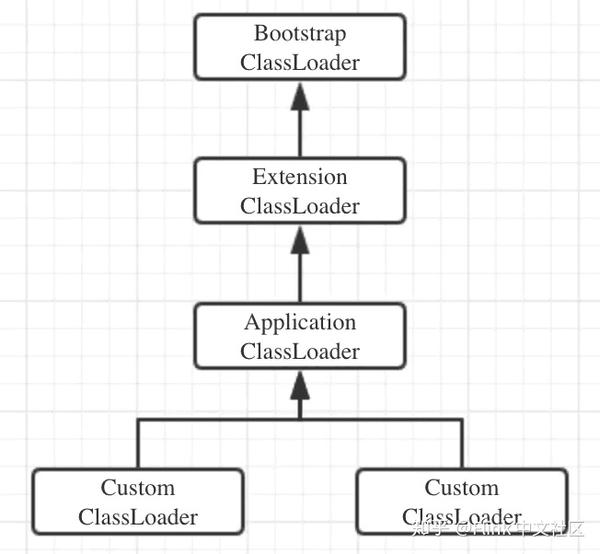
可见,Flink 的 parent-first 类加载策略就是照搬双亲委派模型的。也就是说,用户代码的类加载器是 Custom ClassLoader,Flink 框架本身的类加载器是 Application ClassLoader。用户代码中的类先由 Flink 框架的类加载器加载,再由用户代码的类加载器加载。但是,Flink 默认并不采用 parent-first 策略,而是采用下面的 child-first 策略,继续看。
child-first 类加载策略
我们已经了解到,双亲委派模型的好处就是随着类加载器的层次关系保证了被加载类的层次关系,从而保证了 Java 运行环境的安全性。但是在 Flink App 这种依赖纷繁复杂的环境中,双亲委派模型可能并不适用。例如,程序中引入的 Flink-Cassandra Connector 总是依赖于固定的 Cassandra 版本,用户代码中为了兼容实际使用的 Cassandra 版本,会引入一个更低或更高的依赖。而同一个组件不同版本的类定义有可能会不同(即使类的全限定名是相同的),如果仍然用双亲委派模型,就会因为 Flink 框架指定版本的类先加载,而出现莫名其妙的兼容性问题,如 NoSuchMethodError、IllegalAccessError 等。
鉴于此,Flink 实现了 ChildFirstClassLoader 类加载器并作为默认策略。它打破了双亲委派模型,使得用户代码的类先加载,官方文档中将这个操作称为"Inverted Class Loading"。代码仍然不长,录如下。
public final class ChildFirstClassLoader extends FlinkUserCodeClassLoader {
private final String[] alwaysParentFirstPatterns;
public ChildFirstClassLoader(
URL[] urls,
ClassLoader parent,
String[] alwaysParentFirstPatterns,
Consumer<Throwable> classLoadingExceptionHandler) {
super(urls, parent, classLoadingExceptionHandler);
this.alwaysParentFirstPatterns = alwaysParentFirstPatterns;
}
@Override
protected synchronized Class<?> loadClassWithoutExceptionHandling(
String name,
boolean resolve) throws ClassNotFoundException {
// First, check if the class has already been loaded
Class<?> c = findLoadedClass(name);
if (c == null) {
// check whether the class should go parent-first
for (String alwaysParentFirstPattern : alwaysParentFirstPatterns) {
if (name.startsWith(alwaysParentFirstPattern)) {
return super.loadClassWithoutExceptionHandling(name, resolve);
}
}
try {
// check the URLs
c = findClass(name);
} catch (ClassNotFoundException e) {
// let URLClassLoader do it, which will eventually call the parent
c = super.loadClassWithoutExceptionHandling(name, resolve);
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
@Override
public URL getResource(String name) {
// first, try and find it via the URLClassloader
URL urlClassLoaderResource = findResource(name);
if (urlClassLoaderResource != null) {
return urlClassLoaderResource;
}
// delegate to super
return super.getResource(name);
}
@Override
public Enumeration<URL> getResources(String name) throws IOException {
// first get resources from URLClassloader
Enumeration<URL> urlClassLoaderResources = findResources(name);
final List<URL> result = new ArrayList<>();
while (urlClassLoaderResources.hasMoreElements()) {
result.add(urlClassLoaderResources.nextElement());
}
// get parent urls
Enumeration<URL> parentResources = getParent().getResources(name);
while (parentResources.hasMoreElements()) {
result.add(parentResources.nextElement());
}
return new Enumeration<URL>() {
Iterator<URL> iter = result.iterator();
public boolean hasMoreElements() {
return iter.hasNext();
}
public URL nextElement() {
return iter.next();
}
};
}
}核心逻辑位于 loadClassWithoutExceptionHandling() 方法中,简述如下:
- 调用 findLoadedClass() 方法检查全限定名 name 对应的类是否已经加载过,若没有加载过,再继续往下执行。
- 检查要加载的类是否以 alwaysParentFirstPatterns 集合中的前缀开头。如果是,则调用父类的对应方法,以 parent-first 的方式来加载它。
- 如果类不符合 alwaysParentFirstPatterns 集合的条件,就调用 findClass() 方法在用户代码中查找并获取该类的定义(该方法在 URLClassLoader 中有默认实现)。如果找不到,再 fallback 到父加载器来加载。
- 最后,若 resolve 参数为 true,就调用 resolveClass() 方法链接该类,最后返回对应的 Class 对象。
可见,child-first 策略避开了“先把加载的请求委托给父加载器完成”这一步骤,只有特定的某些类一定要“遵循旧制”。alwaysParentFirstPatterns 集合中的这些类都是 Java、Flink 等组件的基础,不能被用户代码冲掉。它由以下两个参数来指定:
classloader.parent-first-patterns.default,不建议修改,固定为以下这些值:
java.;
scala.;
org.apache.flink.;
com.esotericsoftware.kryo;
org.apache.hadoop.;
javax.annotation.;
org.slf4j;
org.apache.log4j;
org.apache.logging;
org.apache.commons.logging;
ch.qos.logback;
org.xml;
javax.xml;
org.apache.xerces;
org.w3c- classloader.parent-first-patterns.additional:除了上一个参数指定的类之外,用户如果有其他类以 child-first 模式会发生冲突,而希望以双亲委派模型来加载的话,可以额外指定(分号分隔)。
以上是关于 flink-conf.yaml 中提供的控制类加载策略的参数 classloader.resolve-order 含义的理解和分享,希望对大家有所启发和帮助~
原文链接:
