作者:Carlos Arilla
翻译:bot(才云)
校对:星空下的文仔(才云)
在生产环境中,如何设置 Kubernetes 的 Limit 和 Request 对于优化应用程序和集群性能至关重要。
矛盾的是,分布式系统旨在解决应用程序之间的资源共享问题(例如 Kubernetes),但它们面临的挑战之一却是如何正确共享资源。
在以前,应用程序通常被设计为独立运行,并可以使用现有的所有资源。但随着企业应用程序数量的急剧增长和对系统稳定、弹性要求的提升,新格局下,应用程序之间需要共享相同的资源,这使得资源合理配置成了一个硬性要求。
命名空间配额
众所周知,Kubernetes 是允许管理员在命名空间中指定资源 Request 和 Limit 的,这一特性对于资源管理限制非常有用。但它目前还存在一定局限:如果管理员在命名空间中设置了 CPU Request 配额,那么所有 Pod 也要在其定义中设置 CPU Request,否则就无法被调配资源。
下面是一个例子:
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu-example
spec:
hard:
requests.cpu: 2
requests.memory: 2Gi
limits.cpu: 3
limits.memory: 4Gi如果我们把这个文件应用于命名空间,它会设置以下限制:
- 所有 Pod 容器都必须声明对 CPU 和 RAM 的 Request 和 Limit;
- 所有 CPU Requests 的总和不能超过 2 个内核;
- 所有 CPU Limits 的总和不能超过 3 个内核;
- 所有 RAM Requests 的总和不能超过 2 GiB;
- 所有 RAM Limits 的总和不能超过 4 GiB。
假设我们已经为其他 Pods 分配了 1.9 个内核,开始响应新 Pod 提出的 200m CPU 分配请求,那么由于超过了最大 Request 限制,这个 Pod 会一直保持“Pending”状态,无法被调度。
什么是 Pod Request 和 Limit
下面是一个部署示例:
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: redis
labels:
name: redis-deployment
app: example-voting-app
spec:
replicas: 1
selector:
matchLabels:
name: redis
role: redisdb
app: example-voting-app
template:
spec:
containers:
- name: redis
image: redis:5.0.3-alpine
resources:
limits:
memory: 600Mi
cpu: 1
requests:
memory: 300Mi
cpu: 500m
- name: busybox
image: busybox:1.28
resources:
limits:
memory: 200Mi
cpu: 300m
requests:
memory: 100Mi
cpu: 100m假设我们正在运行一个具有 4 个内核和 16GB RAM 节点的集群:

- Pod 的有效 Request 是 400MiB 的内存和 600 毫核(millicore)的 CPU。我们需要一个具有足够可用可分配空间的节点来调度 Pod;
- Redis 容器共享的 CPU 资源份额为 500,busybox 容器的 CPU 份额为 100。由于 Kubernetes 会把每个内核分成 1000 个 shares,因此:
- Redis:1000m*0.5cores≅500m
- busybox:1000m*0.1cores≅100m
- 如果 Redis 容器尝试分配超过 600MB 的 RAM,就会被 OOM-killer;
- 如果 Redis 容器尝试每 100ms 使用 100ms 以上的 CPU,那么 Redis 就会受到 CPU 限制(一共有 4 个内核,可用时间为 400ms/100ms),从而导致性能下降;
- 如果 busybox 容器尝试分配 200MB 以上的 RAM,也会引起 OOM;
- 如果 busybox 容器尝试每 100ms 使用 30ms 以上的 CPU,也会使 CPU 受到限制,从而导致性能下降。
为了发现这些问题,我们应该监控:
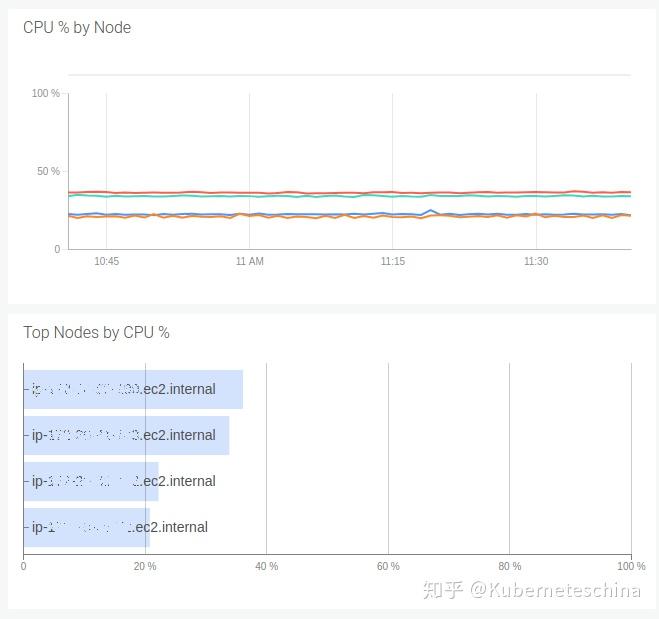
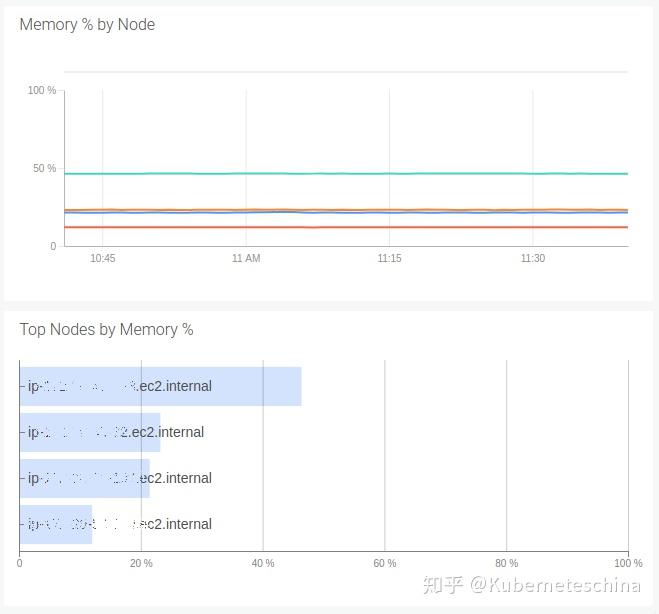
节点中的 CPU 和 RAM 使用情况。如果节点内存已满,尽管所有容器都在它们的 Limits 之下,内存压力仍然会触发 OOM-killer。CPU 压力会限制进程并影响性能。
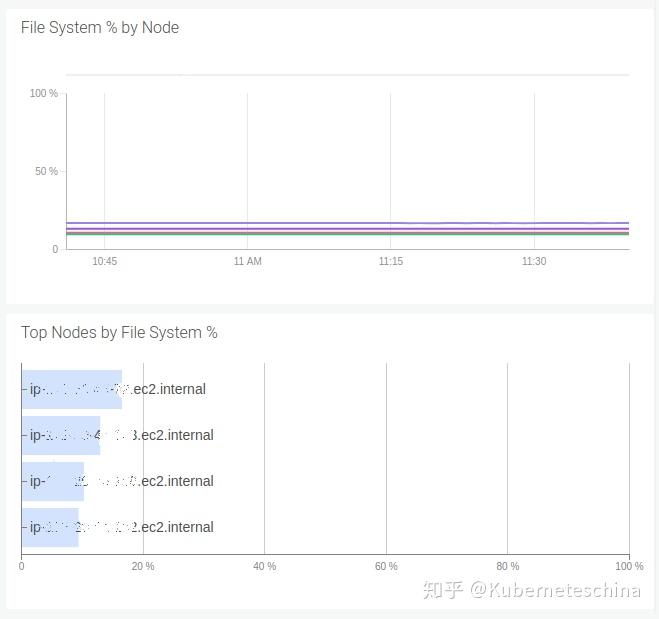
节点中的磁盘空间。如果节点耗尽磁盘,它会释放磁盘空间,而且很可能会驱逐 Pod。
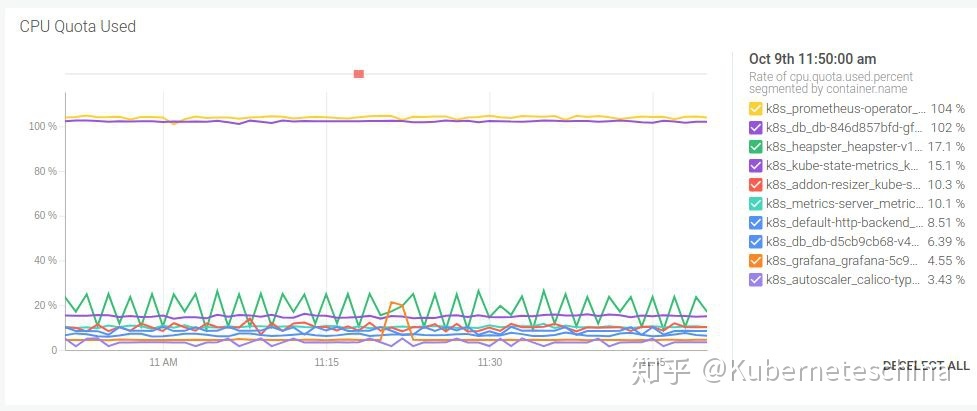
每个容器使用的 CPU 配额百分比。需要注意的是,监控 Pod 的 CPU 使用可能是不够的,Kubernetes 限制的是每个容器,而不是每个 Pod。其他 CPU 指标,如共享 CPU 资源使用情况,只对分配有参考价值,所以如果遇到了性能上的问题,建议不要在这些指标上浪费时间。
每个容器的内存使用量。这个值可以和内存 Limit 或内存 Limit 百分比放在一起对比。同样的,不要看 Pod 的内存使用量,在这个例子里,一个 Pod 可以使用 300MiB 的 RAM,远远低于 Pod 的内存 Limit(400MiB),但是如果 Redis 容器使用 100MiB,busybox 容器使用 200MiB,这个 Pod 就会 fail。
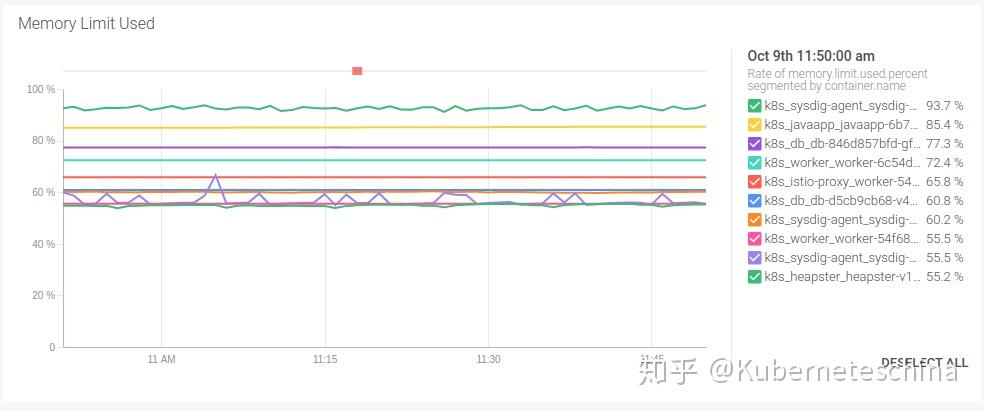
集群和节点中资源分配的百分比。也就是从总可用资源中分配得到的资源占比,一般建议把警告预置设为 (n-1)/n*100,其中 n 是节点数量。如果一个节点出现故障,我们就没法在其他节点中重新分配工作负载。
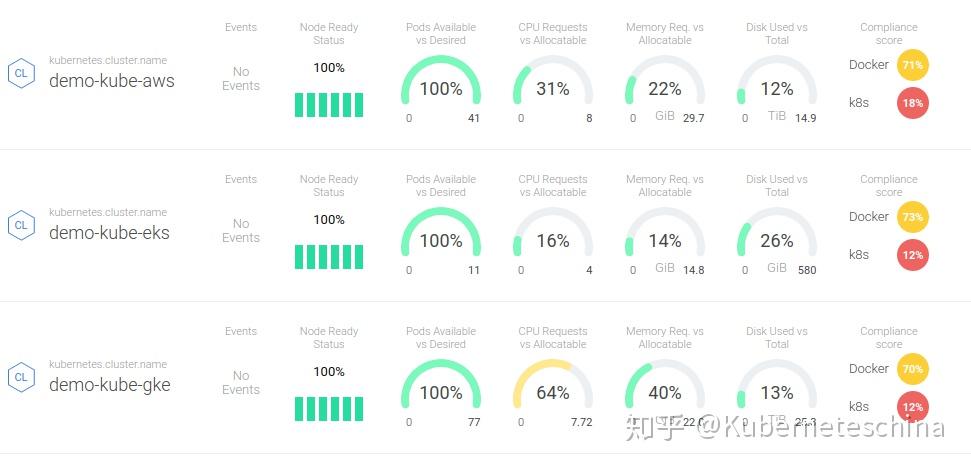
Limit 过量使用(CPU、RAM)。观察这一点的最好方法是看总可分配资源中, Limit 资源所占的百分比,这在正常操作中可能超过 100%。
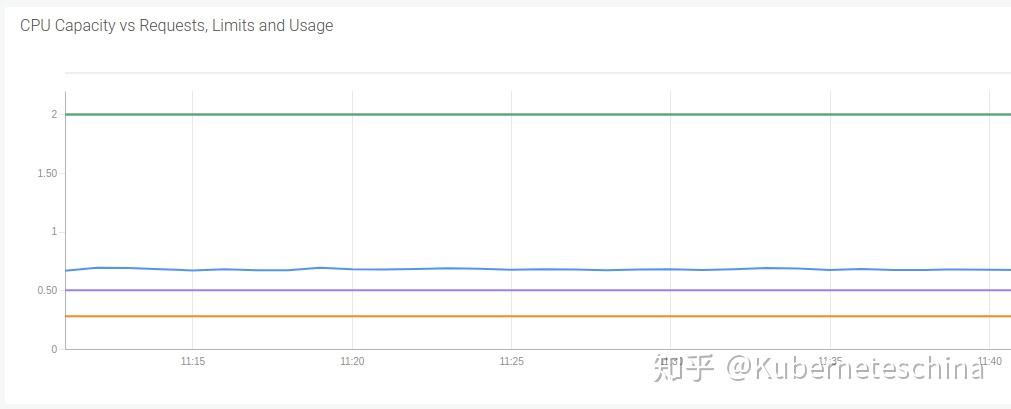
选择可靠的 Request 和 Limit
具备一定 Kubernetes 经验的人都知道正确设置 Request 和 Limit 对于应用程序和集群的性能的重要性。
理想情况下,Pod 请求多少资源,它就用多少资源,但在现实场景下,资源使用是不断变化的,而且它的变化没有规律,不可预测。
如果 Pod 的资源使用量远低于请求量,那会导致资源(金钱)浪费;如果资源使用量高于请求量,那就会使节点出现性能问题。因此在实际操作中,我们可以把 Request 值上下浮动 25% 作为一个良性参考标准。
而关于 Limit,设置合理的 Limit 数值其实需要尝试,因为它主要取决于应用程序的性质、需求模型、对错误的容忍度以及许多其他因素,没有固定答案。
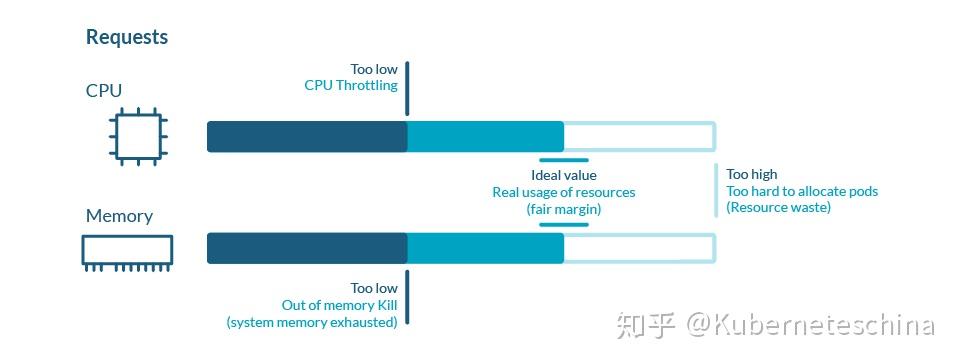
另一件需要考虑的事是在节点上允许的 Limits 过量使用。
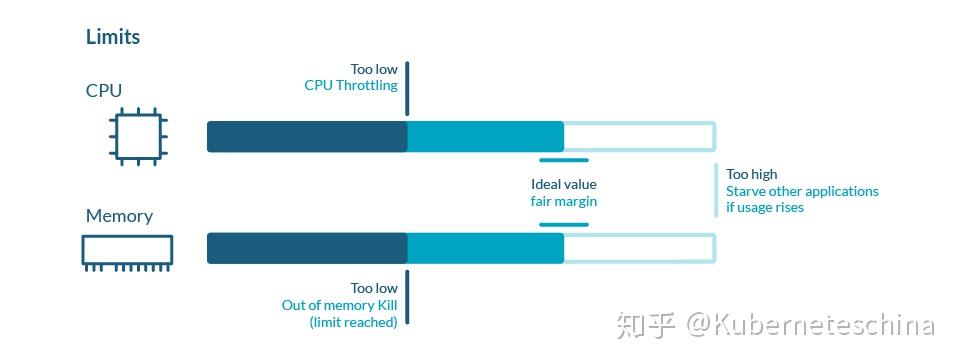
这些 Limits 由用户执行,因为 Kubernetes 没有关于超额使用的自动化机制。
小结
读到这里,最后我们再重申两个重点:
- 尊敬的开发人员,请在你的工作负载中设置 Request 和 Limit;
- 尊敬的集群管理员,设置命名空间配额会强制命名空间中的所有工作负载的容器中使用该 Request 和 Limit。
配额是正确共享资源的必要条件。如果有人告诉你可以无限制地使用任何共享服务,别听他的,拒绝背锅。
