Kafka对于producer发来的消息怎么保证可靠性?
每个partition都给配上副本,做数据同步,保证数据不丢失。
副本数据同步策略
和zookeeper不同的是,Kafka选择的是全部完成同步,才发送ack。但是又有所区别。
所以,你们才会在各种博客看到这句话【kafka不是完全同步,也不是完全异步,是一种ISR机制】
这句话对也不对,不对也对(谜语人......)
首先笔者认为:Kafka使用的就是完全同步方案。
完全同步的优点
同样为了容忍 n 台节点的故障,过半机制需要 2n+1 个副本,而全部同步方案只需要 n+1 个副本,
而 Kafka 的每个分区都有大量的数据,过半机制方案会造成大量数据的冗余。(这就是和zookeeper的不同)
完全同步会有什么问题?
假设就有这么一个follower延迟太高或者某种故障的情况出现,导致迟迟不能与leader进行同步。
怎么办?leader等还是不等?
等吧:producer有话要说:“Kafka也不行啊,处理个消息这么费劲,垃圾,你等NM呢等”
不等:那你Kafka对外说完全同步个鸡儿,你这是完全同步么?
基于此,Kafka的设计者和开发者想出了一个非常鸡贼的点子:ISR
什么是ISR?
先来看几个概念
1、AR(Assigned Repllicas)一个partition的所有副本(就是replica,不区分leader或follower)
2、ISR(In-Sync Replicas)能够和 leader 保持同步的 follower + leader本身 组成的集合。
3、OSR(Out-Sync Relipcas)不能和 leader 保持同步的 follower 集合
4、公式:AR = ISR + OSR
所以,看明白了吗?
Kafka对外依然可以声称是完全同步,但是承诺是对AR中的所有replica完全同步了吗?
并没有。Kafka只保证对ISR集合中的所有副本保证完全同步。
至于,ISR到底有多少个follower,那不知道,别问,问就是完全同步,你再问就多了。
这就好比网购买一送一,结果邮来了一大一小两个产品。
你可能觉得有问题,其实是没问题的,商家说送的那个是一模一样的了吗?并没有。
ISR就是这个道理,Kafka是一定会保证leader接收到的消息完全同步给ISR中的所有副本。
而最坏的情况下,ISR中只剩leader自己。
基于此,上述完全同步会出现的问题就不是问题了。
因为ISR的机制就保证了,处于ISR内部的follower都是可以和leader进行同步的,一旦出现故障或延迟,就会被踢出ISR。
ISR 的核心就是:动态调整
总结:Kafka采用的就是一种完全同步的方案,而ISR是基于完全同步的一种优化机制。
follower的作用
读写都是由leader处理,follower只是作备份功能,不对外提供服务。
什么情况ISR中的replica会被踢出ISR?
以前有2个配置
# 默认10000 即 10秒
replica.lag.time.max.ms
# 允许 follower 副本落后 leader 副本的消息数量,超过这个数量后,follower 会被踢出 ISR
replica.lag.max.messages 说白了就是一个衡量leader和follower之间差距的标准。
一个是基于时间间隔,一个是基于消息条数。
0.9.0.0版本之后,移除了replica.lag.max.messages 配置。
为什么?
因为producer是可以批量发送消息的,很容易超过replica.lag.max.messages,那么被踢出ISR的follower就是受了无妄之灾。
他们都是没问题的,既没有出故障也没高延迟,凭什么被踢?
replica.lag.max.messages调大呢?调多大?太大了是否会有漏网之鱼,造成数据丢失风险?
这就是replica.lag.max.messages的设计缺陷。
replica.lag.time.max.ms的误区
【只要在 replica.lag.time.max.ms 时间内 follower 有同步消息,即认为该 follower 处于 ISR 中】
你去网上看博客,很多博客表达的就是这个意思,不过笔者认为这么描述很容易误导初学者。
那我是不是可以理解为,follower有个定时任务,只要在replica.lag.time.max.ms时间内去leader那pull数据就行了。
其实不是的。千万不要这么认为,因为这里还涉及一个速率问题(你理解为蓄水池一个放水一个注水的问题)。
如果leader副本的消息流入速度大于follower副本的拉取速度时,你follower就是实时同步有什么用?
典型的出工不出力,消息只会越差越多,这种follower肯定是要被踢出ISR的。
当follower副本将leader副本的LEO之前的日志全部同步时,则认为该follower副本已经追赶上leader副本。
此时更新该副本的lastCaughtUpTimeMs标识。
Kafka的副本管理器(ReplicaManager)启动时会启动一个副本过期检测的定时任务,
会定时检查当前时间与副本的lastCaughtUpTimeMs差值是否大于参数replica.lag.time.max.ms指定的值。
所以replica.lag.time.max.ms的正确理解是:
follower在过去的replica.lag.time.max.ms时间内,已经追赶上leader一次了。
follower到底出了什么问题?
两个方面,一个是Kafka自身的问题,另一个是外部原因
Kafka源码注释中说明了一般有两种情况会导致副本失效:
1、follower副本进程卡住,在一段时间内根本没有想leader副本发起同步请求,比如频繁的Full GC。
2、follower副本进程同步过慢,在一段时间内都无法追赶上leader副本,比如IO开销过大。
1、通过工具增加了副本因子,那么新增加的副本在赶上leader副本之前也都是处于失效状态的。
2、如果一个follower副本由于某些原因(比如宕机)而下线,之后又上线,在追赶上leader副本之前也是出于失效状态。
什么情况OSR中的replica会重新加入ISR?
基于上述,replica重新追上了leader,就会回到ISR中。
相关的重要概念
需要先明确几个概念:
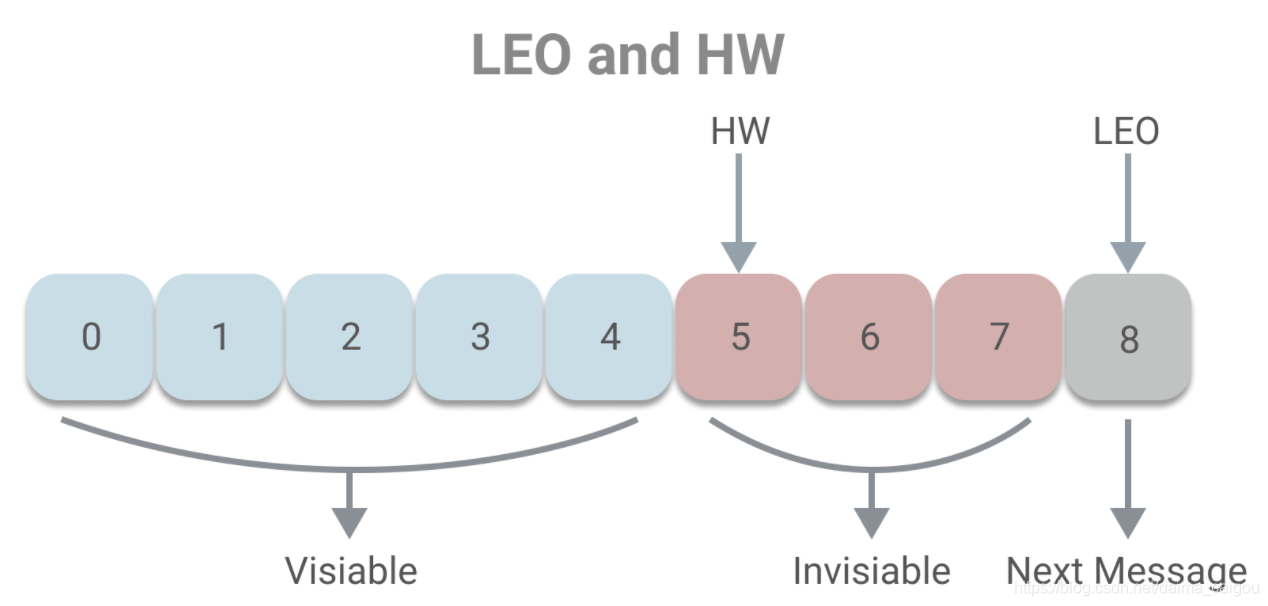
1、LEO(last end offset):
当前replica存的最大的offset的下一个值
2、HW(high watermark):
小于 HW 值的offset所对应的消息被认为是“已提交”或“已备份”的消息,才对消费者可见。
假设ISR中目前有1个leader,3个follower。
1、leader接收一个消息,自己保存后,马上发送3个请求通知3个follower赶紧保存
2、等待3个follower响应保存成功
3、响应producer,消息提交成功
你是这么想的么?反正当时我是这么想的。
实际上不是的,这个同步是follower主动去请求leader进行同步的。
因为是每个follower情况不一样,所以才会出现LEO和HW的概念。
简言之,木桶原理
replica里存了多少数据和consumer能消费多少数据,不是一回事。
所谓木桶原理,就是把每个replica当作一个木桶的板子,桶能装多少水只取决于最短的那块板子。
这就是也有些人把HW叫成 高水位 的原因。
而 HW 的概念,也契合前文提到的【完全同步】,HW之前的所有消息,在ISR中是完全同步的。
写在最后的话
【推荐大家在看Kafka相关博客文章视频的时候,遇到任何问题不要纠结,赶紧翻书,Kafka相关的博客真的一言难尽】
就这块的知识点,大家请注意,你去看博客或者公众号或者培训机构的视频,介绍的五花八门, 含糊不清。
咱也不知道都是在哪学的.....笔者在Kafka官方文档中搜索关键字,并未搜索到,也可能是我的搜索方式不对,
总之那些又画线,又上色的,图整了不少,整的花里胡哨的,都TM不一样。
还俗称“高水位”,俩破单词不够你得瑟的了,你是不是觉得你讲的生动形象???
前提是知识点要准确啊,瞎JB比喻!
如果你把consumer可见消息比喻成水,HW比喻“水位”,
那么HW就是consumer可见的那个最大的offset,因为水位就是水面,水面也是水。
而如果不是,那我宁愿把HW比喻成船。紧贴水面的就是船,船永远在水面之上,水涨而船高。
很多图,都把replica化成了数组的模样,offset好似数组的index,
如果是这样,我宁愿把LEO比喻成 C语言字符串中的 "\0",就是标识位。
笔者猜测,LEO应该除了记录offset,还记录了一个像segment的index文件里的position一样。
指向最后一个消息有啥用,还不是要算一次偏移量,才能记录新消息。如果这个物理地址记录的是最后一个消息的后面的位置,那么新消息进来就能直接定位,直接写文件了。
【HW就是ISR中最小的LEO】有人也这么说的。有说HW <= LEO的,有说HW < LEO。爷吐了.....
随便截2篇博客,大家先尝尝。

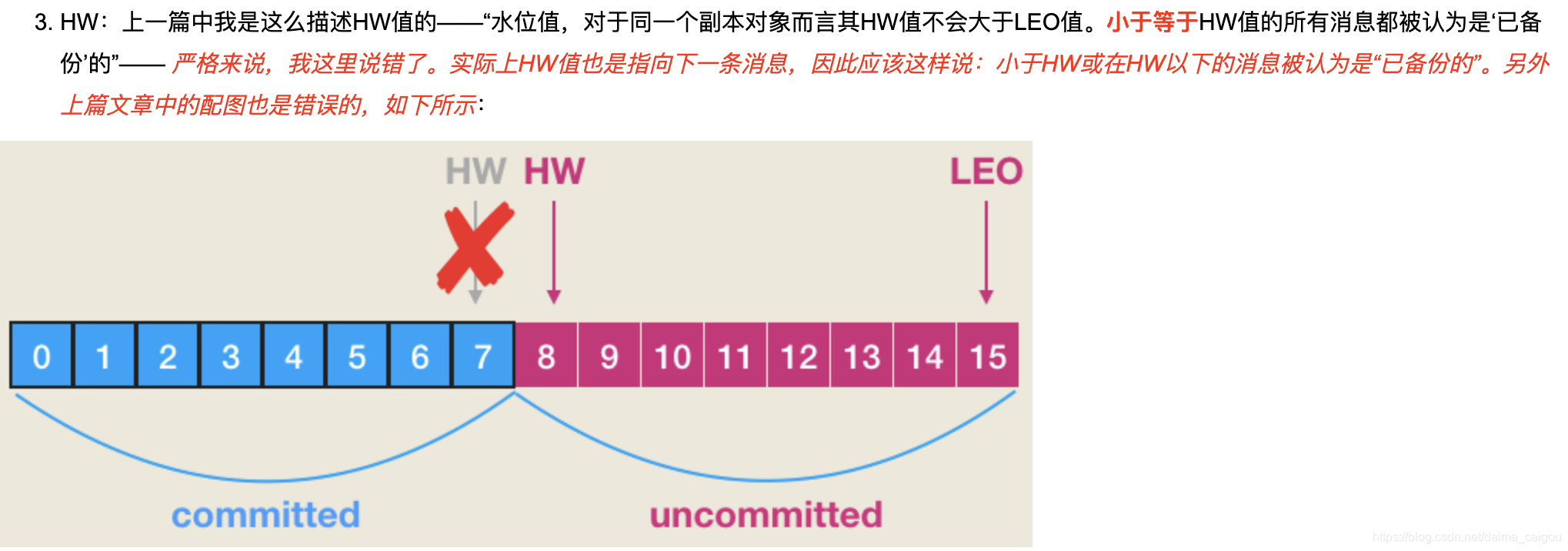
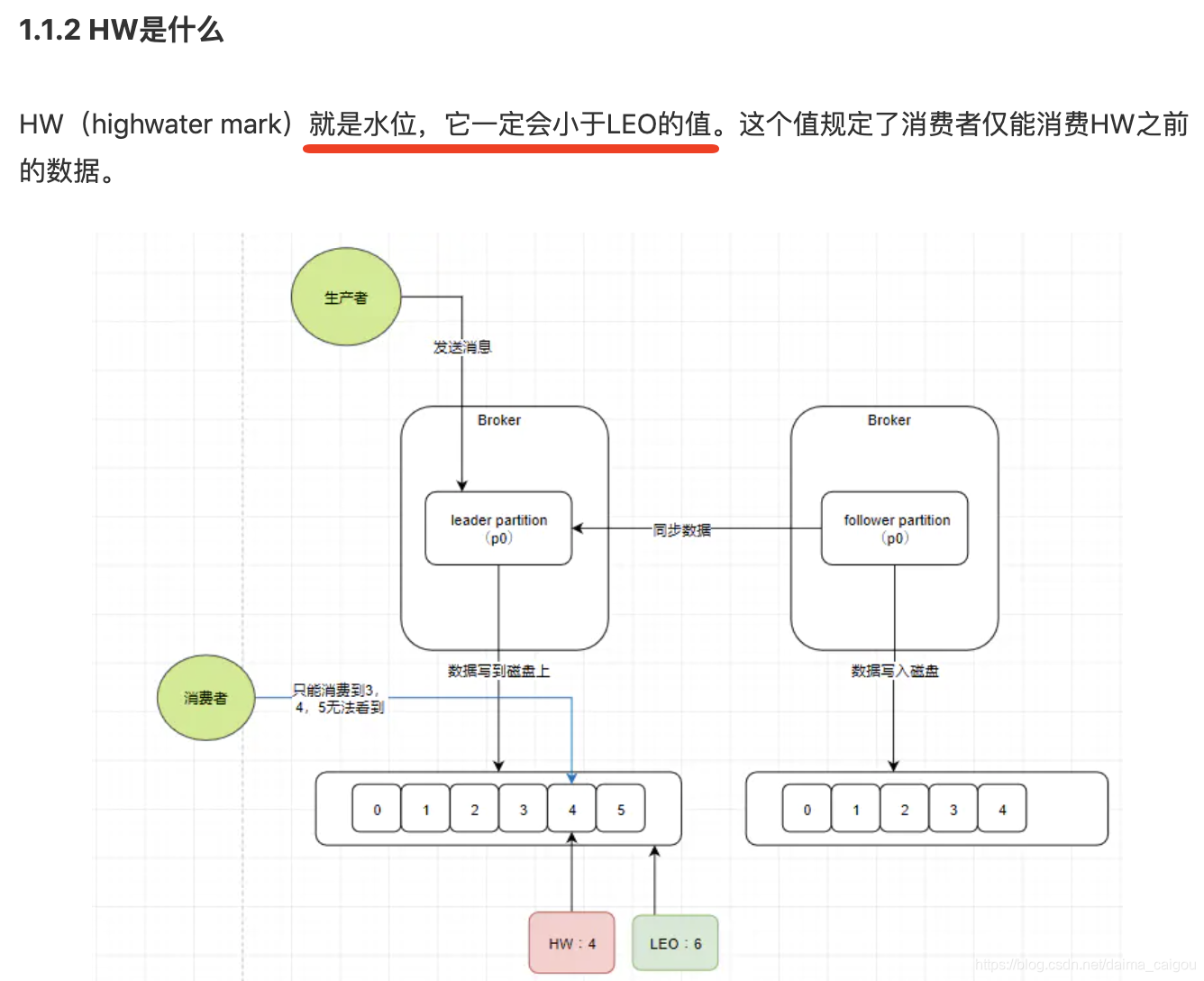
我写的只是一个能说服我自己的概念知识点,对错我保证不了。
希望精通源码的大佬看到能在评论区解惑,不胜感激。
------- 路漫漫其修远兮,我求索NMLB。
