前言
前段时间有套线上HBase出了点小问题,导致该套HBase集群服务停止了2个小时,从而造成使用该套HBase作为数据存储的应用也出现了服务异常。在排查问题之余,我们不禁也在思考,以后再出现类似的问题怎么办?这种问题该如何避免?用惯了MySQL,于是乎想到了HBase是否跟MySQL一样,也有其高可用方案?
答案当然是肯定的,几乎所有的数据库(无论是关系型还是分布式的),都采用WAL的方式来保障服务异常时候的数据恢复,HBase同样也是通过WAL来保障数据不丢失。HBase在写数据前会先写HLog,HLog中记录的是所有数据的变动, HBase的高可用也正是通过HLog来实现的。
进阶
HBase是一个没有单点故障的分布式系统,上层(HBase层)和底层(HDFS层)都通过一定的技术手段,保障了服务的可用性。上层HMaster一般都是高可用部署,而RegionServer如果出现宕机,region迁移的代价并不大,一般都在毫秒级别完成,所以对应用造成的影响也很有限;底层存储依赖于HDFS,数据本身默认也有3副本,数据存储上做到了多副本冗余,而且Hadoop 2.0以后NameNode的单点故障也被消除。所以,对于这样一个本身没有单点故障,数据又有多副本冗余的系统,再进行高可用的配置是否有这个必要?会不会造成资源的极大浪费?
高可用部署是否有必要,这个需要根据服务的重要性来定,这里先简单介绍下没有高可用的HBase服务会出现哪些问题:
1. 数据库管理人员失误,进行了不可逆的DDL操作
不管是什么数据库,DDL操作在执行的时候都需要慎之又慎,很可能一条简单的drop操作,会导致所有数据的丢失,并且无法恢复,对于HBase来说也是这样,如果管理员不小心drop了一个表,该表的数据将会被丢失。
2. 离线MR消耗过多的资源,造成线上服务受到影响
HBase经过这么多年的发展,已经不再是只适合离线业务的数据存储分析平台,许多公司的线上业务也相继迁移到了HBase上,比较典型的如:facebook的iMessage系统、360的搜索业务、小米米聊的历史数据等等。但不可避免在这些数据上做些统计分析类操作,大型MR跑起来,会有很大的资源消耗,可能会影响线上业务。
3. 不可预计的另外一些情况
比如核心交换机故障,机房停电等等情况都会造成HBase服务中断
对于上述的那些问题,可以通过配置HBase的高可用来解决:
1. 不可逆DDL问题
HBase的高可用不支持DDL操作,换句话说,在master上的DDL操作,不会影响到slave上的数据,所以即使在master上进行了DDL操作,slave上的数据依然没有变化。这个跟MySQL有很大不同,MySQL的DDL可以通过statement格式的Binlog进行复制。
2. 离线MR影响线上业务问题
高可用的最大好处就是可以进行读写分离,离线MR可以直接跑在slave上,master继续对外提供写服务,这样也就不会影响到线上的业务,当然HBase的高可用复制是异步进行的,在slave上进行MR分析,数据可能会有稍微延迟。
3. 意外情况
对于像核心交换机故障、断电等意外情况,slave跨机架或者跨机房部署都能解决该种情况。
基于以上原因,如果是核心服务,对于可用性要求非常高,可以搭建HBase的高可用来保障服务较高的可用性,在HBase的Master出现异常时,只需简单把流量切换到Slave上,即可完成故障转移,保证服务正常运行。
原理
HBase高可用保证在出现异常时,快速进行故障转移。下面让我们先来看看HBase高可用的实现,首先看下官方的一张图: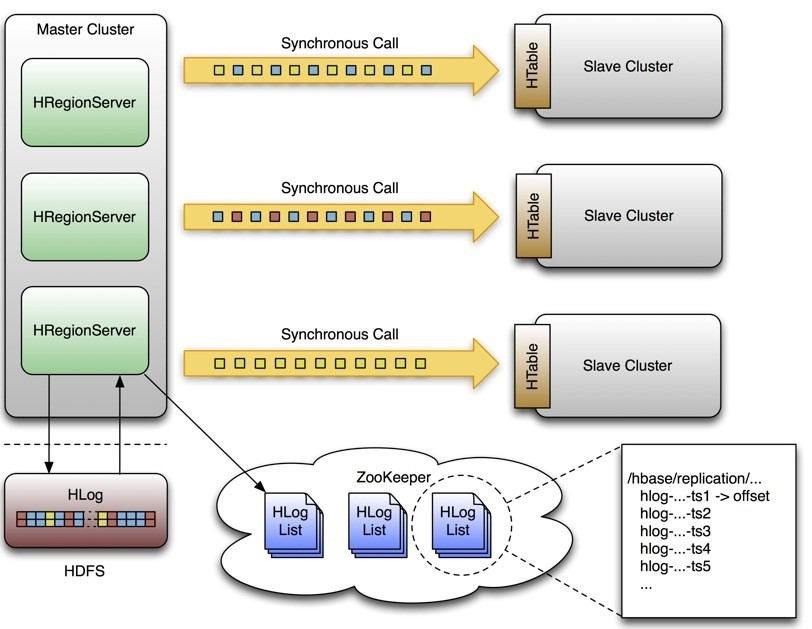
HBase Replication
需要声明的是,HBase的replication是以Column Family为单位的,每个Column Family都可以设置是否进行replication。
上图中,一个Master对应了3个Slave,Master上每个RegionServer都有一份HLog,在开启Replication的情况下,每个RegionServer都会开启一个线程用于读取该RegionServer上的HLog,并且发送到各个Slave,Zookeeper用于保存当前已经发送的HLog的位置。Master与Slave之间采用异步通信的方式,保障Master上的性能不会受到Slave的影响。用Zookeeper保存已经发送HLog的位置,主要考虑在Slave复制过程中如果出现问题后重新建立复制,可以找到上次复制的位置。
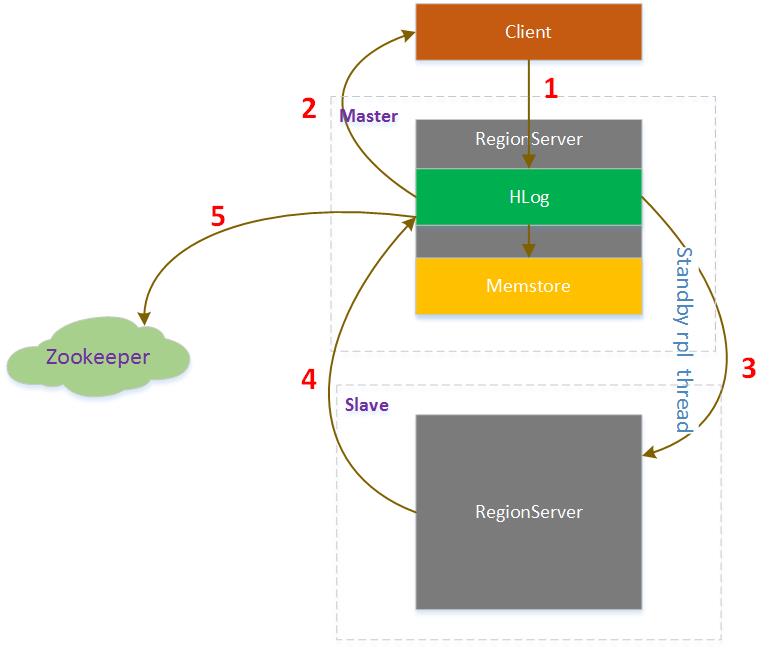
HBase Replication步骤
1. HBase Client向Master写入数据
2. 对应RegionServer写完HLog后返回Client请求
3. 同时replication线程轮询HLog发现有新的数据,发送给Slave
4. Slave处理完数据后返回给Master
5. Master收到Slave的返回信息,在Zookeeper中标记已经发送到Slave的HLog位置
注:在进行replication时,Master与Slave的配置并不一定相同,比如Master上可以有3台RegionServer,Slave上并不一定是3台,Slave上的RegionServer数量可以不一样,数据如何分布这个HBase内部会处理。
种类
HBase通过HLog进行数据复制,那么HBase支持哪些不同种类的复制关系?
从复制模式上来讲,HBase支持主从、主主两种复制模式,也就是经常说的Master-Slave、Master-Master复制。
1. Master-Slave
Master-Slave复制比较简单,所有在Master集群上写入的数据都会被同步到Slave上。
2. Master-Master
Master-Master复制与Master-Slave类似,主要的不同在于,在Master-Master复制中,两个Master地位相同,都可以进行读取和写入。
既然Master-Master两个Master都可以进行写入,万一出现一种情况:两个Master上都进行了对同一表的相同Column Family的同一个rowkey进行写入,会出现什么情况?
create ‘t’, {NAME=>’cf’, REPLICATION_SCOPE=>’1’}
Master1 Master2
put ‘t’, ‘r1’, ‘cf’, ‘aaaaaaaaaaaaaaa’ put ‘t’, ‘r1’, ‘cf’, ‘bbbbbbbbbbbbbbb’
如上操作,Master1上对t的cf列簇写入rowkey为r1,value为aaaaaaaaaaaaaaa的数据,Master2上同时对t的cf列簇写入rowkey为r1, value为bbbbbbbbbbbbbbb的数据,由于是Master-Master复制,Master1和Master2上在写入数据的同时都会把更新发送给对方,这样最终的数据就变成了:
| Master1 |
Master2 |
||
| rowkey |
value |
rowkey |
value |
| r1 |
bbbbbbbbbbbbbbb |
r1 |
aaaaaaaaaaaaaaa |
从上述表格中可以看到,最终Master1和Master2上cf列簇rowkey为r1的数据两边不一致。
所以,在做Master-Master高可用时,确保两边写入的表都是不同的,这样能防止上述数据不一致问题。
异常
HBase复制时,都是通过RegionServer开启复制线程进行HLog的发送,那么当其中某个RegionServer出现异常时,HBase是如何处理的?这里需要区别两种不同的情况,即Master上RegionServer异常和Slave上RegionServer异常。
1. Slave上RegionServer异常
对于该种异常HBase处理比较简单,Slave上出现某个RegionServer异常,该RegionServer直接会被标记为异常状态,后续所有的更新都不会被发送到该台RegionServer,Slave会重新选取一台RegionServer来接收这部分数据。
2. Master上RegionServer异常
Master上RegionServer出现异常,由于HLog都是通过RegionServer开启复制线程进行发送,如果RegionServer出现异常,这个时候,属于该台RegionServer的HLog就没有相关处理线程,这个时候,这部分数据又该如何处理?
Master上某台RegionServer异常,其他RegionServer会对该台RegionServer在zookeeper中的信息尝试加锁操作,当然这个操作是互斥的,同一时间只有一台RegionServer能获取到锁,然后,会把HLog信息拷贝到自己的目录下,这样就完成了异常RegionServer的HLog信息的转移,通过新的RegionServer把HLog的信息发送到Slave。
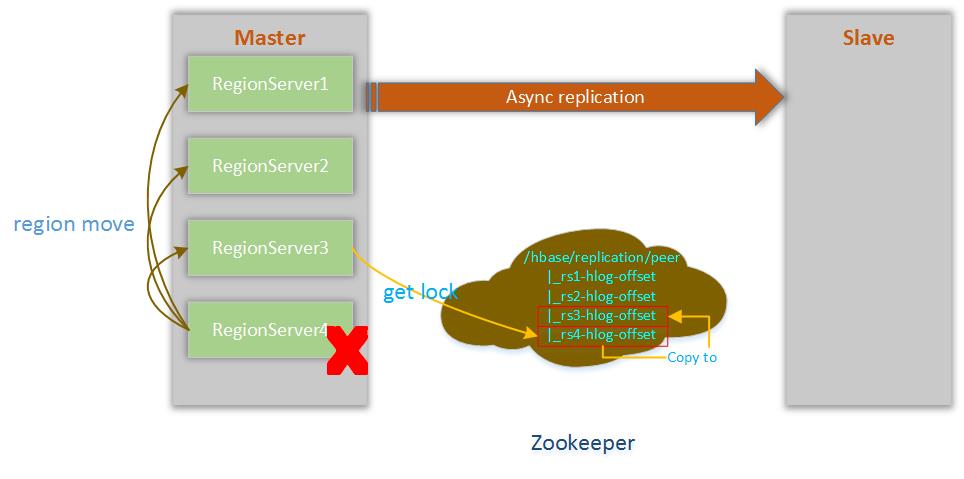
Master regionserver crash
操作
上面介绍的都是HBase高可用的理论实现和异常处理等问题,下面就动手实践下,如何配置一个HBase的Replication(假设已经部署好了两套HBase系统,并且在配置文件中已经开启了replication配置),首先尝试配置下Master-Slave模式的高可用:
1. 选取一套系统作为Master,另外一套作为Slave
2. 在Master上通过add_peer 命令添加复制关系,如下
add_peer ‘1’, “db-xxx.photo.163.org:2181:/hbase”
3. 在Master上新建表t,该表拥有一个列簇名为cf,并且该列簇开启replication,如下:
create ‘t’, {NAME=>’cf’, REPLICATION_SCOPE=>’1’}
上面REPLICATION_SCOPE的值需要跟步骤2中的对应
4. 在slave建立相同的表(HBase不支持DDL的复制),在master-slave模式中,slave不需要开启复制,如下:
create ‘t’, {NAME=>’cf’ }
这样,我们就完成了整个master-slave模式高可用的搭建,后续可以在master上通过put操作插入一条记录,查看slave上是否会复制该记录,最终结果如下:
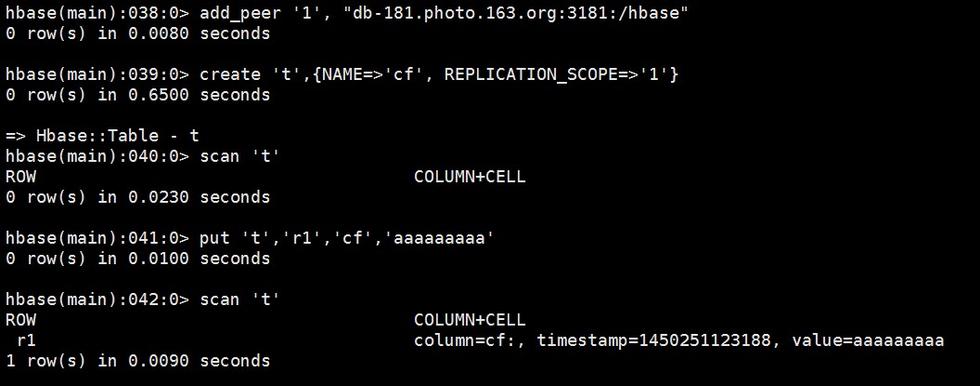
Master上操作
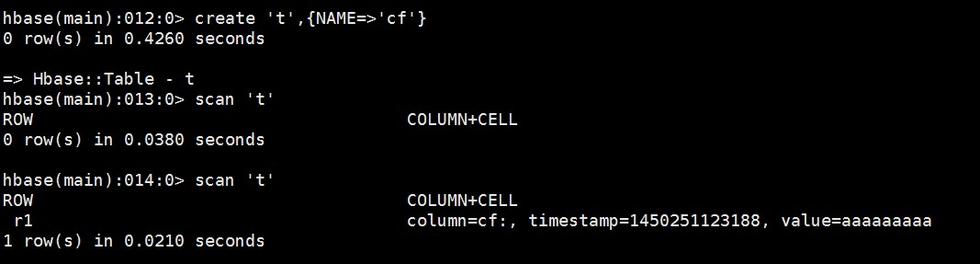
Slave上结果
上述结果显示,在添加完复制关系后,Master上插入rowkey=r1, value=’aaaaaaaaa’的记录,slave上可以获取该记录,Master-Slave模式数据复制成功。
接下来我们再看下Master-Master模式的复制,配置的时候与Master-Slave模式不同的是,在Master上添加完复制关系后,需要在另外一台Master也添加复制关系,而且两边的cluster_id必须相同,并且在另外一台Master上建表的时候,需要加上列簇的REPLICATION_SCOPE=>’1’配置,最终结果如下:
Master1上操作
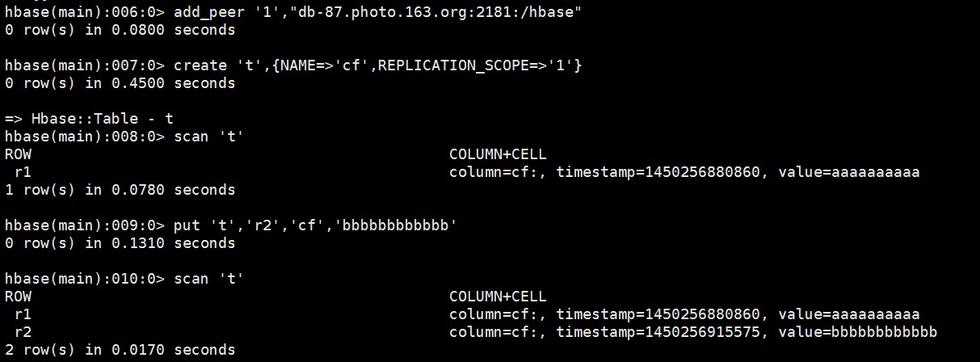
Master2上操作
上述结果显示,添加完了Master-Master复制关系,在Master1上插入一条记录rowkey=r1, value=“aaaaaaaaaa”,Master2上通过scan操作发现该记录已经被复制到Master2上,接着我们在Master2上添加一条记录rowkey=r2, value=’bbbbbbbbbbbb’,查看Master1上的数据,该条记录也已经被复制到Master2上,Master-Master模式的replication验证成功。
本文来自网易实践者社区,经作者蒋鸿翔授权发布。
