Hbase-之Bloom Filter布隆过滤器&Hbase
1 BloomFilter是什么?
布隆过滤器,以它的创始人Burton Howard Bloom的名字命名,首先明确一个点,它只是一个数据结构,这个数据结构最开始被设计成预测一个给定的元素在某个数据集中是否存在,它有如下特点:
- 精确的结果不一定准确,也就是返回的
a存在于集合A结果不一定是准确的; - 不精确的结果一定是对的,即
a不存在与集合A那是约等于100%是准确的。
布隆过滤器很适用于类似于Hbase这样的大数据集,如果想了解更多Bloom Filer可以参阅:布隆过滤器具体算法实现
在Hbase中,BloomFilter提供了一个轻量级的数据结构减少Disk上目标rowkey所在文件Storefiles的读取次数,BloomFilter只能配合Get使用,不能配合Scan使用,这个东西为集群获得了更多的并行读取性能提升(MPP:大规模并行处理)。
BloomFilter被存储在HFile的MetaData中,从来不需要更新,当一个HFile被open查询的时候,这个Bloom过滤器就会和metadata一起被加载到BlockCache缓存,一般是加载在LRUBlockCache的高速JVM heap缓存中(L1),而真实data被加载到L2的BucketCache中(l2,堆外内存),具体BlockCache参考:查询缓存BlockCache
Hbase包含一些调优策略,可以折叠BloomFilter从而减少内存占用,还能保证false精准率在一个可接受的范围内。
从hbase-0.96 and newer的版本开始,row-based BloomFilter默认就是启用的,
2 简单解释BloomFilter原理
BloomFilter使用的算法如下,看的懂的大神觉得有问题还可以在WIKI上编辑修改,成为贡献者。

WIKI地址:https://en.wikipedia.org/wiki/Bloom_filter
简单讲解:一个空的BloomFilter实际上就是一个空的bit数组,数组中的数据初始值都是0,下面是一个简单的BloomFilter的示例。

最开始BloomFilter的初始化长度为18,假设这里有3种基于长度18的hash散列算法,将集合{x,y,z}元素分别散列到数组中的位置,按照不同的hash算法,x,y,z分别在数组中占了3个位置,此时所占位置全都变成1,假如我需要判断w是否在{x,y,z}中,我们就按照相同的3种hash散列方式,找到w所在的位置,发现有一个位置映射在0的位置,很明显w不在{x,y,z}中。
假如我们将{x,y,z}当作HFile中的rowkey space,那么每个rowkey都在数组中有3个为1的位置映射,w也当作需要被get的rowkey,很明显在布隆过滤器中已经显示不存在w这个rowkey,就省去了到HFile中去查询的步骤,大大减少了IO消耗和CPU消耗,提升了查询的性能。
3 布隆过滤器在hbase中与客户端的交互
了解了上面的section,就知道布隆过滤器大致是什么原理了,那么我们看看如何交互客户端查询。
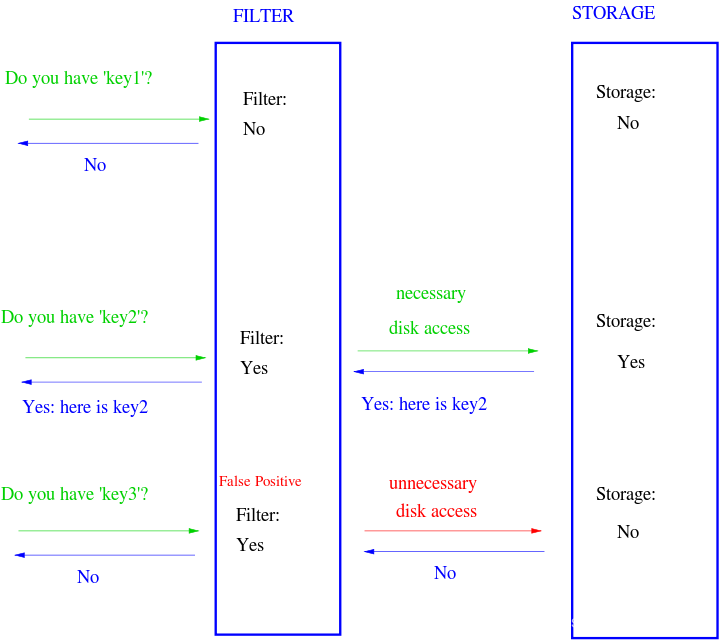
- 上图的Filter代表BloomFilter
- Storage代表HFile
- 请求从HbaseClient过来
第一次客户端发来一个请求get(key1),布隆过滤器回应没有,那么Store就不会去访问HFile了;
第二次客户端发来一个请求get(key2),布隆过滤器回应有,那么Store就去HFile中查询,并将查询结果Yes返回;
第三次客户端发来一个请求get(key2),布隆过滤器回应有,那么Store就去HFile中查询,但是HFile中没有,于是将正确的NO返回。
很明显,布隆过滤器false positive是很精准的,而positive不一定精准,但是也不影响返回结果。
4 什么时候使用BloomFilter
从hbase-0.96+以来,row-based BloomFilter默认就是开启的,我们可以选择关闭它或者将它换成row+column的过滤器,这个需要根据你的加载到Hbase的方式以及你的数据的特征。
要确定Bloom过滤器是否可能产生积极影响,请检查RegionServer指标中的blockCacheHitRatio的值。如果启用了布隆过滤器,则blockCacheHitRatio的值应增加,因为布隆过滤器正在过滤出绝对不需要的Blocks。
我们可以选择一个row或者row+column类型的布隆过滤器
- 如果你scan所有行,那么row+column的过滤器是不能带来任何益处的;
- row类型的布隆过滤器可以适用于row+column的Get操作,反之不行;
- 如果你在一个row中插入了大量的column Put,那么这个row的数据分布在很多个storefile中,一个row类型布隆过滤器总是返回
yes,这样也是没有起到优化作用; - 如果你一个row只对应一个column,那么row+column的过滤器会占用更大的space,存储更多的Keyvalue对象中的key信息,得不偿失。
- 当每条rowkey对应的数据条目的数据大小为几千字节的时候,Bloom过滤器最有效。
当你的数据存储在少量的大的StoreFile中时,开销将会减少,从而避免在StoreFile中扫描指定rowkey产生的额外的磁盘IO;记住,在删除数据之后BloomFilter会自动重建,所以布隆过滤器不适合有大量删除操作的场景
5 开启BloomFilter
BloomFilter是启用在每个ColumnFamily上的,我们可以使用JavaAPI
//我们可以通过ColumnDescriptor来指定开启的BloomFilter的类型
HColumnDescriptor.setBloomFilterType() //可选NONE、ROW、ROWCOL
我们还可以在创建Table的时候指定BloomFilter
hbase> create 'mytable',{NAME => 'colfam1', BLOOMFILTER => 'ROWCOL'}
6 BloomFilter相关的配置参数
我们可以在hbase-site.xml中配置相关的参数,不想翻译了,大家伙培养一下英文阅读能力哈,么么哒~~
| Parameter | Default | Description |
|---|---|---|
| io.storefile.bloom.enabled | yes | Set to no to kill bloom filters server-wide if something goes wrong |
| io.storefile.bloom.error.rate | .01 | The average false positive rate for bloom filters. Folding is used to maintain the false positive rate. Expressed as a decimal representation of a percentage. |
| io.storefile.bloom.max.fold | 7 | The guaranteed maximum fold rate. Changing this setting should not be necessary and is not recommended. |
| io.storefile.bloom.max.keys | 128000000 | For default (single-block) Bloom filters, this specifies the maximum number of keys. |
| io.storefile.delete.family.bloom.enabled | true | Master switch to enable Delete Family Bloom filters and store them in the StoreFile. |
| io.storefile.bloom.block.size | 131072 | Target Bloom block size. Bloom filter blocks of approximately this size are interleaved with data blocks. |
| hfile.block.bloom.cacheonwrite | false | Enables cache-on-write for inline blocks of a compound Bloom filter. |
