作者介绍
黄杰,2015年加入饿了么,现任框架工具部高级开发经理,主要负责饿了么的监控系统及监控系统周边的工具。
一、背景
饿了么对时序数据库的需求主要来自各监控系统,主要用于存储监控指标。原来使用的是graphite,后来慢慢对指标有了多维的需求,主要体现在对一个指标加多个Tag来组成Series,然后对Tag进行Filter和Group进行计算,这时graphite基本很难满足需求。
业界现在用的比较多的主要有如下几类TSDB:
InfluxDB:很多公司都在用,包括饿了么有部分监控系统也是用的InfluxDB。其优点在于支持多维和多字段,存储也根据TSDB的特点做了优化,不过开源的部分并不支持。很多公司自己做集群化,但大多基于指标名来,这样就会有单指的热点问题。现在饿了么也是类似的做法,但热点问题很严重,大的指标已经用了最好的服务器,可查询性能还是不够理想,如果做成按Series Sharding,那成本还是有一点高;
Graphite:根据指标写入及查询,计算函数很多,但很难支持多维,包括机房或多集群的查询。原来饿了么把业务层的监控指标存储在Graphite中,并工作的很好,不过多活之后基本已经很难满足一些需求了,由于其存储结构的特点,很占IO,根据目前线上的数据写放大差不多几十倍以上;
OpenTSDB:基于HBase,优点在于存储层不用自己考虑,做好查询聚合就可以,也会存在HBase的热点问题等。在以前公司也用基于HBase实现的TSDB来解决OpenTSDB的一些问题, 如热点、部分查询聚合下放到HBase等,目的是优化其查询性能,但依赖HBase/HDFS还是很重;
HiTSDB:阿里提供的TSDB,存储也是用HBase,在数据结构及Index上面做了很多优化,具体没有研究,有兴趣的同学可以在阿里云上试一下;
Druid:Druid其实是一个OLAP系统,但也可以用来存储时间序列数据,不过看到它的架构图时已经放弃了;
ElasticSearch(ES):也有公司直接用ES来存储,没有实际测试,但总觉得ES不是一个真正的TSDB;
atlas:Netflix出品,全内存TSDB,最近几小时数据全在内存中,历史数据需要外部存储,具体没有详细研究;
beringei:Facebook出品,同样是全内存TSDB,最近的数据也在内存,目前应该还在孵化期。
最终我们还是决定自己实现一套分布式时序数据库,具体需要解决如下问题:
轻量,目前只依赖于Zookeeper;
基于Series进行Sharding,解决热点,可以真正水平扩展;
实时写入、实时查询,由于大多用于监控系统,所以查询性能要好;
由于饿了么目前是多活,监控系统也是多活,所以要支持单机房写入,多机房聚合查询等;
要有自动的Rollup功能,如用户可以写10s的精度,系统自动Rollup到分钟、小时、天级别,以支持大时间范围的查询,如报表等;
支持类SQL的查询方式;
支持多副本,以提高整个系统的可靠性,只要还有一个副本存活就可以正常提供服务,副本数指定。
二、整体设计
采用计算和存储分离的架构,分为计算层LinProxy和存储层LinStorage。
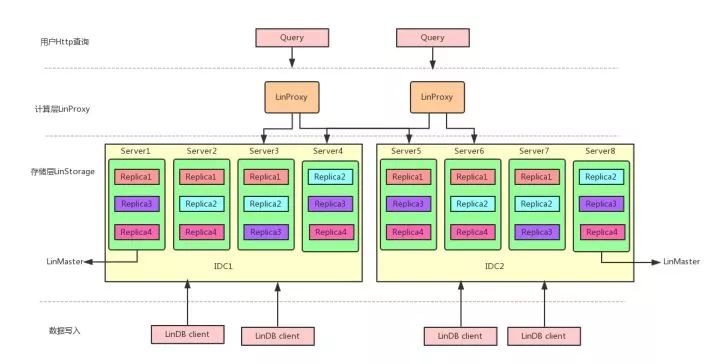
说明:
LinProxy主要做一些SQL的解析及一些中间结合的再聚合计算,如果不是跨集群,LinProxy可以不需要,对于单集群的每个节点都内嵌了一个LinProxy来提供查询服务;
LinDB Client主要用于数据的写入,也有一些查询的API;
LinStorage的每个节点组成一个集群,节点之间进行复制,并有副本的Leader节点提供读写服务,这点设计主要是参考Kafka的设计,可以把LinDB理解成类Kafka的数据写入复制+底层时间序列的存储层;
LinMaster主要负责database、shard、replica的分配,所以LinStorage存储的调度及MetaData(目前存储Zookeeper中)的管理;由于LinStorage Node都是对等的,所以我们基于Zookeeper在集群的节点选一个成为Master,每个Node把自身的状态以心跳的方式上报到Master上,Master根据这些状态进行调度,如果Master挂了,自动再选一个Master出来,这个过程基本对整个服务是无损的,所以用户基本无感知。
1、写入
整个写过程分为如下2部分组成:
WAL复制,这部分设计上参考了Kafka,用户的写入只要写入WAL成功,就认为成功(由于主要用于监控系统,所以对数据的一致性没有做太多的保证),这样就可以提供系统的写入吞吐;
本地写入,这个过程是把WAL的数据解析写入到自己的存储结构中,只有写入本地存储的数据才可以查到。
整个过程不像一些系统在每次写的过程中完成,我们是把这个过程分2步,并异步化了。
WAL复制
目前LinDB的replica复制协议采用多通道复制协议,主要基于WAL在多节点之间的复制,WAL在每个节点上的写入有独立的写操作完成,所以对于Client写入对应Leader的WAL成功就认为本次写操作是成功的,Leader所在的节点负责把相应的WAL复制到对应的Follower,同理写WAL成功认为复制成功,如下所示:
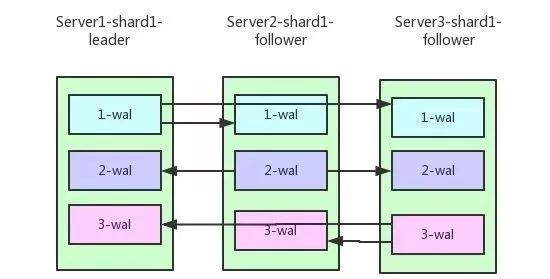
多通道复制协议
写入Leader副本成功就算成功,提高了写入速率,也带来了以下问题:
数据一致性的问题;
数据的丢失问题。
以上图Server1为Leader,3个Replication来复制1-WAL为例来说:
当前Server1是该shard的Leader接受Client的写入,Server2和Server3都是Follower接受Server1的复制请求,此时1-WAL通道作为当前的数据写入通道,Server2和Server3可能落后于Server1。
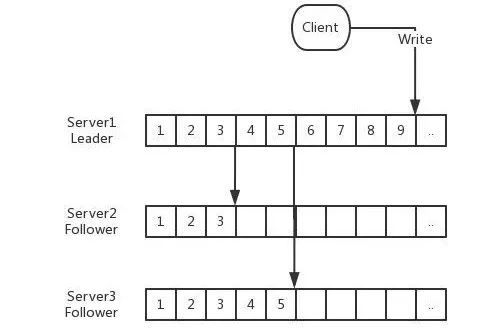
说明:
整个过程需要注意以下几个Index:
Client写入时的Append Index,表示当前Client写入到哪里;
对应每个Follower都会有一个Replica Index,表示对应Follower消费Leader上面同步到哪里;
Follower的Ack Index,表示Follower已经成功复制到本地的WAL;
对于Follower的复制请求,其实相当于一个特殊Client的写入,所以也有一个对应的Append Index。
只有被Ack过的Index,才标示为已经处理完成,对于Leader来说,小于最小的Ack Index的WAL数据是可以被删除。在这个过程中,如果Server2或者Server3中有一台出问题,这时对应的Consume Index不会移动,只有等到相应服务恢复之后才会继续处理。
在整个过程中可能出现如下情况:
Leader Replica Index > Follower Append Index,这时需要根据Follower Append Index重置Leader Replica Index,可能存在2种情况,具体情况在复制顺序性中描述;
Leader Replica Index < Follower Append Index,也同样存在2种情况,具体情况在复制顺序性中描述。
假如此时Server1挂了,从Server2和Server3中选出新的Leader,如此时选为Server2为Leader:
Server2就会开启2-WAL复制通道,向Server1和Server3复制,由于当前Server1挂了,所以暂时只往Server3复制,此时数据的写入通道为2-WAL;
Server1启动恢复后,Server2会开启向Server1的2-WAL复制通道,同时Server1会将1-WAL中剩余的还未向Server2和Server3复制的数据复制给它们。
对于异常情况,WAL中的数据不能正常,由于ACK之后删除导致WAL占用过多磁盘,所以对WAL需要有一个SIZE和TTL的清理过程,一旦WAL因为SIZE和TTL清理之后,会导致几个Index错乱,具体错乱情况如上所述。
多通道复制协议带来的问题:
每个通道都有对应的Index序列,保存每个通道的Last Index。而单通道复制只需要保存1个Last Index即可。这个代价其实还好。
本地写入
背景
做到Shard级别的写入隔离,即每个Shard都会有独立的线程来负责写入,不会因为某个数据库或者某个Shard写入量剧增而导致别的数据库的写入,但可能会因为单机承载的Shard数过多导致线程数过多。如果遇到这种情况,应该通过扩机器来解决,或者在新建数据库的时候合理分配Shard数。
由于是单线程的写操作,所以在很多情况下,不需要考虑多线程写带来的锁竞争问题。
数据存储结构

说明,以单个数据库在单节点上的数据结构为例:
一个数据库在单节点上会存在多个Shard,所有Shard共享一个索引数据;
所有的数据根据数据库的Interval来计算按时间片,存储具体的数据,包括数据文件和索引文件。
这样的设计主要为了方便处理TTL,数据如果过期,直接删除相应的目录就可以。每个Shard下面会存在segment,segment根据Interval来存储相应时间片的数据。
那么为什么每个segment下面又按Interval存储很多个data family?
这个主要由于LinDB主要解决的问题是存储海量的监控数据,一般的监控数据基本是最新时间写入,不会写历史数据,而整个LinDB的数据存储类似LSM方式,所以为了减少数据文件之间的合并操作导致写放大,最终衡量下来,再对segment时间片进行分片。
下面以Interval为10s为例说明:
segment按天来存储;
每个segment按小时来分data family,每个小时一个family,每个family中的文件再按列存储具体的数据。
写入流程
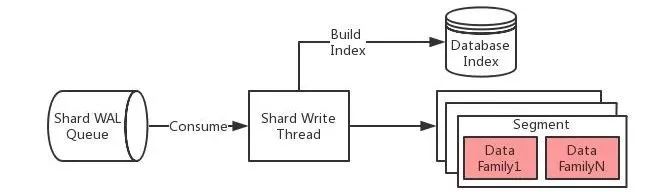
说明:
系统会为每一个Shard启一个写线程,该线程负责这个Shard的所有写操作。
首先把measurement,tags,fields对应的数据写入数据库的索引文件,并生成相应的Measurement ID,Time Series ID及Field ID,主要完成string->int的转换。这样的好处是所有的数据存储都以数据类型来存储,从而可以减少整个存储大小。因为对于每个数据点,Measurement,Tags,Field这样元数据占用,如cpu{host=1.1.1.1} load=1 1514214168614,其实转换成ID之后,cpu => 1(measurement id),host=1.1.1.1 => 1(time series id),load => 1(field id),所以最终的数据存储为1 1 1514214168614=>1,这个考虑OpenTSDB的设计。
如果写索引失败,认为本次写入失败。失败分为2种,一种是数据写入格式有问题,这类失败直接标示失败;另外一种由于内部问题,这时写入失败需要重试。
使用根据索引得到的ID,再结合写入时间和数据库Interval计算,得到需要写入到哪个segment下的哪个family,写family的过程,直接写内存以达到高吞吐量的要求,内存数据到达内存限制之后,会触发Flush操作。
整个写过程先写内存,再由Flusher线程把内存中的数据dump到相应的文件中,这样就做到了对一批数据顺序写入,同时对于最近的数据根据Field Type进行Rollup操作,从而进一步减少磁盘IO操作。
2、查询引擎
LinDB查询需要解决如下问题:
解决多个机房之间的查询;
高效的流式查询计算。
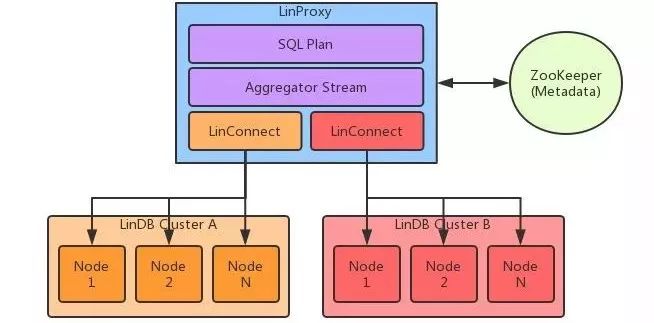
说明:
由于需要支持多机房或者多集群的查询,所以引入了LinProxy,LinProxy主要负责面向用户的查询请求;
SQL Plan负责具体SQL的解析,生成最终的执行计划及需要计算的中间结果的函数;
通过Zookeeper中的Metadata,把请求路由给具体的LinDB集群中对应的服务;
每个LinConnect负责与一个LinDB集群之间的通信,每个LinConnect内部保存了一份对应集群的Metadata,该Metadata信息在每个Metadata变更的时候由Server端推送给LinConnect,这样LinConnect基本做到近实时的更新Metadata;
Aggregator Stream主要负责把各个LinConnect的中间结果进行最终的合并计算操作;
整个LinProxy处理过程都是异步化,这样可以利用线程在IO等待的时候做计算。
每个Node接收LinConnect过来的请求,在内部查询计算成中间结果返回给LinConnect,详细的过程后面要介绍。
Node查询
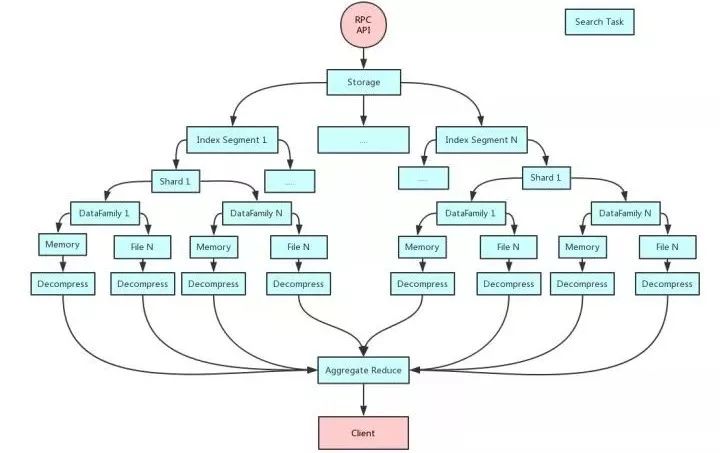
说明:
如图所示,Client过来的一个查询请求,会产生很多小的查询任务,每个任务所承担的职责很单一,只做它所自己的任务,然后把结果给下一个任务,所以需要所有的查询计算任务都是异常无阻塞处理,IO/CPU任务分离;
整个服务端查询使用Actor模式来简化整个Pipeline的处理;
任何一个任务执行完成,如果没有结果产生,则不会生产下游的任务,所有下游的任务都是根据上游任务是否有结果来决定;
最终把底层结果通过Reduce Aggregate聚合成最终的结果。
3、存储结构
倒排索引
倒排索引分两部分,目前索引相关的数据还是存储在RocksDB中。
根据Time Series的Measurement+Tags生成对应的唯一ID(类似Luence里面的doc ID);
根据Tags倒排索引,指向一个ID列表。TSID列表以BitMap的方式存储,以方便查询的时候通过BitMap操作来过滤出想要的数据。BitMap使用RoaringBitMap;
每一类数据都存储在独立的RocksDB Family中。
内存结构
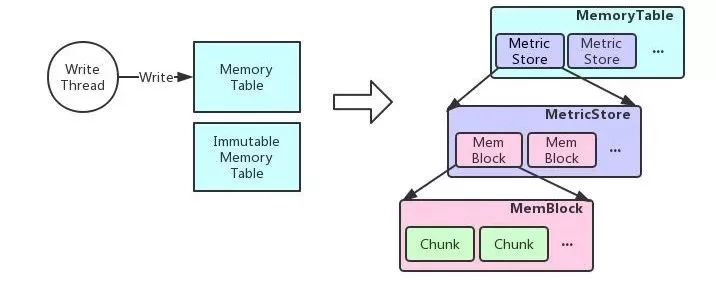
为了提高写入性能,把当前一段时间的数据写入到内存中,内存到达一定限制或者时间后把内存中的数据Dump到文件中。
内存存储分为当前可写和不可写,当前可写用于接收正常的数据写入,不可写用于Dump到文件中,如果Dump成功,则清空不可写部分。
如果可写的Memory Table也到达了内存容量的限制,但不可写部分还没有完成Dump,这时写入会被Block住,直到有可用的内存供数据写入,目的是为了不会因为占用过多内存而导致OOM。
MemoryTable内部通过一个Map来存储Measurement ID→Measurement Store关系,即每个Measurement都存储在一个独立的Store中。
在Measurement Store内存储对应Measurement下面每个TSID的数据,每个TSID对应的数据用一个Memory Block来存储,每个Memory Block按TSID的顺序存储在Array List中,把TSID存储在一个BitMap中,通过TSID在Bitmap中位置来定位Memory Block在Array List中的具体位置。
这里说明一下为什么不直接使用Map来存储,因为整个系统是用Java实现的,Java中的Map结构不适合存储小对象的数据,存在内存放多倍的存储。
由于每个TSID都会对应一个时间线,每个时间线可能会存在多个数据点的情况,如count时只有一个count值,timer时会有count、sum、min、max等多个值。
每个数据类型以Chunk的方式存储。Chunk内部又以堆内和堆外2部分内存来存储,最近一段时间的数据放在堆内,历史数据压缩之后放在堆外,在内存中尽量多放一些最近的数据,因为LinDB的目的主要是存储一些监控类的数据,而监控类的数据主要关心最近一段时间的数据。
文件存储结构
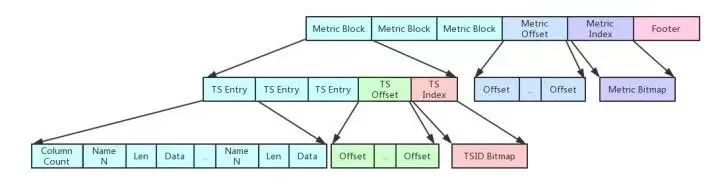
文件存储跟内存存储类似,同一个Measurement的数据以Block的方式存储在一起,查询时通过Measurement ID定位出该Measurement的数据存储在哪个Block中。
Measurement Block后存储一个Offset Block,即存储每个Measurement Block所在的Offset,每个Offset以4 bytes存储。
Offset Block存储一个Measurement Index Block,按顺序存储每个Measurement ID,以Bitmap的方式存储。
文件的尾存储一个Footer Block,主要存储Version(2 bytes) + Measurement Index Offset(4 bytes) + Measurement Index Length(4 bytes)。
Data数据块都是数值,所以使用xor压缩,参考facebook的gorilla论文;
Measurement Block:
每个Measurement Block类似Measurement的方式存储,只是把Measurement ID换成Measurement内的TSID。
TS Entry存储该TSID对应每一列的数据,一列数据对应存储一段时间的数据点。
查询逻辑:
DataFile在第一次加载的时候会把Measurement Index放在内存中,查询输入Measurement ID通过Measurement Index中的第几个位置,然后通过这个位置N,在Offset Block查询具体的Measurement Block的Offset,由于每个Offset都是4 bytes,所以offset position = (N-1) * 4,再读取4 bytes得到真正的Offset。
同样的道理可以通过TSID,找到具体的TS Entry,再根据条件过滤具体的列数据,最终得到需要读取的数据。
三、发展历程
LinDB从2年前正式慢慢服务于公司的监控系统起,从1.0发展到2.0,已经稳定运行2年多,除了一次RocksDB的问题,几乎没出过什么问题。到现在,3.0性能大幅提升,我们基本都是站在业界一些成熟方案的基础上,慢慢演进而来。
也有人问,LinDB为什么这么快,其实我们是参考了很多TSDB的作法,然后取其好的设计,再结合时序的特征做一些优化。
时序一般都是最新写入,但也是一种随机写,我们会先在内存中把随写变成循序写,最终到写文件都是顺序写,所有数据都是有序,这样查询的时候也是顺序读,这一点很关键;
把写入的measurement/tags/fields都转化成Int,再生成倒排索引,最终生成一个TSID(类似Luence的doc ID),这样就大大减少了最终的数据量,毕竟指标这样字符串是占绝对的大头,这点很像OpenTSDB,虽然InfluxDB已经把一段时间的按Block来存储,但还是在Block的头放这些数据,这些都是成本,特别是在compact的时候;
不像别的TSDB会把timestamp直接存下来,一般timestamp到毫秒级别占8个节点,虽然根据时间有序的优势再用delta-encoded压缩也是很好,但我们想做到极致,我们是用一个bit来表示时间,具体的做法就是根据上面的描述,把时间的高位和存储Interval,把高位的时间放在目录上,再结合高位算一个delta,把delta以1bit的格式存储,来表示有没有数据,因为监控数据绝大部分都是连续的数据, 所以这样做也是合理的,因此在时间这个数据上的存储也大大减少了空间;
我们发现对一个指标的多个Field的数据,每个Field的数据相邻的一些点基本是很相近的,LinDB 2.0存储直接是用RocksDB,多个Field放在一起存储,再把相邻的点进行压缩,这样其实压缩率不会很高, 而且每取查询取Field的时候都要把所有的数据读出来,这也是LinDB 3.0我们考虑自己实现列式存储的原因。我们把相同列存在一块,以提高压缩率,查询的时候只读需要的数据。整个压缩我们也没有用gzip、snappy、zlib,因为这些不大适合用于数值类型,我们是直接参考了facebook的gorilla论文的xor的方式来的,这个现在已经被很多TSDB采用;
基于上面这些基本的顺序读已经不成问题,基于TSID查询的更不是问题,因为整个设计都是基于TSID→data来设计的,所以还要解决一个根据倒排查出一组TSID对数据的随机读,如上我们是把TSID放在Bitmap,然后通过Bitmap计算出Offset,直接找到数据,通过存储时的优化,做到TSID查询精准查找,而不是通过二分查找;
还有一点就是LinDB在新建数据库时指定完Interval之后,系统会自己Rollup,不像InfluxDB要写很多Continue Query,LinDB所有的这一切都是自动化的;
查询计算并行流式处理。
所以用一句话来总结就是——一个高效的索引外加一堆数值,然后怎么玩好这堆数值。
自身监控
LinDB也自带了自身的一些监控功能:
Overview
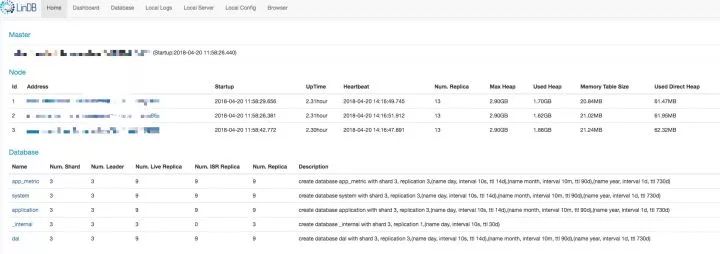
Dashboard
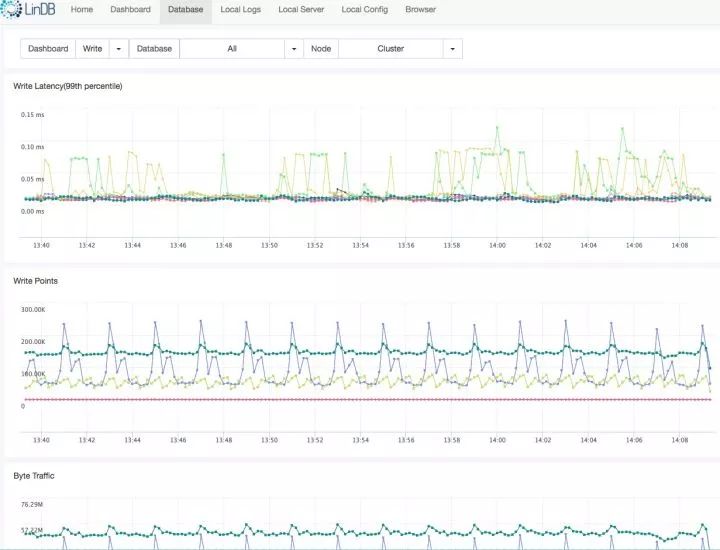
未来的展望
丰富查询函数;
优化内存使用率;
自身监控的提升;
如果有可能,计划开源。
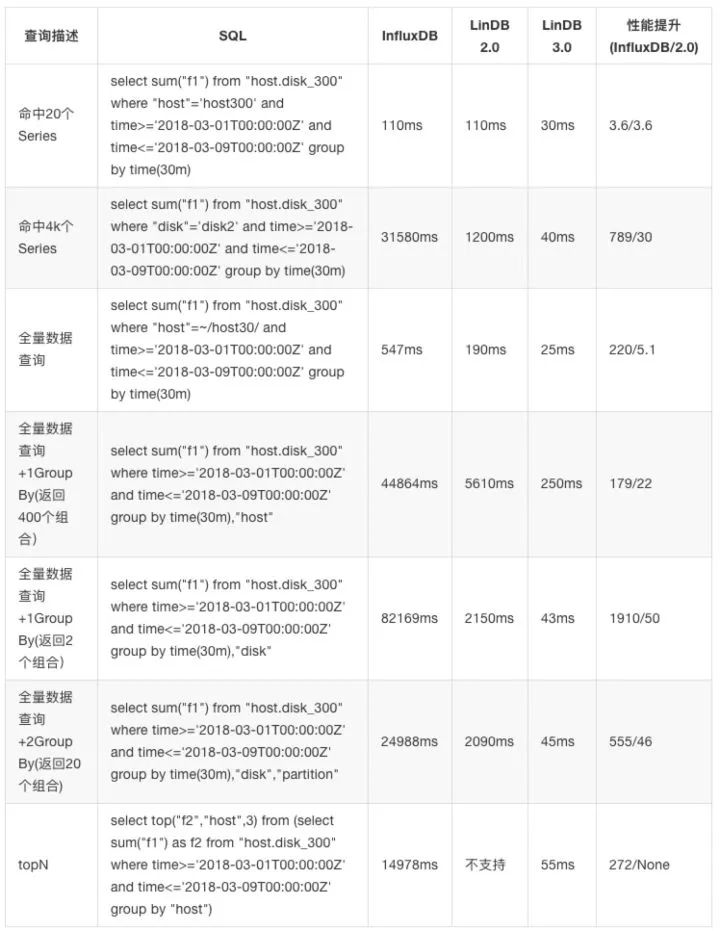
对比测试
下面是与InfluxDB和LinDB2.0的一些查询性能对比。由于InfluxDB集群化要商业版,所以都是单机默认配置下,无Cache的测试。服务器配置阿里云机器:8 Core 16G Memory
大维度
Tags:host(40000),disk(4),partition(20),模拟服务器磁盘的监控,总的Series数为320W,每个Series写一个数据点:
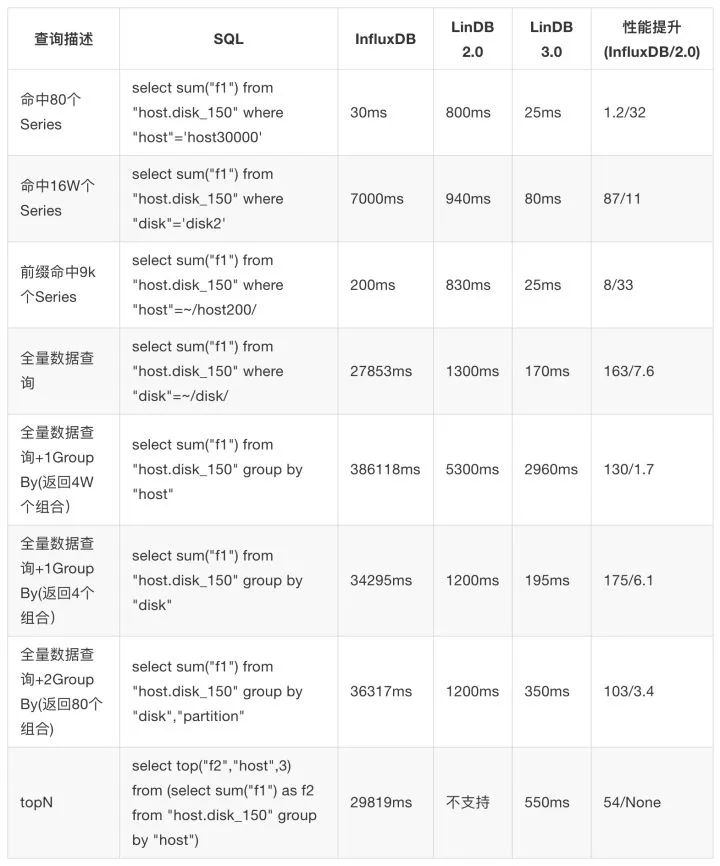
小维度的1天内的聚合测试
Tags:host(400),disk(2),partition(10),模拟服务器磁盘的监控,总的Series数为8K,每个Series写一天的数据 每个维度每2s写入1个点,每个维度一天内总共43200个点,所有维度总共43200 * 8000个点,共345600000即3亿多数据:
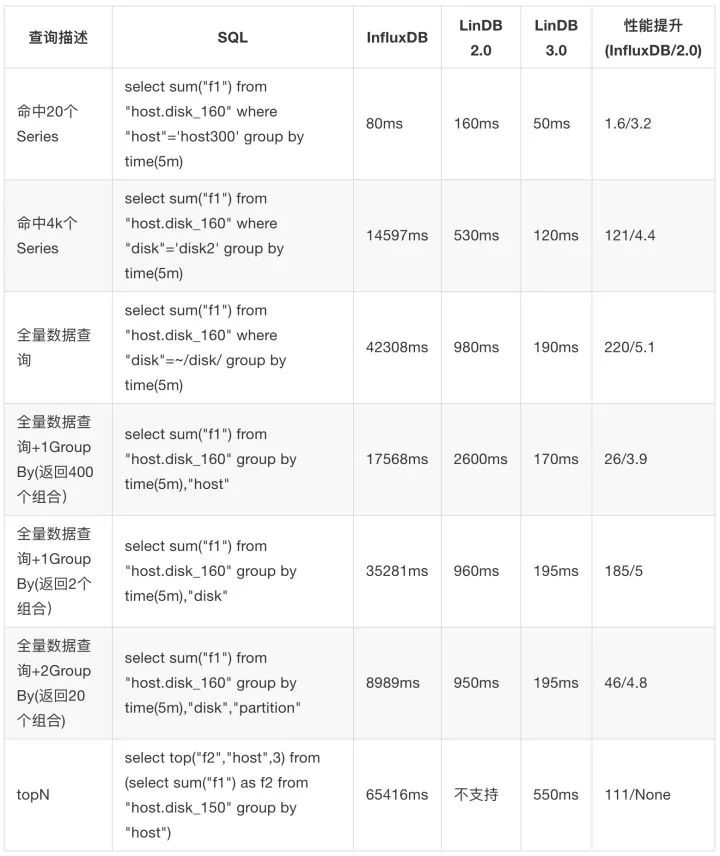
小维度的7天内的聚合测试
Tags:host(400),disk(2),partition(10),模拟服务器磁盘的监控,总的Series数为8K,每个Series写7天的数据,每个维度每5s写入1个点,每个维度一天内总共17280个点,所有天数所有维度总共172808000 7 个点,即967680000,9亿多个点。
这个测试要说明一下,得利于LinDB自动的Rollup,如果InfluxDB开Continue Query的话相信应该也还好。
引用
Time Series-Measurement+Tags 组成一个唯一组合,加上时间最终组全一个series。
TSID-每个time series(measurement + tags)都会生成一个唯一的ID。
RoaringBitMap. http://roaringbitmap.org/
Druid.http://druid.io/docs/0.12.0/design/segments.html
InfluxDB TSM.
https://docs.influxdata.com/influxdb/v1.5/concepts/storage_engine/
Gorilla-A Fast, Scalable, In-Memory Time Series Database.
http://www.vldb.org/pvldb/vol8/p1816-teller.pdf
beringei. https://github.com/facebookincubator/beringei返回搜狐,查看更多
责任编辑:
平台声明:该文观点仅代表作者本人,搜狐号系信息发布平台,搜狐仅提供信息存储空间服务。
阅读 ()
