
近日,由天翼云数据库团队、中国电信云计算研究院和深圳北理莫斯科大学合作完成的《Taste: Towards Practical Deep Learning-based Approaches for Semantic Type Detection in the Cloud》(构建云上基于深度学习的大规模语义类型识别系统)论文被28th International Conference on Extending Database Technology(EDBT)长文收录。

EDBT是数据库领域的知名国际会议,也是中国计算机学会CCF推荐的重点学术会议,已连续举办27届。此次天翼云数据库产品线所著论文被EDBT收录,代表着天翼云的科技创新能力再次获得数据库工业界和学术界的权威认可。
该论文专注于数据管理系统中的语义类型检测(Semantic Type Detection)问题的研究,并在检测性能和安全性方面实现了突破。语义类型可以显示出复杂数据的语义含义,如人名、地址、身份证号等,不仅能够帮助人类更好地理解数据,还能辅助数据管理系统提供搜索、转换和清洗等一系列关键服务,例如:数据管理系统识别出“身份证号”这一语义类型后,可将该数据标记为敏感信息,进而智能地提供数据脱敏服务。
然而,现有语义类型检测技术在每次检测时都需要扫描数据列中的具体内容,存在着两个显著弊端:一方面,扫描数据列会极大增加额外的I/O和网络开销,降低检测效率,还可能对云用户的业务产生不利影响;另一方面,扫描数据列本身耗时较长,加之基于数据列进行特征提取和推理,进一步增加了模型的处理时间,导致整体检测效率较低。伴随AI技术的迅猛发展,采用深度学习来实现语义类型检测的研究日益增加,虽在检测成功率方面取得巨大进展,但仍难以满足云环境下的大规模语义类型识别。
两项创新检测技术 实现高效精准检测
作为云服务国家队,天翼云坚持核心技术自主攻关,针对现有语义检测技术的不足,该论文创新性提出两阶段语义类型检测框架(Two-phase semantic type detection framework,简称为Taste)。
Taste框架的整体执行流程可分为两个阶段(如图1所示):第一阶段,仅利用数据源的元数据(如表名、列名、列注释等)进行初步快速的语义类型检测,以减少对数据源的扫描操作;第二阶段则是按需进行,在需要进一步确认第一阶段中不确定的语义类型时,再将列内容与元数据结合起来,完成更精确的检测。
通过两个阶段的结合,Taste不仅有效提升了检测效率,减少了对用户数据源的影响,还可在元数据质量不佳的情况下保持系统较强的鲁棒性。同时,Taste具有较强的灵活性,云上租户可根据自身的数据隐私需求选择完全禁用第二阶段,从而进一步保护数据。此外,Taste通过将每个阶段划分为数据准备和语义推理两个步骤,并利用流水线机制并行执行不同的步骤,充分利用I/O、CPU和GPU资源,显著提升了整体执行效率,可更好地适用于云环境下海量数据表和列的处理。
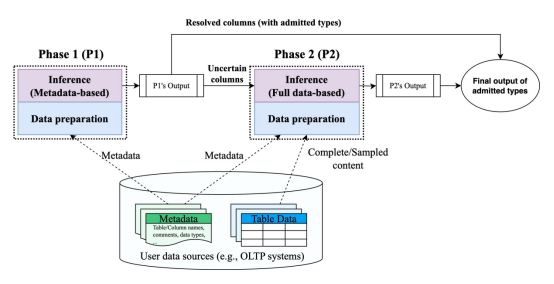
图1 两阶段语义类型检测框架概览图
此外,该论文进一步设计了一种新颖的非对称双塔检测模型(Asymmetric Double-Tower Detection,简称 ADTD),通过引入多任务学习来支持Taste的两阶段检测过程。ADTD模型结构分为Metadata塔和Content塔(如图2所示),前者是对元数据特征进行编码,后者是结合元数据信息对列内容特征进行编码。在Taste的两阶段检测中,第一阶段仅利用Metadata塔进行推理,并将Metadata塔加入到缓存中,供第二阶段使用,以减少重复推理;第二阶段则是结合Metadata塔的缓存和Content塔进行推理。在训练过程中,两个阶段的输出可以结合在一起做多任务学习,使得模型只需训练一次,即可应用于两个阶段的推理过程。
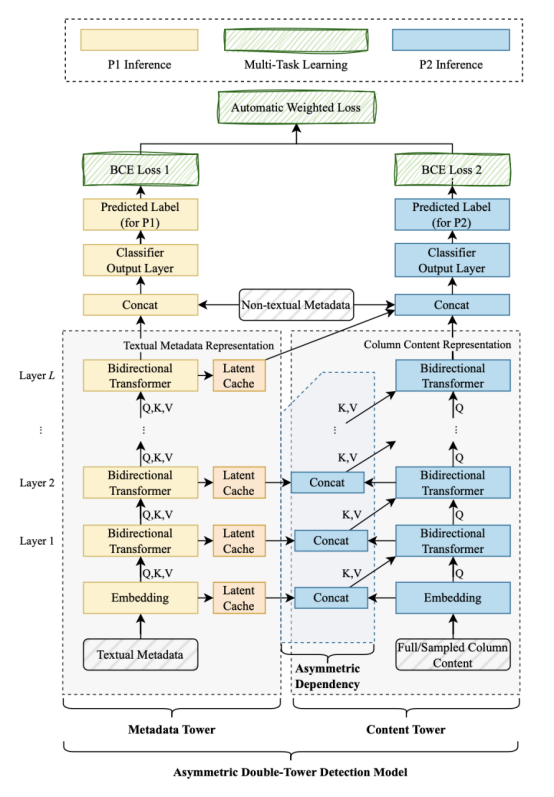
图2 非对称双塔检测模型结构图
该论文的实验表明,Taste框架在执行效率、准确性、降低数据列扫描侵入性等多个方面均表现优异,且在不同的数据隐私设置下表现出较强的鲁棒性,并具备云端大规模部署的潜力。
目前,Taste框架已在天翼云数据管理服务(DMS)进行落地。天翼云DMS是TeleDB的一款数据库工具产品,作为一站式数据生命周期管理平台,其支持多云异构数据库统一纳管,提供数据资产管理、客户端工具等功能。依托Taste框架的性能优势,天翼云DMS可帮助客户进行高效、灵活的语义类型检测,实现更加快捷且智能化的敏感数据识别,显著提升云端数据管理的安全性和稳定性,为企业充分释放数据价值提供有力支撑。
科技创新是发展新质生产力的核心要素。面向未来,天翼云将秉持央企使命责任,发挥数字中国建设主力军作用,持续推进数据库等云计算技术攻关,筑牢国云智算底座,以科技创新引领产业发展。
