TCP的错误恢复特性是我们用来定位、诊断并最终修复网络高延迟的最好工具。
常见的TCP错误恢复特性有:TCP重传、TCP重复确认和快速重传。
重传数据包是TCP最基本的错误恢复特性之一,用来对付数据包的丢失。
数据包丢失可能原因有很多,如:出故障的应用程序、流量负载沉重的路由器或临时性的服务中断。
数据包层次上的移动速度非常快,而且数据包丢失通常都是暂时的,因此TCP能否检测到数据包丢失并恢复至关重要。
如何决定是否重传:
决定是否重传数据包的主要机制叫做:重传计时器,这个计时器负责维护一个重传超时(RTO--Retransmission timeout)的值。
当使用TCP传输一个数据包时,就启动重传计时器,当收到这个数据包的ACK应答时,计时器就停止。从发送数据包到接收ACK确认之间的时间被称为往返时间(Round-Trip time,RTT),若干个这样的时间平均下来,可计算出最终的RTO值。
一旦RTO值确定下来,重传计时器就被用于每个传输的数据包,以确定数据包是否丢失。

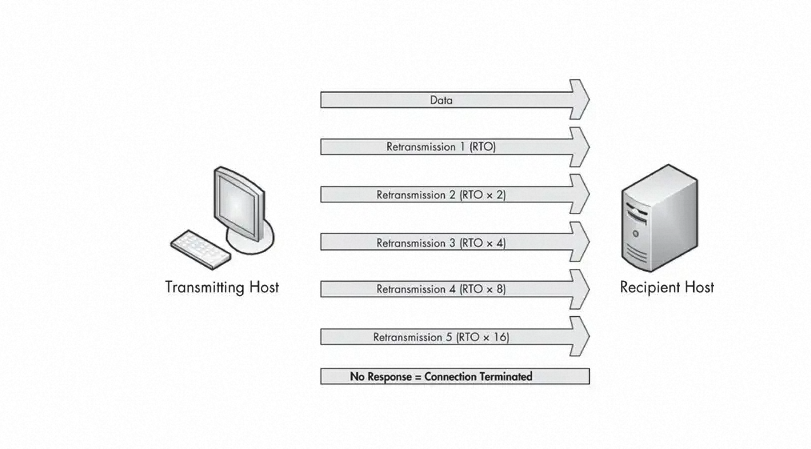
当报文发送之后,但接收方尚未发送TCP ACK报文,发送方假设源报文丢失并将其重传。重传之后,RTO值加倍;如果在2倍RTO值到达之前还是没有收到ACK报文,就再次重传。如果仍然没有收到ACK,那么RTO值再次加倍。如此持续下去,每次重传RTO都翻倍,直到收到ACK报文或发送方达到配置的最大重传次数。
最大重传次数取决于发送操作系统的配置值。
默认情况下,Windows主机默认重传5次。大多数Linux系统默认最大15次,两种操作系统都可配置。
TCP重传率是网络质量的体现,网络这块我们主要看TCP重传率,这个基本在大点的公司都有这块监控。
TCP重传率=单位时间内TCP重传包数量/TCP发包总数
我们可以把TCP重传率视为网络质量和服务器稳定性的一个只要衡量指标。
还是根据我们的经验,这个TCP重传率越低越好,越低代表我们的网络越好,如果TCP重传率保持在0.02%(以自己的实际情况为准)以上,或者突增,就可以怀疑是不是网络问题了。

比如这张图一样,要是和心电图一样,基本上网络问题就没跑了。
参考
一分钟理解TCP重传
https://mp.weixin.qq.com/s/f-lxycgqwZyHCZcPIpb_tg
谈谈Linux中的TCP重传抓包分析
https://cloud.tencent.com/developer/article/1464243
关于TCP重传问题的排查思路与实践
https://blog.csdn.net/wufaliang003/article/details/90664256
TCP重传率高的监控
https://blog.csdn.net/weixin_30648963/article/details/99459391
用zabbix 监控TCP重传率
https://mp.weixin.qq.com/s/iNvCU40qHyVJrku5K1cP-Q
TCP协议的深入学习和利用wireshark排查TCP通信的故障视频教程
https://edu.51cto.com/course/8385.html
网络协议 TCP/IP 视频教程全集
https://www.bilibili.com/video/BV1Pt41137w6?p=1
使用Wireshark抓包排查网络故障和分析TCP/IP协议
https://edu.51cto.com/course/15139.html
https://edu.51cto.com/courselist/index.html?q=wireshark
使用ss命令对tcp连接数和状态的监控性能优化
https://www.bbsmax.com/A/obzb2gL0zE
关于TCP重传的监控
https://blog.csdn.net/beeworkshop/article/details/103841211
https://github.com/alibaba/tsar
作者:Bogon
链接:https://www.jianshu.com/p/3433c347149b
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
