文章目录
1. 为什么需要限流
无论是在单体服务中还是在微服务中,提供的API接口都是有访问上限的
当非预期的请求对系统压力过大,我们就必须考虑使用限流来丢弃部分请求,以保障服务整体可用,以防止压力超出系统承载上限而拖垮系统,比如遇到以下情况:
- 业务上:热点业务的突发请求
- 代码上:调用方bug导致的突发请求
- 安全上:被恶意攻击,例如:DDOS攻击
因此对公开暴露的接口最好都加上限流措施
2. 传统限流的问题
使用限流器的前提是必须知道自身的能够处理的最大并发数,一般在上线前通过压测得到qps,但这种方式有以下几个问题:
- 每个接口的限流参数可能都不一样,需要限流的接口都要压测,流程繁琐
- 压测一般是单接口压,但真实线上环境是多个接口一起提供服务,单接口压测的数据比实际能承受的QPS更大,使得qps数据不准确
- 随着业务迭代,每个接口的处理能力往往也会随之变化,如果需要精确更新限流参数,每次上线前都需要进行压测,变得非常繁琐
那么有没有一种更加简洁的限流机制能实现最大限度的自我保护呢?
过载保护能智能地根据服务自身的负载情况判断是否需要开启保护,其目标为:
- 系统不会被请求压垮
- 在不被压垮的前提下,保持系统的吞吐量
那如何判断服务的负载是否达到过载的阈值呢?一般有以下几个指标:
- cpu负载(cpu load)(常用)
- 内存负载(mem load)
- 正在处理的请求数(inflight)
一个简单的思路是,只根据cpu负载指标作为是否放行请求的依据:
- cpu负载小于阈值:就放行请求
- cpu负载大于等于阈值:拒绝请求
但这样会有负载抖动的问题:因为load是一个结果,即load的统计有延迟性:
- 当发现负载没达到阈值而放行时,可能放了很多请求过去,而这些请求在真正执行时才会把load推高,导致负载陡增,甚至超过系统负载
- 可以类比成非并发安全的
check and do,check load没有超过阈值再放行do,但check和do没有原子性
- 可以类比成非并发安全的
- 当发现负载超过阈值时,此时会拒绝请求,但是等到负载小于阈值时,由于过去一段时间都没有放行请求,会造成一段空窗期,这段空窗期导致负载抖降,浪费了系统的处理能力
延迟性就是造成负载抖动的关键
3. kratos限流算法
因此在判断系统是否过载时,cpu load只作为开始保护的一个条件,真正的判断依据是正在处理的请求数inflight
由于正在处理的请求数的统计在请求开始前+1,请求结束后-1,没有延迟,不会造成上面提到的问题
那怎么判断inflight有没有超过阈值呢?就需要根据历史的请求数和平均响应时间来计算出这个阈值
先举个例子:
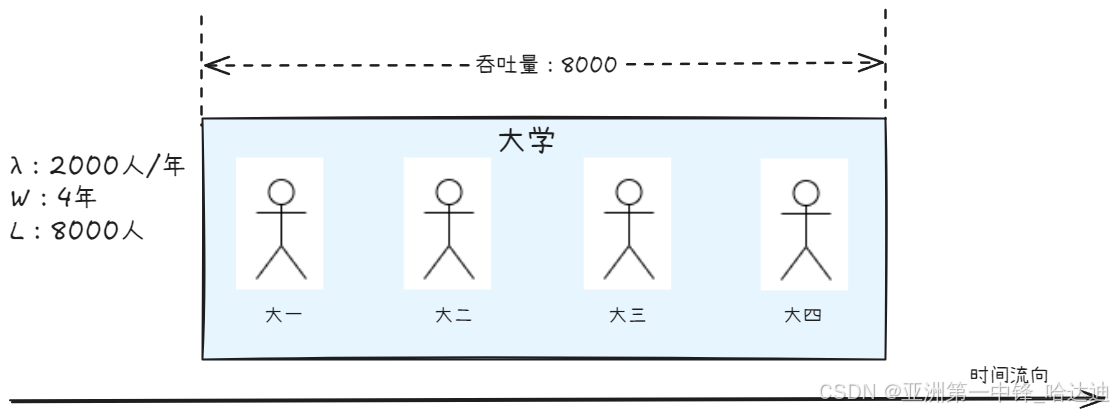
已知某大学每年招收2000名学生, 每名学生均需要4年才能毕业离校,请估算目前在你们大学就读的学生总人数
这道题目的答案是8000 (2000 * 4), 原因是一直保持着4年招收学生的人数,而每年学校招收2000人
抽象化来说:
- L :系统中的存在的物体数量
- W :物体在系统中的平均等待时间(逗留时间)
- λ:物体进入系统的速率
结合上面的案例, λ 就是大学每年招生的人数,W 就是每个学生为了毕业在学校里等待的时间(在学校这个系统里逗留的时间),L 就是目前学校里学生的总人数。 - 物体进入系统的速率是
λ个每秒(对比大学招生2000人每年) - 整个系统一共保留了
W秒的物体(对比大学里一共保留了4个年级的学生) - 因此整个系统里有
λW个物体(对比大学总共里一共有 2000 * 4 = 8000 个学生)
回到后端服务来说,L是吞吐量,W是平均请求耗时,λ是qps
如果cpu load达到80%后,过去一段时间的每秒的请求数qps * 每个请求平均耗时rt,就是最大吞吐量。如果inflight超过了这个值,就需要拒绝请求
kratos限流算法就采用了这个思路,其依靠下面 4 个指标共同确定:
- cpu:根据EWMA(指数加权平均)计算得到的cpu使用率
- EWMA会使得数据更平滑,减少噪音的干扰。同时时效性高,最新的数据有最高的权重
- inflight:系统中正在处理的请求数量
- pass: 过去一段时间的请求数
- rt:过去一段时间的请求耗时
限流算法为:
- 如果cpu利用率超过80%,进入限流判定
- 如果cpu利用率小于80%,但最近1s内触发过限流,也进入限流判定
- 限流判定:判断系统中的请求数InFlight是否大于 吞吐量阈值
(
M
a
x
P
a
s
s
∗
M
i
n
R
t
∗
b
u
c
k
e
t
P
e
r
S
e
c
o
n
d
/
1000
)
(MaxPass \ * \ MinRt \ * \ bucketPerSecond \ / \ 1000)
(MaxPass ∗ MinRt ∗ bucketPerSecond / 1000),如果是进行限流
- MaxPass:滑动窗口中,请求数最大的那个窗口的值
- MinRt:滑动窗口中,平均响应时间最小的那个窗口的值,单位毫秒
- bucketPerSecond:一秒有多少个滑动窗口
- 这样
MaxPass * bucketPerSecond就是qps,MinRt/1000就是以秒为单位的请求耗时 - 整个算式的计算结果就是过去一段时间的最大吞吐量。如果当前系统中正在处理的请求数inflight大于该值,就要限流
4. kratos限流实现
本文涉及的源码:https://github.com/go-kratos/aegis,版本:v0.2.0
4.1 cpu使用率计算
在init函数 中,启动了一个goroutine来计算 CPU使用率,这里使用了指数加权平均算法来修正偏差,其计算公式为:
c
p
u
=
c
p
u
t
−
1
∗
d
e
c
a
y
+
c
p
u
t
∗
(
1
−
d
e
c
a
y
)
cpu = cpu^{t-1} \ * \ decay + cpu^t \ * \ (1 - decay)
cpu=cput−1 ∗ decay+cput ∗ (1−decay)
其中dacay=0.95
func init() {
go cpuproc()
}
// cpu = cpuᵗ⁻¹ * decay + cpuᵗ * (1 - decay)
func cpuproc() {
ticker := time.NewTicker(time.Millisecond * 500) // same to cpu sample rate
defer func() {
ticker.Stop()
if err := recover(); err != nil {
go cpuproc()
}
}()
for range ticker.C {
stat := &cpu.Stat{}
// 获取真实的cpu使用率
cpu.ReadStat(stat)
stat.Usage = min(stat.Usage, 1000)
// 拿到上一次计算的cpu使用率
prevCPU := atomic.LoadInt64(&gCPU)
// 写入本次计算的cpu使用率
curCPU := int64(float64(prevCPU)*decay + float64(stat.Usage)*(1.0-decay))
atomic.StoreInt64(&gCPU, curCPU)
}
}
4.2 核心结构
type BBR struct {
cpu cpuGetter
// 统计请求数的滑动窗口
passStat window.RollingCounter
// 统计响应时间的滑动窗口
rtStat window.RollingCounter
// 系统正在处理的请求数
inFlight int64
// 每秒多少个桶,默认为10
bucketPerSecond int64
bucketDuration time.Duration
// 上次drop的时间
prevDropTime atomic.Value
maxPASSCache atomic.Value
minRtCache atomic.Value
opts options
}
4.3 计算maxPass
计算滑动窗口中,所有桶中pass的最大值
func (l *BBR) maxPASS() int64 {
passCache := l.maxPASSCache.Load()
if passCache != nil {
ps := passCache.(*counterCache)
// 距离上次计算不足一个时间单位,用上次计算的
if l.timespan(ps.time) < 1 {
return ps.val
}
}
// 计算所有桶中最大的pass值
rawMaxPass := int64(l.passStat.Reduce(func(iterator window.Iterator) float64 {
var result = 1.0
for i := 1; iterator.Next() && i < l.opts.Bucket; i++ {
bucket := iterator.Bucket()
count := 0.0
for _, p := range bucket.Points {
count += p
}
result = math.Max(result, count)
}
return result
}))
l.maxPASSCache.Store(&counterCache{
val: rawMaxPass,
time: time.Now(),
})
return rawMaxPass
}
4.4 计算minRT
计算滑动窗口中,所有桶中rt平均值的最小值
func (l *BBR) minRT() int64 {
rtCache := l.minRtCache.Load()
if rtCache != nil {
rc := rtCache.(*counterCache)
// 距离上次计算不足一个时间单位,用上次计算的
if l.timespan(rc.time) < 1 {
return rc.val
}
}
// 计算所有桶中最小的响应时间
rawMinRT := int64(math.Ceil(l.rtStat.Reduce(func(iterator window.Iterator) float64 {
var result = math.MaxFloat64
for i := 1; iterator.Next() && i < l.opts.Bucket; i++ {
bucket := iterator.Bucket()
if len(bucket.Points) == 0 {
continue
}
total := 0.0
for _, p := range bucket.Points {
total += p
}
avg := total / float64(bucket.Count)
result = math.Min(result, avg)
}
return result
})))
if rawMinRT <= 0 {
rawMinRT = 1
}
l.minRtCache.Store(&counterCache{
val: rawMinRT,
time: time.Now(),
})
return rawMinRT
}
4.5 maxFlight
计算最大吞吐量,等于每秒处理的请求(maxPASS() * bucketPerSecond),乘以请求在系统待了多少秒(minRT() / 1000)
其中maxPASS() 和 minRT() 根据滑动窗口动态计算
func (l *BBR) maxInFlight() int64 {
return int64(math.Floor(float64(l.maxPASS()*l.minRT()*l.bucketPerSecond)/1000.0) + 0.5)
}
4.6 Allow
接下来看限流判定Allow方法:
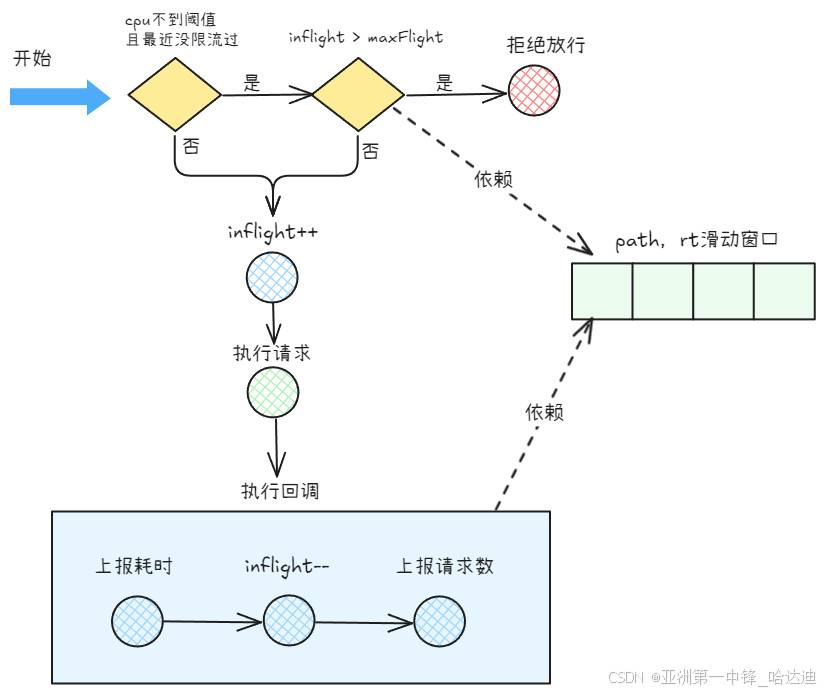
- 调
shouldDrop判断是否应该放行 - 如果可以放行,系统中的请求数
inFlight+1 - 计算当前时间作为开始执行时间
- 返回一个
func,用于请求完成后执行- 计算请求的耗时,上报到滑动窗口
- 系统中的请求数
inFlight-1 - 上报请求数+1到滑动窗口
func (l *BBR) Allow() (ratelimit.DoneFunc, error) {
if l.shouldDrop() {
return nil, ratelimit.ErrLimitExceed
}
// inFlight++
atomic.AddInt64(&l.inFlight, 1)
// 开始执行时间
start := time.Now().UnixNano()
ms := float64(time.Millisecond)
// 返回请求执行完毕后的回调方法
return func(ratelimit.DoneInfo) {
//结束执行时间
if rt := int64(math.Ceil(float64(time.Now().UnixNano()-start)) / ms); rt > 0 {
// 上报本次执行耗时
l.rtStat.Add(rt)
}
// inFlight--
atomic.AddInt64(&l.inFlight, -1)
// 请求数+1
l.passStat.Add(1)
}, nil
}
其中shouldDrop为判断是否需要限流:
- 如果cpu小于触发阈值,则判断距离上一次触发限流是否在1s内
- 在:继续判断
inFlight是否超过maxFlight(),进而执行限流 - 不在:放行请求
- 在:继续判断
- 判断
inFlight是否超过maxFlight(),如果是拒绝请求,否则放行
func (l *BBR) shouldDrop() bool {
now := time.Duration(time.Now().UnixNano())
// cpu小于触发阈值
if l.cpu() < l.opts.CPUThreshold {
// 获取上一次drop的时间
prevDropTime, _ := l.prevDropTime.Load().(time.Duration)
if prevDropTime == 0 {
return false
}
// 当前时间距离上一次drop的实现小于1s,继续执行限流逻辑
if time.Duration(now-prevDropTime) <= time.Second {
// 判断inFlight都没有超过maxInFlight
inFlight := atomic.LoadInt64(&l.inFlight)
return inFlight > 1 && inFlight > l.maxInFlight()
}
l.prevDropTime.Store(time.Duration(0))
return false
}
// cpu使用率超过阈值,执行判定限流逻辑
inFlight := atomic.LoadInt64(&l.inFlight)
drop := inFlight > 1 && inFlight > l.maxInFlight()
if drop {
prevDrop, _ := l.prevDropTime.Load().(time.Duration)
if prevDrop != 0 {
return drop
}
// 存储上一次drop时间
l.prevDropTime.Store(now)
}
return drop
}
