
本文分享自天翼云开发者社区《分布式系统心跳机制(一)》,作者:白杨
分布式系统架构
当前大部分分布式系统架构如下图:
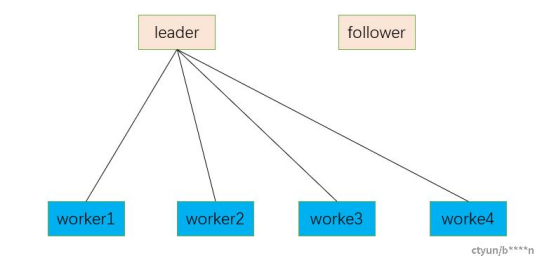
有一个中心节点来存储集群元数据和管理work儿节点,中心节点采用主备模式来实现HA。当中心节点主故障后,备节点接管业务成为主节点。我们下面讨论的心跳机制就是基于这种分布式架构而设计的。
心跳设计目标:
1.master控制节点的切换,不可以影响server的心跳。
2.server可以感知到master的每一次切换。
3.master在任意场景下都不会丢失server故障的事件。
4.心跳可以作为其它控制消息是否需要重试的依据。
心跳Clien端设计:
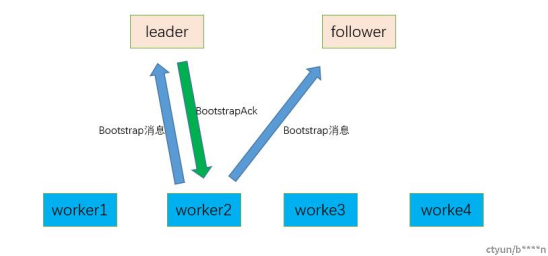
a.worker2启动后只有master的列表,并不知道哪个是leader,因此先广播bootstrap信息。
b.只有leader节点响应bootstrap信息,leader生成session id并持久化,返回bootstrap ack 给worker2,标记worker2为Up。
c.worker2收到ack信息本地记录leader的epoch,sessionid等信息作为后续发送心跳的凭证,并进入connected状态。
d.bootstrap ack消息还需要携带,心跳超时时间,假心跳超时时间。
假心跳超时:假心跳超时的时间一般小于心跳超时的时间,例如:心跳超时的时间为5s,假心跳超时的时间就为3s。这主要是为了识别leader切换,当到了假心跳超时时间后,worker将开始广播心跳,尝试连接到新的leader,在心跳超时时间内连接上新的leader则对外是无感知的。
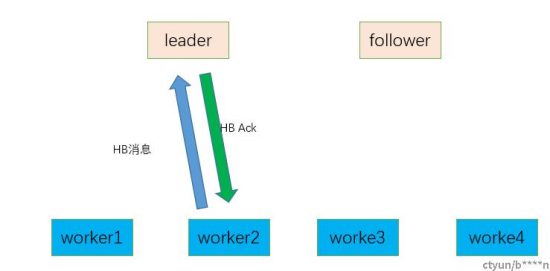
a.worker2进入connected状态后,后续定期发送HB消息给leader,leader返回ACK。
b.如果这时候leader故障了,follwer变成leader,超过假心跳超时时间后将会触发心跳广播。
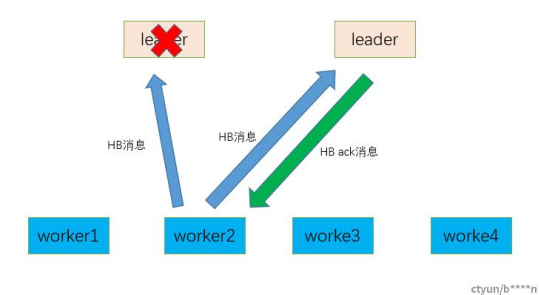
a.leader故障后,新的leader接管了业务,并且从持久化存储中load起worker2的相关信息,主要是sessionid信息。
b.worker2到达假心跳时间后意识到旧leader可能故障,因此开始广播心跳寻找新的leader。
c.新的leader收到worker2的信息,并且比对sessionid是一致的则接收并返回hb ack。
d.worker2收到新的HB ack后更新新的leader地址与epoch信息,整个流程对外是透明的。
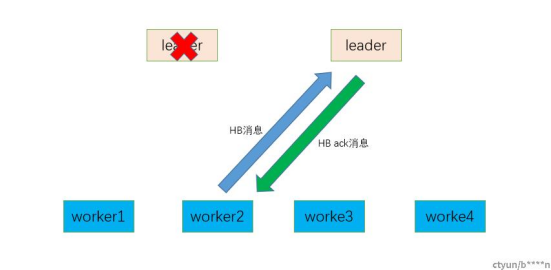
a.worker2找到新leader后,不再广播心跳而是单一的给leader发送。
