概述
数据的价值在于把数据变成行动。这里一个非常重要的过程是数据分析。提到数据分析,大部分人首先想到的都是Hadoop、流计算、机器学习等数据加工的方式。从整个过程来看,数据分析其实包含了4个过程:采集,存储,计算,展示。大数据的数据采集工作是大数据技术中非常重要、基础的部分,具体场景使用合适的采集工具,可以大大提高效率和可靠性,并降低资源成本。Flume、Logstash和Filebeat都是可以作为日志采集的工具,本报告将针对这三者进行分析。
一、Flume
Flume是一种分布式、高可靠和高可用的服务,用于高效地收集、聚合和移动大量日志数据。它有一个简单而灵活的基于流数据流的体系结构。它具有可调的可靠性机制、故障转移和恢复机制,具有强大的容错能力。它使用一个简单的可扩展数据模型,允许在线分析应用程序。
Flume介绍
Flume的设计宗旨是向Hadoop集群批量导入基于事件的海量数据。系统中最核心的角色是agent,Flume采集系统就是由一个个agent所连接起来形成。每一个agent相当于一个数据传递员,内部有三个组件:
source: 采集源,用于跟数据源对接,以获取数据
sink:传送数据的目的地,用于往下一级agent或者最终存储系统传递数据
channel:agent内部的数据传输通道,用于从source传输数据到sink
flume配置
Flume的配置是在conf下以.conf结尾的文件
vim conf/test.conf
# 分别为 起别名
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
# 配置source
a1.sources.r1.type = netcat
# 数据来源的方式:
# bind:ip,此ip必须是本机,ip:如果换成0.0.0.0(木有限制)
a1.sources.r1.bind = localhost
# 端口号是44444
a1.sources.r1.port = 44444
# Describe the sink
# 配置的是sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
#配置channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
# 将source,和channel绑定起来
a1.sources.r1.channels = c1
# 将sink和channel绑定起来
a1.sinks.k1.channel = c1flume启动
bin/flume-ng agent -conf conf --conf-file conf/test.conf --name a1 -Dflume.root.logger=INFO,console二、Logstash
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到存储库中。数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
Logstash介绍
logstash是基于pipeline方式进行数据处理的,pipeline可以理解为数据处理流程的抽象。在一条pipeline数据经过上游数据源汇总到消息队列中,然后由多个工作线程进行数据的转换处理,最后输出到下游组件。一个logstash中可以包含多个pipeline。
Logstash管道有两个必需的元素,输入和输出,以及一个可选元素过滤器:
Input:数据输入组件,用于对接各种数据源,接入数据,支持解码器,允许对数据进行编码解码操作;必选组件;
output:数据输出组件,用于对接下游组件,发送处理后的数据,支持解码器,允许对数据进行编码解码操作;必选组件;
filter:数据过滤组件,负责对输入数据进行加工处理;可选组件;Logstash安装部署
pipeline:一条数据处理流程的逻辑抽象,类似于一条管道,数据从一端流入,经过处理后,从另一端流出;一个pipeline包括输入、过滤、输出3个部分,其中输入和输出部分是必选组件,过滤是可选组件;instance:一个Logstash实例,可以
包含多条数据处理流程,即多个pipeline;
event:pipeline中的数据都是基于事件的,一个event可以看作是数据流中的一条数据或者一条消息;
Logstash配置
vim logstash.conf
#监听端口发送数据到kafka
input {
tcp{
codec => "json"
host => "192.168.1.101"
port => "8888"
}
}
filter{
filter{
mutate{
split => ["message","|"]
add_field => {
"tmp" => "%{[message][0]}"
}
add_field => {
"DeviceProduct" => "%{[message][2]}"
}
add_field => {
"DeviceVersion" => "%{[message][3]}"
}
add_field => {
"Signature ID" => "%{[message][4]}"
}
add_field => {
"Name" => "%{[message][5]}"
}
}
}
output {
kafka{
topic_id => "hello"
bootstrap_servers => "192.168.1.101:9092"
}
}Logstash启动
bin/logstash -f logstash.conf三、Filebeat
Filebeat是一个日志文件托运工具,在服务器上安装客户端后,Filebeat会监控日志目录或者指定的日志文件,追踪读取这些文件(追踪文件的变化,不停的读),并且转发这些信息到ElasticSearch或者Logstarsh中存放。
当你开启Filebeat程序的时候,它会启动一个或多个探测器(prospectors)去检测你指定的日志目录或文件,对于探测器找出的每一个日志文件,Filebeat启动收割进程(harvester),每一个收割进程读取一个日志文件的新内容,并发送这些新的日志数据到处理程序(spooler),处理程序会集合这些事件,最后filebeat会发送集合的数据到你指定的地点。
Filebeat介绍
Filebeat由两个主要组成部分组成:prospector和 harvesters。这些组件一起工作来读取文件并将事件数据发送到指定的output。
Harvesters:负责读取单个文件的内容。harvesters逐行读取每个文件,并将内容发送到output中。每个文件都将启动一个harvesters。harvesters负责文件的打开和关闭,这意味着harvesters运行时,文件会保持打开状态。如果在收集过程中,即使删除了这个文件或者是对文件进行重命名,Filebeat依然会继续对这个文件进行读取,这时候将会一直占用着文件所对应的磁盘空间,直到Harvester关闭。默认情况下,Filebeat会一直保持文件的开启状态,直到超过配置的close_inactive参数,Filebeat才会把Harvester关闭。
Prospector:负责管理Harvsters,并且找到所有需要进行读取的数据源。如果input type配置的是log类型,Prospector将会去配置路径下查找所有能匹配上的文件,然后为每一个文件创建一个Harvster。每个Prospector都运行在自己的Go routine里。
Filebeat目前支持两种Prospector类型:log和stdin。每个Prospector类型可以在配置文件定义多个。log Prospector将会检查每一个文件是否需要启动Harvster,启动的Harvster是否还在运行,或者是该文件是否被忽略(可以通过配置 ignore_order,进行文件忽略)。如果是在Filebeat运行过程中新创建的文件,只要在Harvster关闭后,文件大小发生了变化,新文件才会被Prospector选择到。
Filebeat配置
Filebeat配置相比较为复杂,可以参考 Filebeat 收集日志的那些事儿
四、Flume、Logstash、Filebeat对比
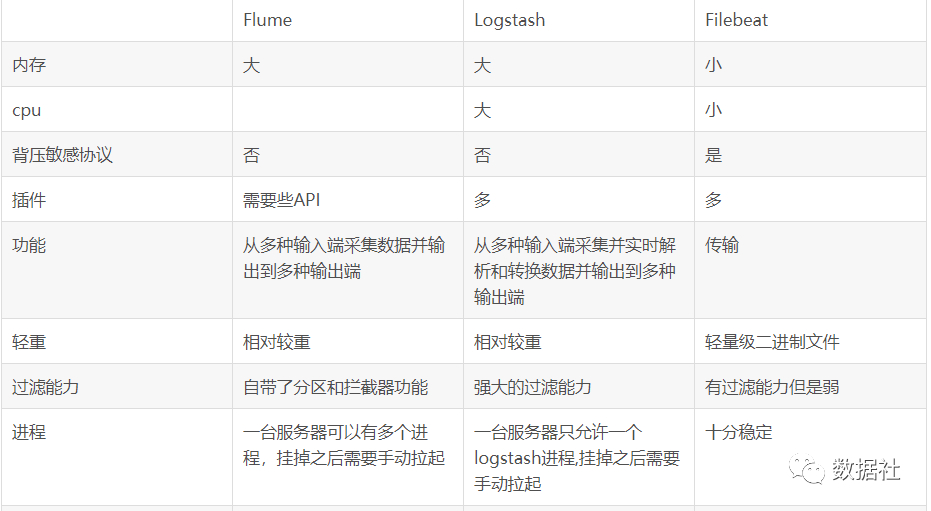
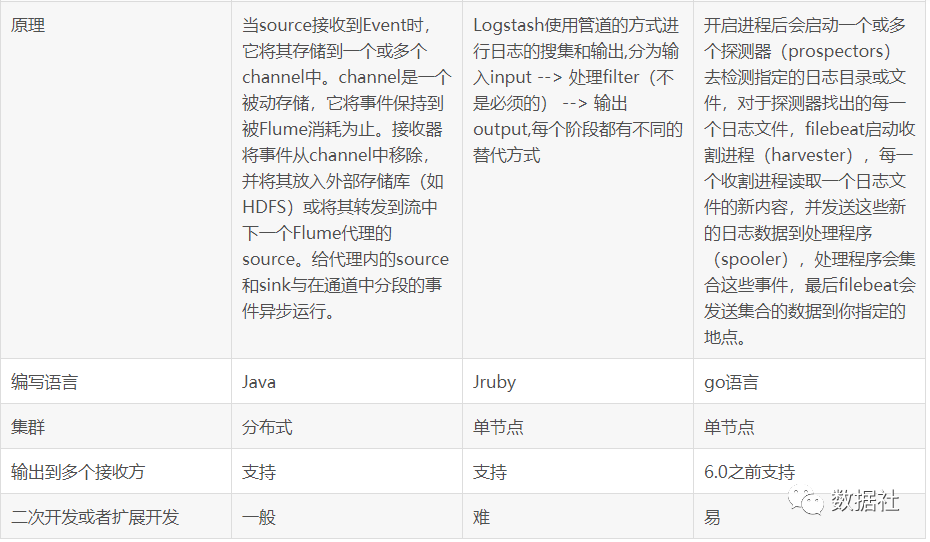
总结
Flume更注重于数据的传输,对于数据的预处理不如Logstash。在传输上Flume比Logstash更可靠一些,因为数据会持久化在channel中。数据只有存储在sink端中,才会从channel中删除,这个过程是通过事物来控制的,保证了数据的可靠性。Logstash是ELK组件中的一个,一般都是同ELK其它组件一起使用,更注重于数据的预处理,Logstash有比Flume丰富的插件可选,所以在扩展功能上比Flume全面。但Logstash内部没有persist queue,所以在异常情况下会出现数据丢失的问题。Filebeat是一个轻量型日志采集工具,因为Filebeat是Elastic Stack的一部分,因此能够于ELK组件无缝协作。Filebeat占用的内存要比Logstash小很多。性能比较稳健,很少出现宕机。
历史好文推荐
- Kafka实战宝典:一文带解决Kafka常见故障处理
- Kafka实战宝典:监控利器kafka-eagle
- Kafka实战宝典:如何跨机房传输数据
- 谈谈ETL中的数据质量
