本篇博客要点如下:
浮点运算常见的一些精度问题
相信各位在进行浮点型数据运算的时候,出现过一些不符合常规认知,或者是我们不愿出现的结果,
比如下面这些示例(以MongoDB,Java,Python为例):
mongoDB中对某种类型的交易金额聚合求和的时候:
db.FACT_TRADE_POSP.aggregate([
{$match:{'AC_DT':'20200306','ETL_SOURCE':'05','TXN_CD':'2020060','TRAN_SOURCE':'03'}},
{$group:{_id:null,total:{$sum:1} ,mongo_txn:{$sum:"$TXN_AMT"}}}]);```
结果如下:
{
"_id" : null,
"total" : 1594.0,
"mongo_txn" : 378808.66000000003
}
Java浮点型运算:
System.out.println(1.1 + 2.2);
数据结果:
3.3000000000000003
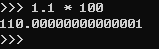
Python浮点型运算:
1.1 * 100
110.00000000000001
浮点运算精度问题产生的原因
上述的示例中可以看到,我们常用的编程语言或者数据库,在进行浮点运算会产生精度问题.
但同时也会有如下疑问:
浮点运算精度问题的几点疑问
1. 所有的浮点运算都会产生精度问题么?
2. 对于存在精度问题的浮点运算来说,每次获取到的结果是恒定的还是随机的?
3. 不同的系统架构(例如:Java, Python)进行浮点运算产生的结果一致么?
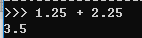
不是所有的浮点运算都会产生精度问题,例如:
对于存在精度问题的浮点运算来说,每次获取到的结果是恒定的,
请看下面的示例:
// 在java中,用for循环打印1.1 + 2.2的运算结果
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
System.out.println(1.1 + 2.2);
}
}

不同的系统架构(例如:Java, Python)进行浮点运算产生的结果一致
(前提:针对的是相同的数据类型,并且输出打印显示的规则一致)
使用Python计算的结果与java一致
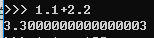
基于以上,我们有理由推测:
浮点计算的精度问题, 是具有特定规律的, 与平台无关,
而是由计算机底层原理决定的.
想要进一步弄清楚原因,我们就要知道,计算机底层究竟是
如何对浮点数据进行运算的
进制的相互转换
计算机底层,所有的数据都是以二进制的形式存储和计算
而我们通常更习惯于使用十进制进行计算,也就是说:
我们弄清楚十进制和二进制的转换过程,就弄清楚了浮点运算不准确的原因.
先来回顾一下十进制和二进制的整数转换
二进制转换为十进制 : 按权相加法
二进制转换为十进制: 除2取余,逆序排列
看一个简单的示例:
// 二进制转为十进制
10011 = 1 * 2^0 + 1 * 2^1 + 0 * 2^2 + 0 * 2^3 + 1 * 2^4 = 19
// 十进制转为二进制
19 / 2 = 9 .... 1
9 / 2 = 4 .... 1
4 / 2 = 2 .... 0
2 / 2 = 1 .... 0
1 / 2 = 0 .... 1
// 倒序排列 : 10011
再来看一下十进制和二进制的小数转换
十进制小数转换为二进制小数:
整数部分除 2 取余,逆序排列
小数部分乘 2 取整,顺序排列
二进制小数转换为十进制小数:
按权相加法
这里, 我们拿之前出现过精度问题的 1.1 和未表现出精度问题的 1.25来举例说明
// 将未出现过精度问题的1.25转换为2进制
// 整数部分
1 / 2 = 0 .... 1
// 小数部分
0.25 * 2 = 0.5 .... 0
0.5 * 2 = 1.0 .... 1
// 将得到的二进制数1.01转化为10进制数
1 * 2^(-2) + 0 * 2^(-1) + 1 * 2^0 = 1.25
// 将出现过精度问题的1.1转为2进制
// 整数部分
1 / 2 = 0 .... 1
// 小数部分
0.1 * 2 = 0.2 .... 0
0.2 * 2 = 0.4 .... 0
0.4 * 2 = 0.8 .... 0
0.8 * 2 = 1.6 .... 1
0.6 * 2 = 1.2 .... 1
0.2 * 2 = 0.4 ---- 0
//这样,我们得到循环体是0011的无限循环,也就是说1.1永远无法精确的表现为二进制数
// 而我们实际做计算的时候,截取的只是其中的一部分,所以计算出来的结果一定会出问题
// 我们截取3个循环1.0001100110011看一下计算结果
1* 2^0 + 1*2^(-4) + 1*2^(-5) + 1 * 2^(-8) + 1 * 2 ^(-9) + 1 * 2 ^(-12) + 1 * 2^(-13)
= 1.0999755859375
// 可以看到和实际的1.1 还是存在差距的,当然,越往后面截取,这个差距就会越小
从上面的举例和解释分析中,
我们得知了浮点运算产生精度问题的根本原因所在,
那么这个误差究竟有多大?我们还需要了解的更多
浮点数据的存储
计算机究竟是如何存储浮点型数据的呢?
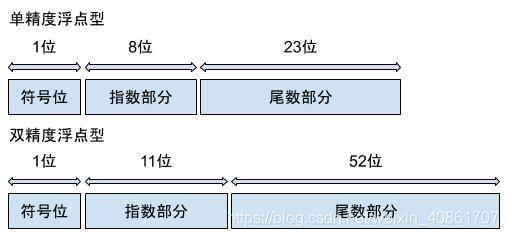
现行的通用标准为: IEEE二进制浮点数算术标准(IEEE 754)
根据该标准: 浮点型分为符号位,指数位和尾数为三部分
(详情请参见下图:)
 为了便于计算和理解,通常我们采用正规化的浮点数进行运算
为了便于计算和理解,通常我们采用正规化的浮点数进行运算
尾数不为0时,尾数域的最高有效位为1,这称为规格化。
否则,以修改阶码同时左右移动小数点位置的办法,使其成为规格化数的形式。
浮点数x真值表示:
x=(−1)S×(1.M)×2e
符号位 S
0是正数, 1是负数
指数位 e
指数位在这里兼具了需要表示正负的责任
因此其巧妙的运用了Excess系统
它规定最大值/2 - 1表示指数0
拿单精度浮点型的指数区域来进行举例:
从上面的图片中我们知道,单精度浮点数指数区域能够表示的最大数为2^8-1 = 255
那么255/2 - 1 = 127, 127代表指数0
128代表指数1, 126代表指数-1
尾数为 M
尾数位存储的是浮点数据的小数部分
举个例子
这部分的概念相对抽象,只看上面的解释难免一头雾水,
我们用一个实例来加深理解,依旧以双精度浮点型数据1.1举例
// 第一步 将1.1转换为二进制
1.0001100110011001100110011001100110011001100110011001
[1001100110011](方括号里面表示的是小数点后52位及之后)
// 第二步 将得到的1.1的二进制正规化
1.0001100110011001100110011001100110011001100110011001
[1001100110011] * 2^0
-----------------------------
// 我们注意到:由于双精度浮点数尾数只有52位,因此需要进行舍入
/*
舍入规则如下:
若:第53位为1,且53位之后全部为0,此时就要使第52位变为0
若第52位本来就是0,不做处理
若52位本来为1,则第53位向前进一位,使第52位变为0
若53位为1, 且第53位之后不全为0,则第53位向第52位进一位完成向上舍入
若第53位为0,应该直接舍去不进位,称为下舍入
*/
按照以上的写入规则,我们得到最终的正规化二进制为:
1.0001100110011001100110011001100110011001100110011010 * 2^0
// 第三步 使用IEEE 754标准转换
S符号位 正数 符号位0
e 指数位
正规化的阶数为0,按照我们刚刚介绍的Excess系统,0对应于2^11 / 2 - 1 = 1023
所以指数位为 0111-1111-111
M尾数为:0001-1001-1001-1001-1001-1001-1001-1001-1001-1001-1001-1001-1010
误差分析
通过上述例子我们可以得到,1.1的双精度浮点数表示为:
0 0111-1111-111 0001-1001-1001-1001-1001-1001-1001-1001-1001-1001-1001-1001-1010
我们将其还原 ,看看误差:
指数位为1023, 对应的实际指数为1
加上后面的尾数,对应的二进制数变为:
1.0001100110011001100110011001100110011001100110011010
将其转换为10进制:1.10000000000000008882 ≠ 1.1
这就是为什么浮点数运算结果在业务代码中总是不可确切预期的究极原因!!!!
浮点精度丢失问题的几种解决方案
1. 转换成整型进行计算
从我们最初二进制和十进制的转换中,我们知道,整型的转换不会出现问题,因此可以考虑将小数位数不多的数据转为整型计算
例如: 金额字段可以由按元计算和存储转变为按分,以避免此类问题
但此方案应该和客户,产品提前做好沟通,以免产生误解
2. 在业务没有进行精确要求的时候,可以采用四舍五入忽略这个问题
其中:类似于大屏查询这种反馈整体情况的可以采用此方案
但是各种对精度要求很高的报表,对账单则需要慎重!
我们采用出现过精度问题的1.1 + 2.2作为举例:
Java中做法:
// 1. 直接使用Math.round(double)函数
Math.round(1.1 + 2.2) // 得到结果 : 3, 该方法返回值为long,会直接丢弃小数位,请慎用!
// 2. 方法1的改进方法,假设我要保留两位小数
(double)Math.round((1.1 + 2.2) * 100) /100
//得到结果3.3 并不是3.30哦,因为这里小数位数只有1位
Python中做法:
# 使用round函数,返回浮点数的四舍五入值。
# 第二个参数为保留小数的位数,注意,若最后位的小数位为0,将不再保留,类似java
round(1.1 + 2.2, 1)
3.3
3. 使用Decimal函数解决该问题
Java中做法:
// 1. 使用DecimalFormat进行计算
import java.text.DecimalFormat;
DecimalFormat dcmFmt = new DecimalFormat("0.00");
(Double.valueOf(dcmFmt.format(1.1 + 2.2)); //得到结果3.3
// 2. 使用BigDecimal进行计算
import java.math.BigDecimal;
BigDecimal add = new BigDecimal("1.1").add(new BigDecimal("2.2"));
System.out.println(add); //得到结果3.3
Python中做法:
from decimal import Decimal
num = Decimal('1.1') + Decimal('2.2')
print(num) // 结果为3.3
