前言
其实我之前是不太了解时序数据库以及它相关的机制的,只是大概知晓它的用途。但因为公司的业务需求,我意外参与并主导了公司内部开源时序数据库influxdb的引擎改造,所以我也就顺理成章的成为时序数据库“从业者”。
造飞机的人需要时刻理解开飞机的人的需求。我不算时序数据库的使用者,但我想站在用户的角度去思考,他们需要一款怎样的“时序数据库”,我司的influxdb的第一阶段改造已经完成,所以我写下这篇文章,总结一下自己在开发中的一些思考与想法。也许有些地方还不够成熟,但胜在人会慢慢进步。
正文
一、几款优秀的时序数据库
Prometheus、Influxdb和opentsdb是三款业内比较知名且实际生产使用的时序数据库了,总的来说三款各有优缺点,这里不谈它们的性能,主要谈谈使用和生态。
Influxdb:目前开源排名最高的时序数据库,是单独的数据库,主要就是用来写入和查询数据。目前集群版已经闭源商业化,开源版仅支持单机模式。数据采集使用push模式(数据源主动将数据写入influxdb)。优势是提供类SQL的查询引擎。
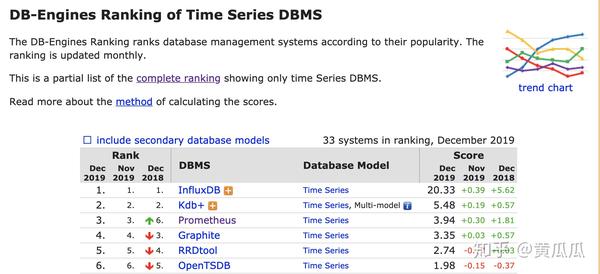
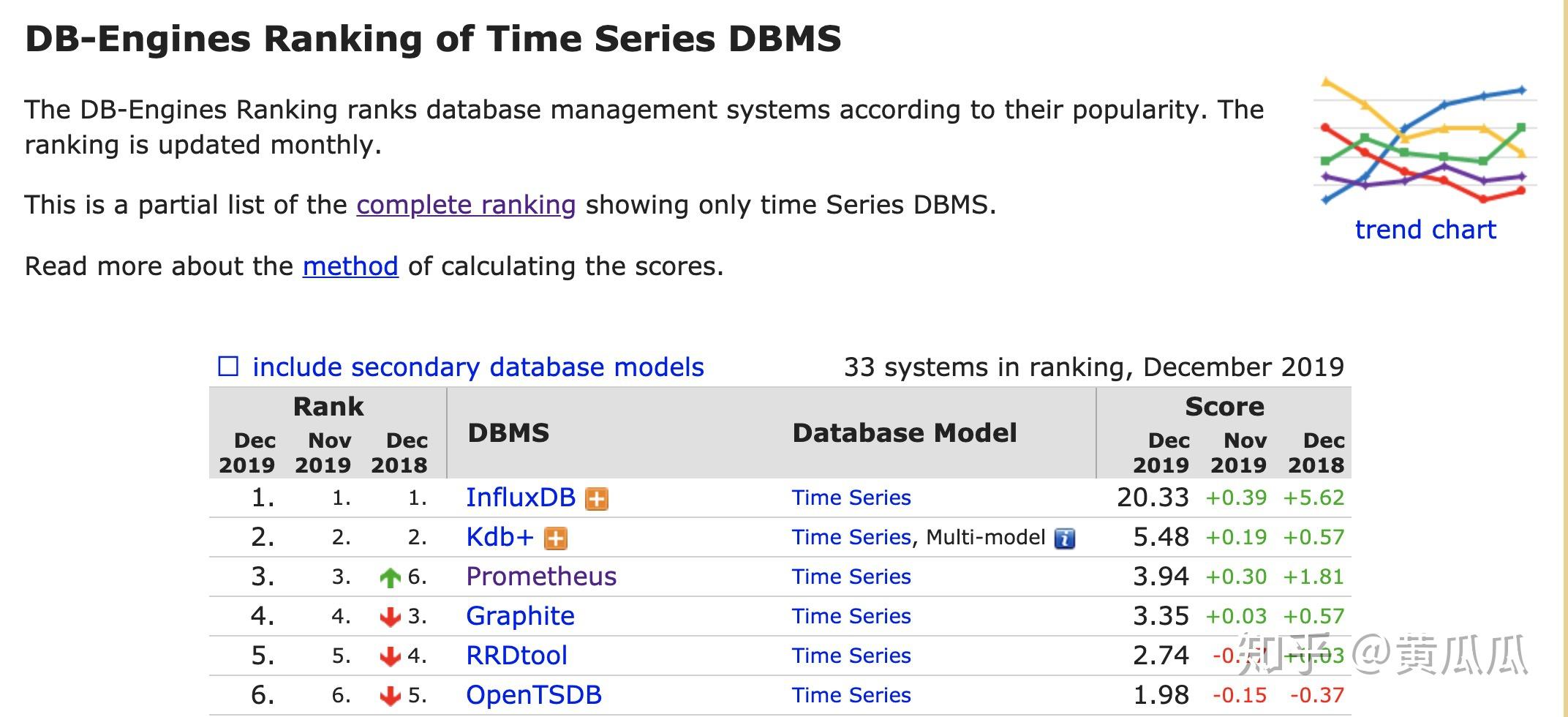
Prometheus:提供了一整套的监控体系,包括数据的采集存储报警等。仅支持单机,数据写入本地。数据采集使用的是pull模式。
opentsdb:基于hbase做的时序数据库,最大的特点是由hbase带来的横向扩展能力,最大的缺点是hbase带来的笨拙感,一旦集群扩大,运维可能会烦死人。
二、时序数据库要解决的痛点
公司内部团队曾经用mysql+中间件做过一款伪时序数据库,但是由于mysql底层的存储形式导致其天然不适应时序数据的场景。且其写入能力也完全无法满足时序数据大量写入的要求。
那么时序数据的特点是什么呢?
1、数据随着时间增长,根据维度取值,而数据纬度几乎不变。
2、持续高并发写入,设备越多,写入数量越大,而且由于定期采样,写入量平稳。但是几乎不会有更新操作(一个设备在某个时间点产生的数据不会变动)以及单独数据点的删除(通常只会删除过期时间范围内所有的数据)
3、查询一般都是查最近产生的数据,很少会去查询过期的数据。
4、设备之间的数据关联性小,同种类设备A和设备B产生的数据互相并不依赖。你并不需要join。
由上述特点结合我与iot行业相关人员的探讨,我总结出以下时序数据库要解决的痛点
1、海量设备带来的写入压力
2、如何高效存储大量纬度相同仅值和时间戳不同的数据
3、能够方便的剔除过期数据,或者能够把数据冷热分离以降低存储成本
4、传统企业it人员专业素质不高带来的对整个时序数据库体系的易用性要求
三、现有产品已经满足的和缺失的
假如你要问我写多读少的场景适合什么算法?显然那就是LSM Tree。更妙的是,时序数据很少有更新、删除操作,对事物的需求也不高,这很好的规避了LSMT对于update和delete上的缺陷。市面上的时序数据库基本都是采用LSM Tree的架构。
关于数据的压缩,很容易的能想到同纬度的数据压缩,时间戳前缀压缩等想法,这些在各家数据库都有体现。当然opentsdb似乎由于底层的hbase无法更好的针对时序数据的特点进行压缩,与之类似的问题是opentsdb必须手动去根据时间段来管理数据,而Influxdb、Prometheus包括Graphite等都是可以自己根据时间段来分割数据的。这样当你要删除过期数据时,只要删除对应的block就行。
对于数据查询,经常有人吐槽SQL不太行,所以有后面的NO-SQL出现。但是当大家真的想去做些分析时,还是不由自主的想念SQL,想在KV上用上SQL(new sql),哈哈哈,SQL真香。所以好的内置的针对时序数据的sql引擎也是让人感到愉悦、不可缺少的东西。目前Influxdb在这一块大大领先。
如果你想长时间保存数据,一个比较麻烦的问题是单机总是有容量上限的,即使你做一个上层中间件来搞一个所谓的集群。另外关于高可用,坏盘、数据迁移等等是真实的让人头痛的东西,我个人比较反感简单的双写,毕竟你要浪费两倍的CPU和内存,LSMT的Compaction带来的写放大本来就让人头疼,你还要对你的数据做两次,OMG!(李佳琦脸)真让人接受不能。
遗憾的是目前除了opentsdb似乎都落本地,麻烦事儿。
四、时序数据库架构
在数据库领域,只要你上生产,你就得考虑HA、数据可靠性,你就得考虑你的运维难度和成本,否则性能再高,也只是个PPT产物。
在时序数据库这一块,我讨厌简单的双写,同时我对于上层弄个一致性协议去搞所谓的分布式不是很感冒:只要数据要同时处理(解压,压缩)多次的,都挺浪费的。
你也可以选择分库分表分设备,但是底层似乎也是单点的,且单点上也要做主备,emmm。
我认为计算存储分离是个好方向。底层存储像hdfs一样,数据写(解压、压缩)一次,剩下两份直接副本传输(或者做EC),美妙。
上层是时序数据库引擎,下层是分布式文件/块存储。
显著的好处是对同一份数据的compaction肯定只要做一次(读取-compaction-写入文件-副本拷贝),而且免去了坏盘,物理机down等的烦恼。数据扩容/冷热分离也较为方便。同时对于一写多读相对友好(类似阿里的Polardb)
缺点嘛,多个计算节点写同一份数据比较麻烦,需要分布式锁来同步,不过在iot下设备天然可分割,设备区1的设备数据无需与设备区2的监控等数据做join等,那么为什么不能把无瓜葛的设备数据写在不同的实例里呢?这样似乎能较好的缓解写入的压力。(另一种形式的分库分表?)
这里希望有人能探讨一下。
总结
时序数据库确实在iot/监控这一方面是专精的,其在时序数据写入/查询/数据压缩方面有巨大的优势,能够解决许多用户痛点。而现有的时序数据库在存储方面还有所不足,要么是单机的,要么难以维护(opentsdb)。可改造的地方还有很多。
不过更高的查询性能,更快的写入速度,更方便低成本的运维,人人想要。一旦业务规模上来,各方面的需求都应该且会被考虑到,却并不可能都被满足。做工程本质上还是不断地做Trade Off。如何取舍还是要在实际生产应用中去选择。
