一、前言
第一版的接口响应时长分布统计图表是根据 Prometheus Counter 数据类型制作的折线图,它大概长下面这个样子。
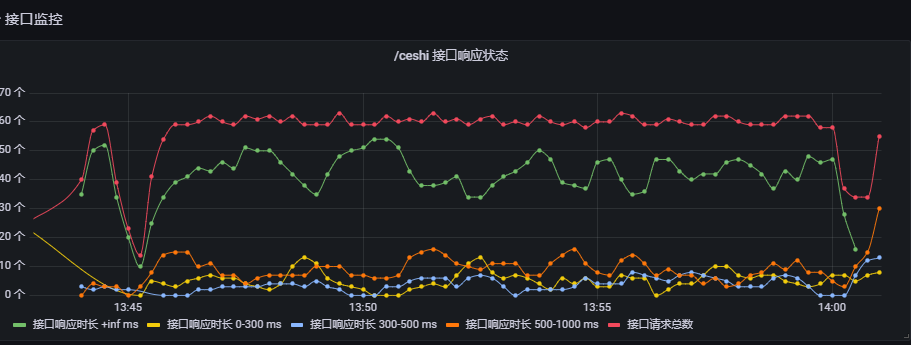
原理其实也非常简单,我就是将请求分组进行统计。大致的代码就是下面这个样子
// UploadAPIRequestDurationCounter 上报接口请求时长
func (s *apiMetrics) UploadAPIRequestDurationCounter(method, endpoint string, duration time.Duration) {
getDurationLabel := func(duration time.Duration) string {
d := duration.Milliseconds()
switch {
case d <= 300: // 接口小于 300 ms
return "0-300"
case d <= 500: // 接口响应在 300 - 500 ms
return "300-500"
case d <= 1000: // 接口响应在 500ms -1 s 之间
return "500-1000"
default:
return "+inf"
}
}
s.apiRequestDuration.With(prometheus.Labels{"method": method, "endpoint": endpoint, "duration": getDurationLabel(duration)}).Inc()
}奈何领导说接口统计最好不要用 counter 计数器,也不要做成折线图。要使用 Prometheus 中的另外一个数据类型 Histogram。没法子,我只能重新再做个图。
二、Histogram 释义
先让我们看看所谓 Histogram 的解释。
Histogram 是一种Prometheus 提供的数据类型(累积直方图)在大多数情况下人们都倾向于使用某些量化指标的平均值,例如CPU的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统API调用的平均响应时间为例:如果大多数API请求都维持在100ms的响应时间范围内,而个别请求的响应时间需要5s,那么就会导致某些WEB页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。例如,统计延迟在0~10ms之间的请求数有多少而10~20ms之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram和Summary都是为了能够解决这样问题的存在,通过Histogram和Summary类型的监控指标,我们可以快速了解监控样本的分布情况。
比如我下面的 Golang 代码,我定义了一个 Histogram ,其中相应的响应时长分割为 0-10 ms、10-20ms、20-30ms........等多个 bucket (桶)
apiRequestDurationHistogram: prometheus.NewHistogramVec(prometheus.HistogramOpts{
Name: "api_request_duration_histogram",
Help: "请求时长直方图",
Buckets: []float64{10, 20, 30, 60, 80, 100, 600, 900, 1000, 1300, 1600, 1900, 2100, 30000}, // 桶的分布,单位 ms
}, []string{"method", "endpoint"}), // method标签:请求方法、endpoint:请求的 URI我在请求开始前计时,请求结束后停止计时,得出的时间结果使用下面这个方法记录。
// UploadAPIRequestDurationHistogram 上报接口请求时长
func (s *apiMetrics) UploadAPIRequestDurationHistogram(method, endpoint string, duration time.Duration) {
s.apiRequestDurationHistogram.With(prometheus.Labels{"method": method, "endpoint": endpoint}).
Observe(float64(duration.Milliseconds()))
}他就会将响应时长根据我们分的时间间隔落入对应的 bucket 中。也就是上面提到的 0-10 ms、10-20ms、20-30ms......
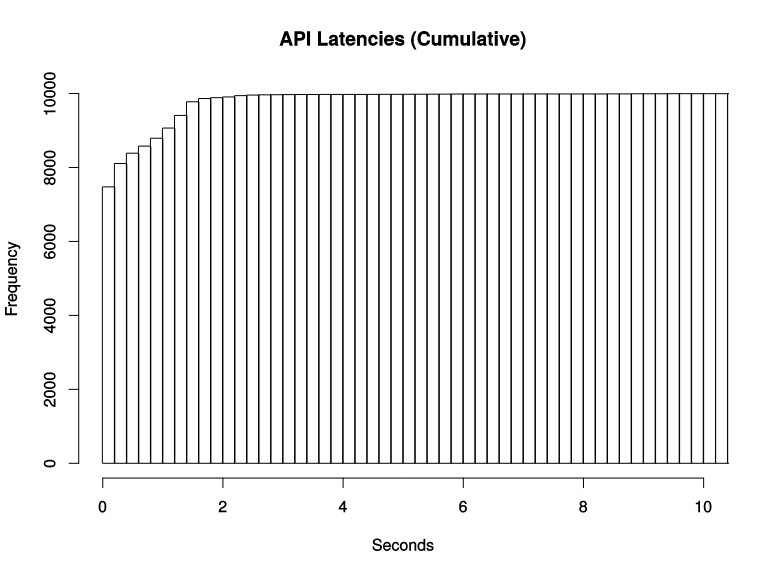
但是这里需要注意的是,Histogram 之所以叫累积直方图,它记录的实际数值可能和我们预想的不一样。
举个例子:我们的 bucket 为 0,200,500,1000 (单位ms) 来统计我们的接口响应时长,某个接口响应时间为 180ms,此时我们的直觉是,他只会落入 0-200ms 的这个 bucket。
但实际上,他还会落入 200-500ms、500-1000ms 的bucket,也就是说,每一个 bucket 的样本包含了之前所有 bucket 的样本,所以叫累积直方图。
用知乎里的一张图就能很明显看出来
但是这种特性我怎样才能用 PromQL 统计指标,在 Grafana 图表上展示呢?
三、Histogram 绘制热点图
与 Histogram 数据类型最为搭配的就是 Grafana 中的 Heatmap (热点图)
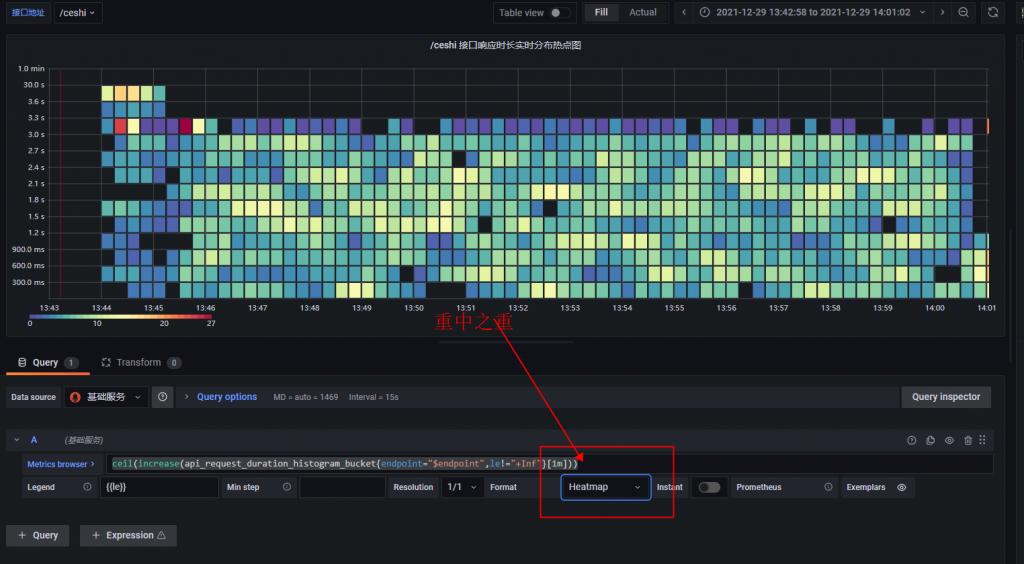
先看看最终成果,如下所示
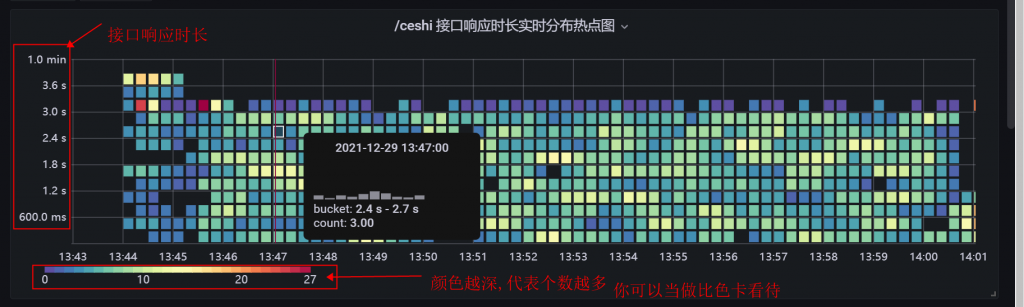
我们需要实现的是 X 轴代表时间, Y 轴代表接口响应时长。图中每个彩色方块代表那个时间点对应的接口响应时长与个数。
颜色越深越红,代表那个时间分布的接口数量越多。它的响应时长就是对应的 Y 轴
通过上面这张图我们一眼就能看到接口响应时间分布的热点是哪个了。
关于热点图的配置,首先你需要用采集 Histogram 类型的数据,然后在 Grafana 上进行配置。
关于配置这里我直接截图,展示我 Grafana 的配置,重点的都用红色方框圈出来了(缺一不可)
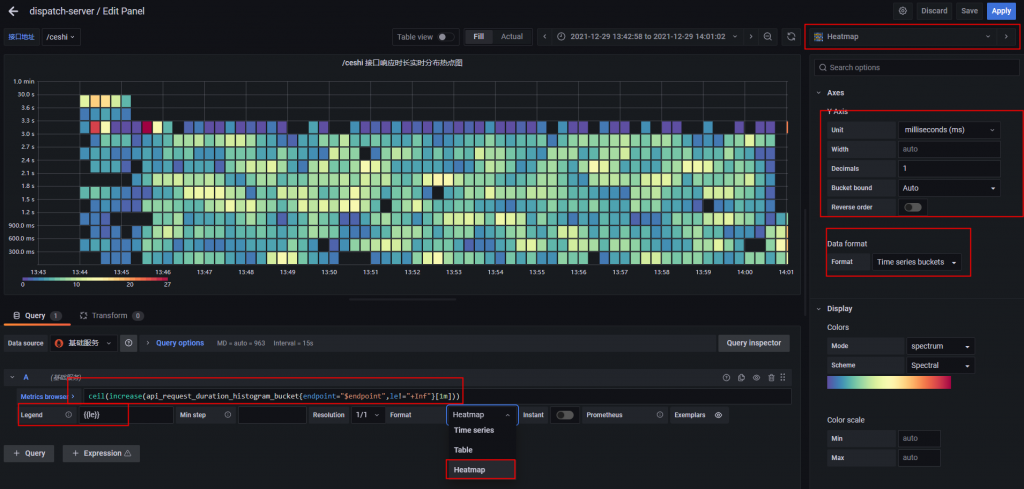
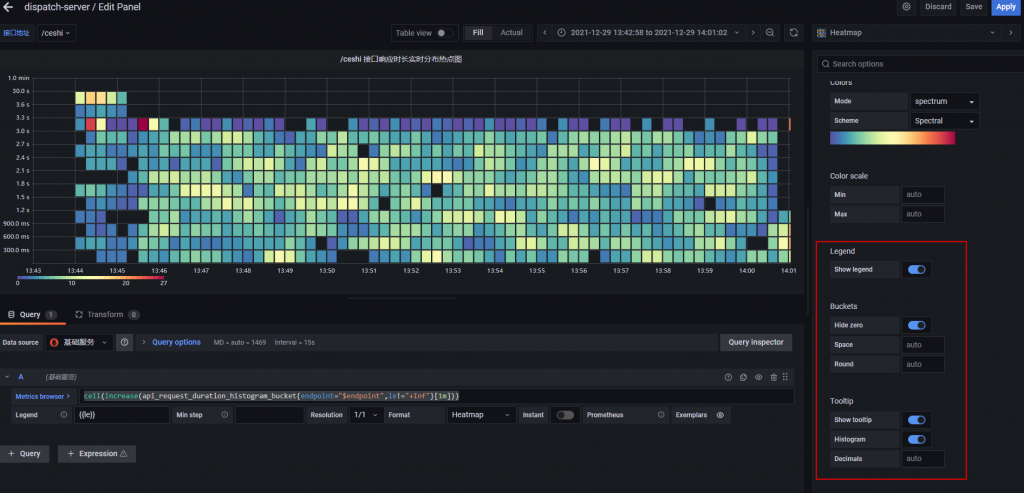
ceil(increase(api_request_duration_histogram_bucket{endpoint="$endpoint",le!="+Inf"}[1m])) // 这句 PromQL 的意思代表监测某 URI 下1分钟里,Histogram 内各接口落入各自 bucket 的增长数量。由于bucket的数量是一直增长的,因此我们可以理解为这是统计了一分钟以内各接口所在响应区间的数量。其中 $endpoint 变量是我的 Grafana 变量 (URI)一些人可能没有将下图的这个选项选上,导致图的数据不符合预期,请注意这是重点。因此我再截了一次图让各位看清
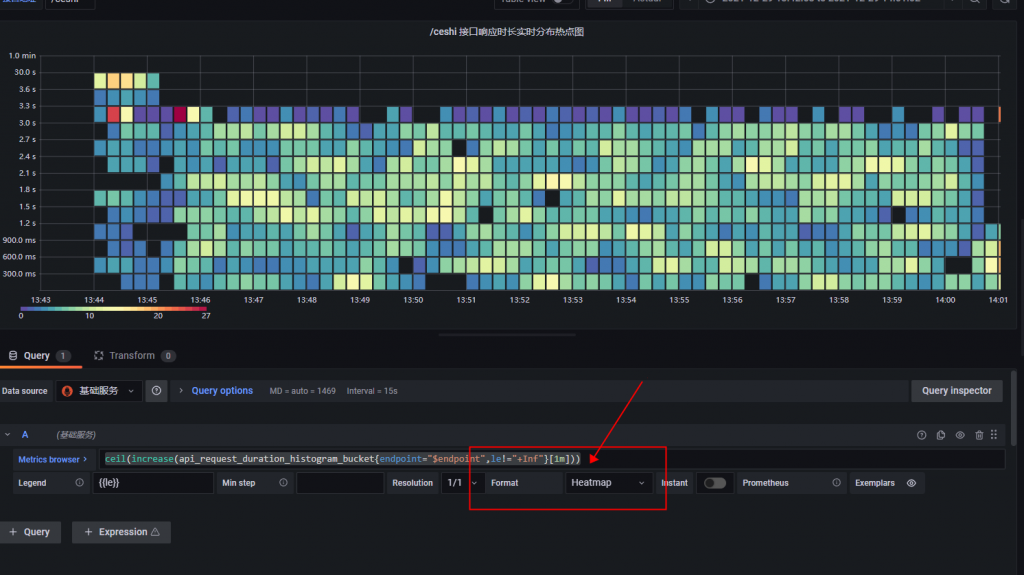
如果没选上就会导致图是倒过来的。错误示例如下所示
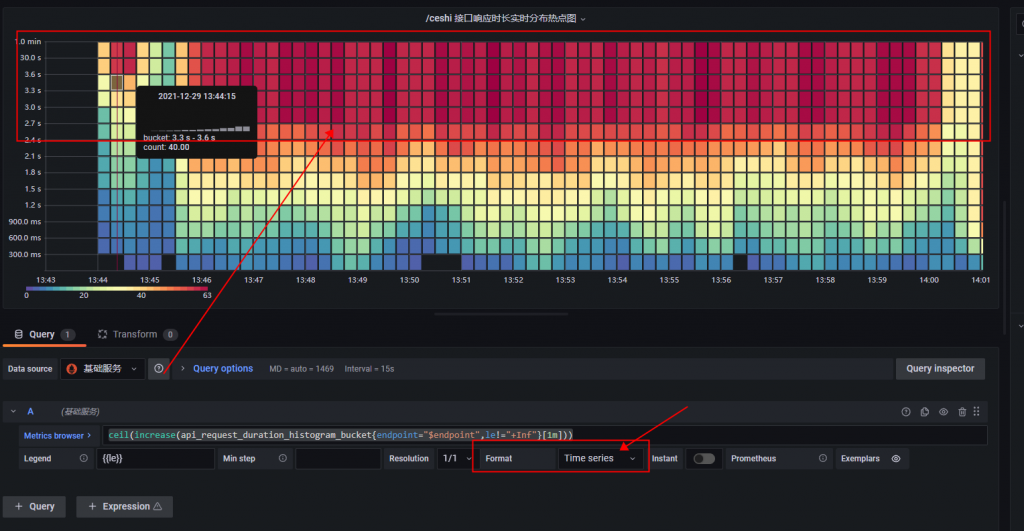
正如 Histogram 累积直方图,你看到的反而接口响应时长最大的数量最多,这是因为累积直方图的特性,,每一个 bucket 的样本包含了之前所有 bucket 的样本。
因此再三提醒,请注意将 Format 选成 Heatmap 。
本文来自:www.xhyonline.com
感谢作者:www.xhyonline.com
查看原文:Prometheus Histogram + Grafana 绘制接口响应热点图 – 兰陵美酒郁金香的个人博客
