大端小端序概念
讲概念前,先插个小东西,之前搞混高字节、高地址、低字节、低地址这几个概念,之后理解大小端序就费劲了些。故画了下图:
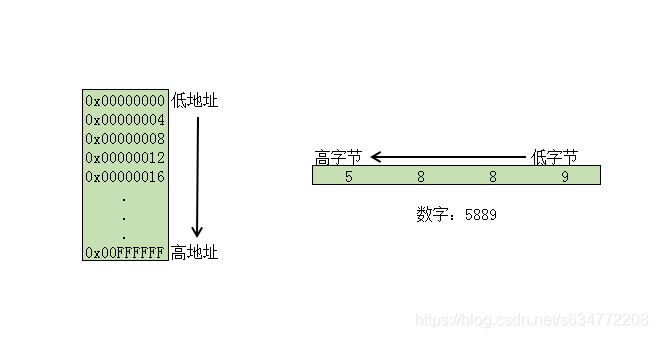
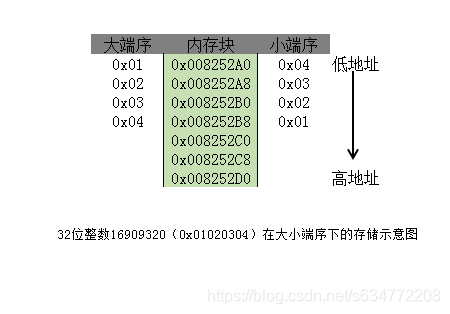
大端序(big-Endian):高字节保存在内存的低地址,低字节保存在内存的高地址。
小端序(little-Endian):高字节保存在内存的高地址,低字节保存在内存的低地址。
概念较抽象,可结合下图来理解:
大小端优缺点
存在即是合理,大端的优点就是小端的缺点,反之亦然。
大端优点:符号位在所表示数据内存的第一个字节,便于快速判断数据的正负和大小。
小端优点:内存的低地址存放数据低字节,大数强制转换小数时效率高,直接丢弃高地址数据即可;cpu在做数值运算时依次从低到高取数运算即可,效率高效。
Socket通信字节序问题
IP/TCP网络传输时采用网络字节序(即大端序),这句话常常会被误读:认为网络传输时采用的是大端序。故在编写网络程序时,常常有困惑:在创建socket或bind时,要用htonl、htons等函数来将端口或ip地址从主机字节序转换成网络字节序,而在之后的send,recv等函数中为什么就没有使用这些函数了?
经过一翻搜索之后,思路也算理清了。IP/TCP协议栈内部是遵照标准来的,使用大端序来解析数据,因为端口及ip地址在拆解协议包时要使用到,因此使用者必须将它们转化成大端序。而send,recv等函数传输的只是字节流,不关心大小端序,这些字节流是交给用户层去处理的,至于用户层如何去使用,使用的对不对,那是用户层的事情。以下是不同cpu体系平台间传输数据示意图(用户层未处理字节序时的情况,主要为了说明send,recv不关心大小端序的问题,只是传输字节流):
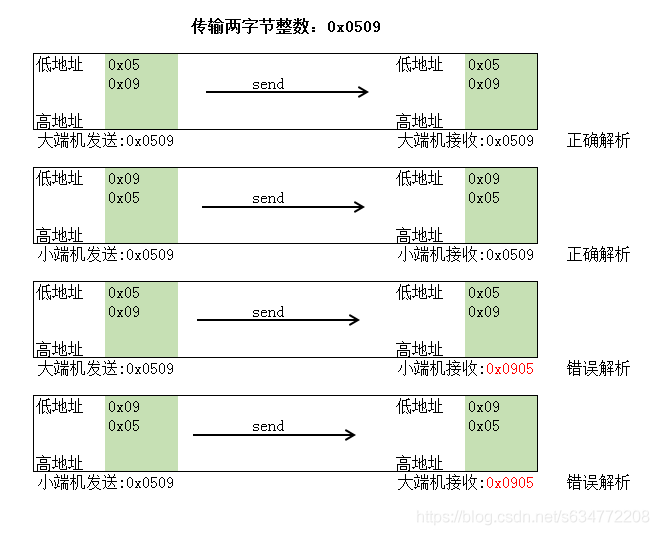
IP/TCP标准说传输时采用网络字节序,主要是为了解决不同平台之间的数据传输问题,如果要遵循这个标准的话,那么在send发送数据前就要调用htonl、htons等函数将本机字节序数据转化面网络字节序,在recv接收数据后,就要调用ntohl、ntohs等函数将网络字节序数据转化成本机字节序数据了。
因为现在大多数机器的CPU架构都是基于x86 (Intel、AMD等)体系的,故代码中就未考虑字节序的问题了(认为都是一样的字节序架构体系),故在send、recv等函数中用户层就没有再去htonl、htons、ntohl、htohs等函数了。从这可得知,若服务端运行在小端序机器,客户端运行在大端序机器,不考虑字节序问题的话,那结果就是不能工作了。
注:如果发送的是字符串,即在send前用sprintf等函数将数据全部转换成字符串,recv的也是字符串,然后在用户层自已去解析这些字符串,该转换成数字的就用atoi等函数去转换,那么就不需要去考虑网络字节序的问题了,单个字节没有字节序的问题啦。
问题拓展
为什么socket底层不帮忙处理字节序的问题的,send时,socket底层将主机字节序转换成网络字节序,然后recv时,socket底层又将网络字节序转换成主机字节序?
稍加思考,不难得出,socket不可能设计成干这事,如果要干这事,socket底层势必要知道数据流的结构才行。比如一个字节流由4个整数组成:2个字节整数,1个字节整数,1个字节整数,4个字节整数。用户层程序是知道字节流结构的,故可以挨个去调用转换,而socket 底层不知道具体的字节流构成,故无法去做转换了。
参考
https://blog.csdn.net/u014449821/article/details/80080672
https://blog.csdn.net/fysy0000/article/details/6622549
https://blog.csdn.net/qingtian506/article/details/53750398
https://www.v2ex.com/t/330173
http://blog.chinaunix.net/uid-15014334-id-4062785.html
http://www.52rd.com/Blog/Detail_RD.Blog_imjacob_17298.html
注:以上讲解完全是基于自己的理解所写,因为本人无大端序的机器,大端方面的未经实践的检验。若读者发现有错误,请务必批评指出,谢谢。
