reduce side join
reduce side join是一种最简单的join方式,其主要思想如下:
在map阶段,map函数同时读取两个文件File1和File2,为了区分两种来源的key/value数据对,对每条数据打一个标签> (tag),比如:tag=0表示来自文件File1,tag=2表示来自文件File2。即:map阶段的主要任务是对不同文件中的数据打标签。> 在reduce阶段,reduce函数获取key相同的来自File1和File2文件的value list,
然后对于同一个key,对File1和File2中的数据进行join(笛卡尔乘积)。即:reduce阶段进行实际的连接操作。
map side join
之所以存在reduce side join,是因为在map阶段不能获取所有需要的join字段,即:同一个key对应的字段可能位于不同map中。Reduce side join是非常低效的,因为shuffle阶段要进行大量的数据传输。 Map side join是针对以下场景进行的优化:两个待连接表中,有一个表非常大,而另一个表非常小,以至于小表可以直接存放到内存中。这样,我们可以将小表复制多 份,让每个map task内存中存在一份(比如存放到hash table中),然后只扫描大表:对于大表中的每一条记录key/value,在hash table中查找是否有相同的key的记录,如果有,则连接后输出即可。
SemiJoin
SemiJoin,也叫半连接,是从分布式数据库中借鉴过来的方法。它的产生动机是:对于reduce side join,跨机器的数据传输量非常大,这成了join操作的一个瓶颈,如果能够在map端过滤掉不会参加join操作的数据,则可以大大节省网络IO。
实现方法很简单:选取一个小表,假设是File1,将其参与join的key抽取出来,保存到文件File3中,File3文件一般很小,可以放到
内存中。在map阶段,使用DistributedCache将File3复制到各个TaskTracker上,然后将File2中不在File3中的 key对应的记录过滤掉,剩下的reduce阶段的工作与reduce side join相同。
数据准备
首先是准备好数据。这个倒已经是一个熟练的过程,所要做的是把示例数据准备好,记住路径和字段分隔符。
准备好下面两张表:
(1)m_ys_lab_jointest_a(以下简称表A)
建表语句为:
create table if not exists m_ys_lab_jointest_a (
id bigint,
name string
)
row format delimited
fields terminated by '9'
lines terminated by '10'
stored as textfile;
数据:
| id name |
(2)m_ys_lab_jointest_b(以下简称表B)
建表语句为:
create table if not exists m_ys_lab_jointest_b (
id bigint,
statyear bigint,
num bigint
)
row format delimited
fields terminated by '9'
lines terminated by '10'
stored as textfile;
数据:
| id statyear num |
我们的目的是,以id为key做join操作,得到以下表:
m_ys_lab_jointest_ab
| id name statyear num |
计算模型
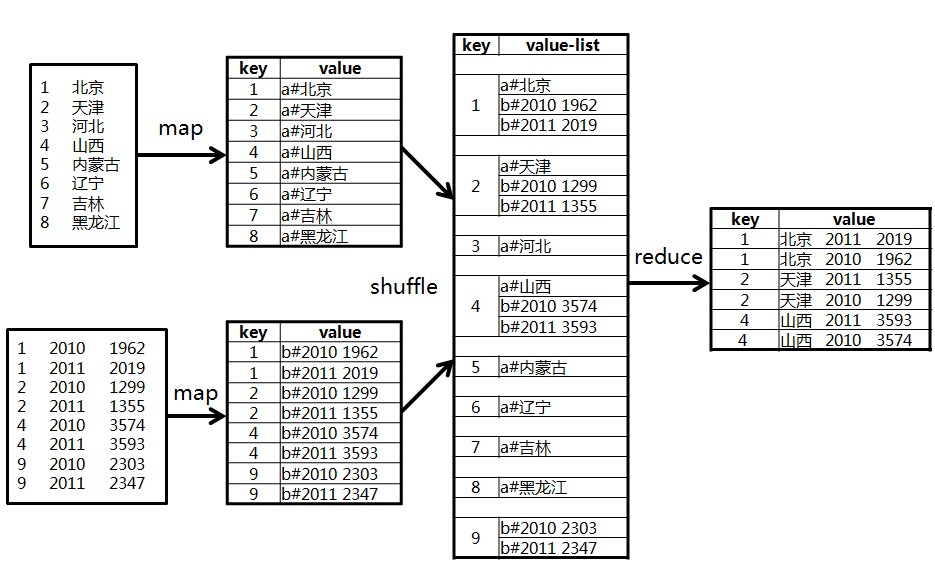
整个计算过程是:
(1)在map阶段,把所有记录标记成<key, value>的形式,其中key是id,value则根据来源不同取不同的形式:来源于表A的记录,value的值为"a#"+name;来源于表B的记录,value的值为"b#"+score。
(2)在reduce阶段,先把每个key下的value列表拆分为分别来自表A和表B的两部分,分别放入两个向量中。然后遍历两个向量做笛卡尔积,形成一条条最终结果。
如下图所示:
代码
代码如下:
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Vector;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapred.FileSplit;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.RecordWriter;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
/**
* MapReduce实现Join操作
*/
public class MapRedJoin {
public static final String DELIMITER = "\u0009"; // 字段分隔符
// map过程
public static class MapClass extends MapReduceBase implements
Mapper<LongWritable, Text, Text, Text> {
public void configure(JobConf job) {
super.configure(job);
}
public void map(LongWritable key, Text value, OutputCollector<Text, Text> output,
Reporter reporter) throws IOException, ClassCastException {
// 获取输入文件的全路径和名称
String filePath = ((FileSplit)reporter.getInputSplit()).getPath().toString();
// 获取记录字符串
String line = value.toString();
// 抛弃空记录
if (line == null || line.equals("")) return;
// 处理来自表A的记录
if (filePath.contains("m_ys_lab_jointest_a")) {
String[] values = line.split(DELIMITER); // 按分隔符分割出字段
if (values.length < 2) return;
String id = values[0]; // id
String name = values[1]; // name
output.collect(new Text(id), new Text("a#"+name));
}
// 处理来自表B的记录
else if (filePath.contains("m_ys_lab_jointest_b")) {
String[] values = line.split(DELIMITER); // 按分隔符分割出字段
if (values.length < 3) return;
String id = values[0]; // id
String statyear = values[1]; // statyear
String num = values[2]; //num
output.collect(new Text(id), new Text("b#"+statyear+DELIMITER+num));
}
}
}
// reduce过程
public static class Reduce extends MapReduceBase
implements Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterator<Text> values,
OutputCollector<Text, Text> output, Reporter reporter)
throws IOException {
Vector<String> vecA = new Vector<String>(); // 存放来自表A的值
Vector<String> vecB = new Vector<String>(); // 存放来自表B的值
while (values.hasNext()) {
String value = values.next().toString();
if (value.startsWith("a#")) {
vecA.add(value.substring(2));
} else if (value.startsWith("b#")) {
vecB.add(value.substring(2));
}
}
int sizeA = vecA.size();
int sizeB = vecB.size();
// 遍历两个向量
int i, j;
for (i = 0; i < sizeA; i ++) {
for (j = 0; j < sizeB; j ++) {
output.collect(key, new Text(vecA.get(i) + DELIMITER +vecB.get(j)));
}
}
}
}
protected void configJob(JobConf conf) {
conf.setMapOutputKeyClass(Text.class);
conf.setMapOutputValueClass(Text.class);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(Text.class);
conf.setOutputFormat(ReportOutFormat.class);
}
}
技术细节
下面说一下其中的若干技术细节:
(1)由于输入数据涉及两张表,我们需要判断当前处理的记录是来自表A还是来自表B。Reporter类getInputSplit()方法可以获取输入数据的路径,具体代码如下:
String filePath = ((FileSplit)reporter.getInputSplit()).getPath().toString();
(2)map的输出的结果,同id的所有记录(不管来自表A还是表B)都在同一个key下保存在同一个列表中,在reduce阶段需要将其拆开,保存为相当于笛卡尔积的m x n条记录。由于事先不知道m、n是多少,这里使用了两个向量(可增长数组)来分别保存来自表A和表B的记录,再用一个两层嵌套循环组织出我们需要的最终结果。
(3)在MapReduce中可以使用System.out.println()方法输出,以方便调试。不过System.out.println()的内容不会在终端显示,而是输出到了stdout和stderr这两个文件中,这两个文件位于logs/userlogs/attempt_xxx目录下。可以通过web端的历史job查看中的“Analyse This Job”来查看stdout和stderr的内容。
转载于: http://blog.csdn.net/silentwolfyh https://blog.csdn.net/silentwolfyh/article/details/50894873
