相关阅读
【小家java】java5新特性(简述十大新特性) 重要一跃
【小家java】java6新特性(简述十大新特性) 鸡肋升级
【小家java】java7新特性(简述八大新特性) 不温不火
【小家java】java8新特性(简述十大新特性) 饱受赞誉
【小家java】java9新特性(简述十大新特性) 褒贬不一
【小家java】java10新特性(简述十大新特性) 小步迭代
【小家java】java11新特性(简述八大新特性) 首个重磅LTS版本
【小家java】Java中的线程池,你真的用对了吗?(教你用正确的姿势使用线程池)
小家Java】一次Java线程池误用(newFixedThreadPool)引发的线上血案和总结
【小家java】BlockingQueue阻塞队列详解以及5大实现(ArrayBlockingQueue、DelayQueue、LinkedBlockingQueue…)
【小家java】用 ThreadPoolExecutor/ThreadPoolTaskExecutor 线程池技术提高系统吞吐量(附带线程池参数详解和使用注意事项)
Java 7 引入了一种新的并发框架—— Fork/Join Framework。同时引入了一种新的线程池:ForkJoinPool(ForkJoinPool.coomonPool)
@sun.misc.Contended
public class ForkJoinPool extends AbstractExecutorService {
}
本文的主要目的是介绍 ForkJoinPool 的适用场景,实现原理,以及示例代码。
说在前面
可以说是说明,也可以说下面是结论:
- ForkJoinPool 不是为了替代 ExecutorService,而是它的补充,在某些应用场景下性能比 ExecutorService 更好。
- ForkJoinPool 主要用于实现“分而治之”的算法,特别是分治之后递归调用的函数,例如 quick sort 等。
- ForkJoinPool 最适合的是计算密集型的任务,如果存在 I/O,线程间同步,sleep() 等会造成线程长时间阻塞的情况时,最好配合使用 ManagedBlocker。
使用
首先介绍的是大家最关心的 Fork/Join Framework 的使用方法,用一个特别简单的求整数数组所有元素之和来作为我们现在需要解决的问题吧。
问题:计算1至10000000的正整数之和。
- 方案一:最为普通的for循环解决
最简单的,显然是不使用任何并行编程的手段,只用最直白的 for-loop 来实现。下面就是具体的实现代码。
为了面向接口编程,下面我们把计算的方法定义成接口,不同的方案书写不同的实现即可
/**
* @author fangshixiang@vipkid.com.cn
* @description //
* @date 2018/11/5 14:26
*/
public interface Calculator {
/**
* 把传进来的所有numbers 做求和处理
*
* @param numbers
* @return 总和
*/
long sumUp(long[] numbers);
}
写一个通过for loop的实现。这段代码毫无出奇之处,也就不多解释了
/**
* 通过普通的for循环 实现总和的相加 逻辑非常简单
* * @author fangshixiang@vipkid.com.cn
* @description //
* @date 2018/11/5 14:31
*/
public class ForLoopCalculator implements Calculator {
@Override
public long sumUp(long[] numbers) {
long total = 0;
for (long i : numbers) {
total += i;
}
return total;
}
}
写一个main方法进行测试:
public static void main(String[] args) {
long[] numbers = LongStream.rangeClosed(1, 10000000).toArray();
Instant start = Instant.now();
Calculator calculator = new ForLoopCalculator();
long result = calculator.sumUp(numbers);
Instant end = Instant.now();
System.out.println("耗时:" + Duration.between(start, end).toMillis() + "ms");
System.out.println("结果为:" + result);
}
输出:
耗时:10ms
结果为:50000005000000
- 方案二:ExecutorService多线程方式实现
在 Java 1.5 引入 ExecutorService 之后,基本上已经不推荐直接创建 Thread 对象,而是统一使用 ExecutorService。毕竟从接口的易用程度上来说 ExecutorService 就远胜于原始的 Thread,更不用提 java.util.concurrent 提供的数种线程池,Future 类,Lock 类等各种便利工具。
由于上面是面向接口的设计,因此我们只需要加一个使用 ExecutorService 的实现类:
/**
* 使用ExecutorService实现多线程的求和
* * @author fangshixiang@vipkid.com.cn
* @description //
* @date 2018/11/5 14:45
*/
public class ExecutorServiceCalculator implements Calculator {
private int parallism;
private ExecutorService pool;
public ExecutorServiceCalculator() {
parallism = Runtime.getRuntime().availableProcessors(); // CPU的核心数 默认就用cpu核心数了
pool = Executors.newFixedThreadPool(parallism);
}
//处理计算任务的线程
private static class SumTask implements Callable<Long> {
private long[] numbers;
private int from;
private int to;
public SumTask(long[] numbers, int from, int to) {
this.numbers = numbers;
this.from = from;
this.to = to;
}
@Override
public Long call() {
long total = 0;
for (int i = from; i <= to; i++) {
total += numbers[i];
}
return total;
}
}
@Override
public long sumUp(long[] numbers) {
List<Future<Long>> results = new ArrayList<>();
// 把任务分解为 n 份,交给 n 个线程处理 4核心 就等分成4份呗
// 然后把每一份都扔个一个SumTask线程 进行处理
int part = numbers.length / parallism;
for (int i = 0; i < parallism; i++) {
int from = i * part; //开始位置
int to = (i == parallism - 1) ? numbers.length - 1 : (i + 1) * part - 1; //结束位置
//扔给线程池计算
results.add(pool.submit(new SumTask(numbers, from, to)));
}
// 把每个线程的结果相加,得到最终结果 get()方法 是阻塞的
// 优化方案:可以采用CompletableFuture来优化 JDK1.8的新特性
long total = 0L;
for (Future<Long> f : results) {
try {
total += f.get();
} catch (Exception ignore) {
}
}
return total;
}
}
main方法改为:
public static void main(String[] args) {
long[] numbers = LongStream.rangeClosed(1, 10000000).toArray();
Instant start = Instant.now();
Calculator calculator = new ExecutorServiceCalculator();
long result = calculator.sumUp(numbers);
Instant end = Instant.now();
System.out.println("耗时:" + Duration.between(start, end).toMillis() + "ms");
System.out.println("结果为:" + result); // 打印结果500500
}
输出:
耗时:30ms
结果为:50000005000000
- 方案三:采用ForkJoinPool(Fork/Join)
前面花了点时间讲解了 ForkJoinPool 之前的实现方法,主要为了在代码的编写难度上进行一下对比。现在就列出本篇文章的重点——ForkJoinPool 的实现方法。
/**
* 采用ForkJoin来计算求和
* * @author fangshixiang@vipkid.com.cn
* @description //
* @date 2018/11/5 15:09
*/
public class ForkJoinCalculator implements Calculator {
private ForkJoinPool pool;
//执行任务RecursiveTask:有返回值 RecursiveAction:无返回值
private static class SumTask extends RecursiveTask<Long> {
private long[] numbers;
private int from;
private int to;
public SumTask(long[] numbers, int from, int to) {
this.numbers = numbers;
this.from = from;
this.to = to;
}
//此方法为ForkJoin的核心方法:对任务进行拆分 拆分的好坏决定了效率的高低
@Override
protected Long compute() {
// 当需要计算的数字个数小于6时,直接采用for loop方式计算结果
if (to - from < 6) {
long total = 0;
for (int i = from; i <= to; i++) {
total += numbers[i];
}
return total;
} else { // 否则,把任务一分为二,递归拆分(注意此处有递归)到底拆分成多少分 需要根据具体情况而定
int middle = (from + to) / 2;
SumTask taskLeft = new SumTask(numbers, from, middle);
SumTask taskRight = new SumTask(numbers, middle + 1, to);
taskLeft.fork();
taskRight.fork();
return taskLeft.join() + taskRight.join();
}
}
}
public ForkJoinCalculator() {
// 也可以使用公用的线程池 ForkJoinPool.commonPool():
// pool = ForkJoinPool.commonPool()
pool = new ForkJoinPool();
}
@Override
public long sumUp(long[] numbers) {
Long result = pool.invoke(new SumTask(numbers, 0, numbers.length - 1));
pool.shutdown();
return result;
}
}
输出:
耗时:390ms
结果为:50000005000000
可以看出,使用了 ForkJoinPool 的实现逻辑全部集中在了 compute() 这个函数里,仅用了14行就实现了完整的计算过程。特别是,在这段代码里没有显式地“把任务分配给线程”,只是分解了任务,而把具体的任务到线程的映射交给了 ForkJoinPool 来完成。
- 方案四:采用并行流(JDK8以后的推荐做法)
public static void main(String[] args) {
Instant start = Instant.now();
long result = LongStream.rangeClosed(0, 10000000L).parallel().reduce(0, Long::sum);
Instant end = Instant.now();
System.out.println("耗时:" + Duration.between(start, end).toMillis() + "ms");
System.out.println("结果为:" + result); // 打印结果500500
}
输出:
耗时:130ms
结果为:50000005000000
并行流底层还是Fork/Join框架,只是任务拆分优化得很好。
耗时效率方面解释:Fork/Join 并行流等当计算的数字非常大的时候,优势才能体现出来。也就是说,如果你的计算比较小,或者不是CPU密集型的任务,不太建议使用并行处理
原理
**我一直以为,要理解一样东西的原理,最好就是自己尝试着去实现一遍。**根据上面的示例代码,可以看出 fork() 和 join() 是 Fork/Join Framework “魔法”的关键。我们可以根据函数名假设一下 fork() 和 join() 的作用:
- fork():开启一个新线程(或是重用线程池内的空闲线程),将任务交给该线程处理。
- join():等待该任务的处理线程处理完毕,获得返回值。
疑问:当任务分解得越来越细时,所需要的线程数就会越来越多,而且大部分线程处于等待状态?
但是如果我们在上面的示例代码加入以下代码
System.out.println(pool.getPoolSize());
这会显示当前线程池的大小,在我的机器上这个值是4,也就是说只有4个工作线程。甚至即使我们在初始化 pool 时指定所使用的线程数为1时,上述程序也没有任何问题——除了变成了一个串行程序以外。
public ForkJoinCalculator() {
pool = new ForkJoinPool(1);
}
这个矛盾可以导出,我们的假设是错误的,并不是每个 fork() 都会促成一个新线程被创建,而每个 join() 也不是一定会造成线程被阻塞。Fork/Join Framework 的实现算法并不是那么“显然”,而是一个更加复杂的算法——这个算法的名字就叫做work stealing 算法。
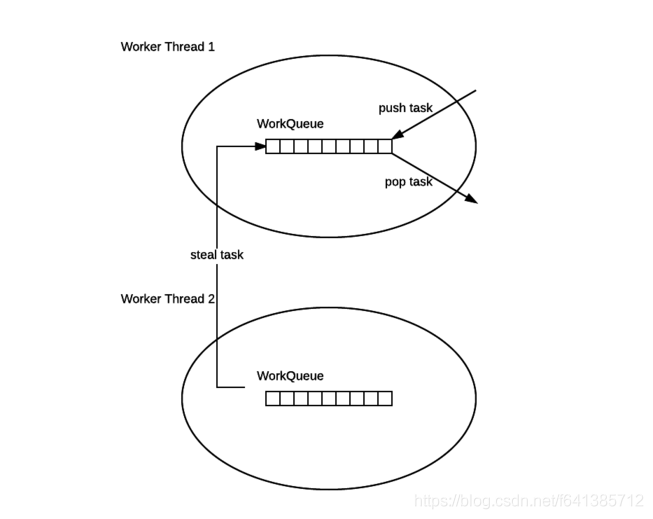
- ForkJoinPool 的每个工作线程都维护着一个工作队列(WorkQueue),这是一个双端队列(Deque),里面存放的对象是任务(ForkJoinTask)。
- 每个工作线程在运行中产生新的任务(通常是因为调用了 fork())时,会放入工作队列的队尾,并且工作线程在处理自己的工作队列时,使用的是 LIFO 方式,也就是说每次从队尾取出任务来执行。
- 每个工作线程在处理自己的工作队列同时,会尝试
窃取一个任务(或是来自于刚刚提交到 pool 的任务,或是来自于其他工作线程的工作队列),窃取的任务位于其他线程的工作队列的队首,也就是说工作线程在窃取其他工作线程的任务时,使用的是 FIFO 方式。 - 在遇到 join() 时,如果需要 join 的任务尚未完成,则会先处理其他任务,并等待其完成。
- 在既没有自己的任务,也没有可以窃取的任务时,进入休眠。
至于Fork和Join源码级别的的细节,本文不做过多描述了~~
submit() 和 fork() 其实没有本质区别,只是提交对象变成了 submitting queue 而已(还有一些同步,初始化的操作)。submitting queue 和其他 work queue 一样,是工作线程”窃取“的对象,因此当其中的任务被一个工作线程成功窃取时,就意味着提交的任务真正开始进入执行阶段。
ForkJoinPool的commonPool相关参数配置
commonPool是ForkJoinPool内置的一个线程池对象,JDK8里有些都是使用它的。他怎么来的呢?具体源码为ForkJoinPool的静态方法:makeCommonPool
private static ForkJoinPool makeCommonPool() {
int parallelism = -1;
ForkJoinWorkerThreadFactory factory = null;
UncaughtExceptionHandler handler = null;
try { // ignore exceptions in accessing/parsing properties
String pp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.parallelism");
String fp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.threadFactory");
String hp = System.getProperty
("java.util.concurrent.ForkJoinPool.common.exceptionHandler");
if (pp != null)
parallelism = Integer.parseInt(pp);
if (fp != null)
factory = ((ForkJoinWorkerThreadFactory)ClassLoader.
getSystemClassLoader().loadClass(fp).newInstance());
if (hp != null)
handler = ((UncaughtExceptionHandler)ClassLoader.
getSystemClassLoader().loadClass(hp).newInstance());
} catch (Exception ignore) {
}
if (factory == null) {
if (System.getSecurityManager() == null)
factory = defaultForkJoinWorkerThreadFactory;
else // use security-managed default
factory = new InnocuousForkJoinWorkerThreadFactory();
}
if (parallelism < 0 && // default 1 less than #cores
(parallelism = Runtime.getRuntime().availableProcessors() - 1) <= 0)
parallelism = 1;
if (parallelism > MAX_CAP)
parallelism = MAX_CAP;
return new ForkJoinPool(parallelism, factory, handler, LIFO_QUEUE,
"ForkJoinPool.commonPool-worker-");
}
参数解释 以及自定义commonPool的参数
通过代码指定,必须得在commonPool初始化之前(parallel的stream被调用之前,一般可在系统启动后设置)注入进去,否则无法生效。
通过启动参数指定无此限制,较为安全
- parallelism(即配置线程池个数)
可以通过java.util.concurrent.ForkJoinPool.common.parallelism进行配置,最大值不能超过MAX_CAP,即32767.
static final int MAX_CAP = 0x7fff; //32767
如果没有指定,则默认为Runtime.getRuntime().availableProcessors() - 1.
自定义:代码指定(必须得在commonPool初始化之前注入进去,否则无法生效)
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "8");
// 或者启动参数指定
-Djava.util.concurrent.ForkJoinPool.common.parallelism=8
- threadFactory:默认为defaultForkJoinWorkerThreadFactory,没有securityManager的话。
- exceptionHandler:如果没有设置,默认为null
- WorkQueue:控制是FIFO还是LIFO
ForkJoinPool 的每个工作线程都维护着一个工作队列(WorkQueue),这是一个双端队列(Deque),里面存放的对象是任务(ForkJoinTask)。
每个工作线程在运行中产生新的任务(通常是因为调用了 fork())时,会放入工作队列的队尾,并且工作线程在处理自己的工作队列时,使用的是 LIFO 方式,也就是说每次从队尾取出任务来执行。
每个工作线程在处理自己的工作队列同时,会尝试窃取一个任务(或是来自于刚刚提交到 pool的任务,或是来自于其他工作线程的工作队列),窃取的任务位于其他线程的工作队列的队首,也就是说工作线程在窃取其他工作线程的任务时,使用的是 FIFO 方式。 - queue capacity:队列容量
继续介绍
创建了ForkJoinPool实例之后,就可以调用ForkJoinPool的submit(ForkJoinTask task) 或invoke(ForkJoinTask task)方法来执行指定任务了。
其中ForkJoinTask代表一个可以并行、合并的任务。ForkJoinTask是一个抽象类,它还有两个抽象子类:RecusiveAction和RecusiveTask。
其中RecusiveTask代表有返回值的任务,
而RecusiveAction代表没有返回值的任务。
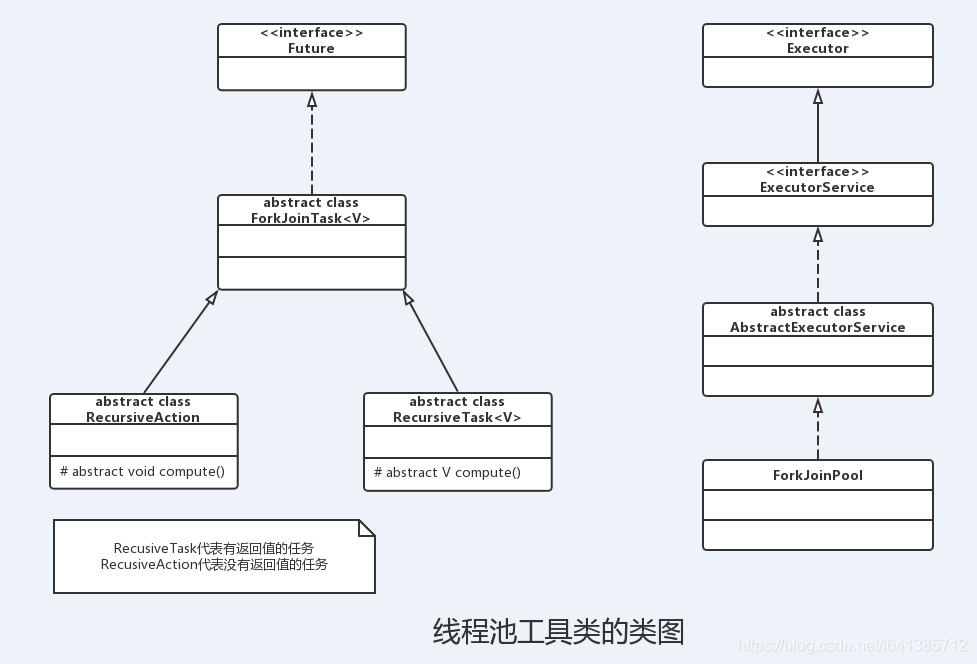
它同ThreadPoolExecutor一样,也实现了Executor和ExecutorService接口。它使用了一个无限队列来保存需要执行的任务,而线程的数量则是通过构造函数传入,如果没有向构造函数中传入希望的线程数量,那么当前计算机可用的CPU数量会被设置为线程数量作为默认值。
ForkJoinPool主要用来使用分治法(Divide-and-Conquer Algorithm)来解决问题。典型的应用比如快速排序算法。
这里的要点在于,ForkJoinPool需要使用相对少的线程来处理大量的任务。
比如要对1000万个数据进行排序,那么会将这个任务分割成两个500万的排序任务和一个针对这两组500万数据的合并任务。以此类推,对于500万的数据也会做出同样的分割处理,到最后会设置一个阈值来规定当数据规模到多少时,停止这样的分割处理。比如,当元素的数量小于10时,会停止分割,转而使用插入排序对它们进行排序。
那么到最后,所有的任务加起来会有大概2000000+个。问题的关键在于,对于一个任务而言,只有当它所有的子任务完成之后,它才能够被执行。
所以当使用ThreadPoolExecutor时,使用分治法会存在问题,因为ThreadPoolExecutor中的线程无法像任务队列中再添加一个任务并且在等待该任务完成之后再继续执行。而使用ForkJoinPool时,就能够让其中的线程创建新的任务,并挂起当前的任务,此时线程就能够从队列中选择子任务执行。
使用ThreadPoolExecutor或者ForkJoinPool,会有什么性能的差异呢?
使用ForkJoinPool能够使用数量有限的线程来完成非常多的具有父子关系的任务,比如使用4个线程来完成超过200万个任务。但是,使用ThreadPoolExecutor时,是不可能完成的,因为ThreadPoolExecutor中的Thread无法选择优先执行子任务,需要完成200万个具有父子关系的任务时,也需要200万个线程,显然这是不可行的。
这就是工作窃取模式的优点
总结
在了解了 Fork/Join Framework 的工作原理之后,相信很多使用上的注意事项就可以从原理中找到原因。例如:为什么在 ForkJoinTask 里最好不要存在 I/O 等会阻塞线程的行为?,这个各位读者可以思考思考了
还有一些延伸阅读的内容,在此仅提及一下:
- ForkJoinPool 有一个 Async Mode ,效果是工作线程在处理本地任务时也使用 FIFO 顺序。这种模式下的 ForkJoinPool 更接近于是一个消息队列,而不是用来处理递归式的任务。
- 在需要阻塞工作线程时,可以使用 ManagedBlocker。
- Java 1.8 新增加的 CompletableFuture 类可以实现类似于 Javascript 的 promise-chain,内部就是使用 ForkJoinPool 来实现的。
彩蛋
人们之所以总是忘记使用标准的 Java 对象是因为缺少一个足够装逼的名字(译注:类似于 Java Bean 这样的名字)。因此,在准备2000年的演讲时,Rebecca Parsons,Josh Mackenzie 和我给他们起了一个名字叫做 POJO (平淡无奇的 Java 对象)。
有些东西,有些技术如果没有一个够装逼的名字,也是很难被人们记住的。。。吼吼吼
关注A哥
| Author | A哥(YourBatman) |
|---|---|
| 个人站点 | www.yourbatman.cn |
| yourbatman@qq.com | |
| 微 信 | fsx641385712 |
活跃平台 |         |
| 公众号 | BAT的乌托邦(ID:BAT-utopia) |
| 知识星球 | BAT的乌托邦 |
| 每日文章推荐 | 每日文章推荐 |


{kind=link}
{kind=link}