prometheus的step,durations,rate interval,scrape interval对数据查询结果的影响
1、场景:在查询prometheus数据时出现很多诡异的现象
1、为什么同样的查询语句在不同的时间点查询,对过去某一时刻的数据展示却不一样
2、为什么有时候峰值在使用不同step,不同duration查询时,会不一样,甚至消失
3、为什么scrape interval变化了,会使某些规则的结果不准确
等等疑问
2、原理剖析:rate与irate,step,datapoint,scape_internal,instant vector selector,range vector selector
2-1、rate与irate的查询原理见之前博文:【博客486】prometheus-----rate,irate,increase的原理
2-2、step and datapoint and scape_internal:
data point:prometheus按照scrape_interval频率对metrics url进行抓取的原始数据
step:进行范围查询的时候,计算的步长是step这么长
scape_internal:prometheus按照scrape_interval频率对metrics url进行抓取
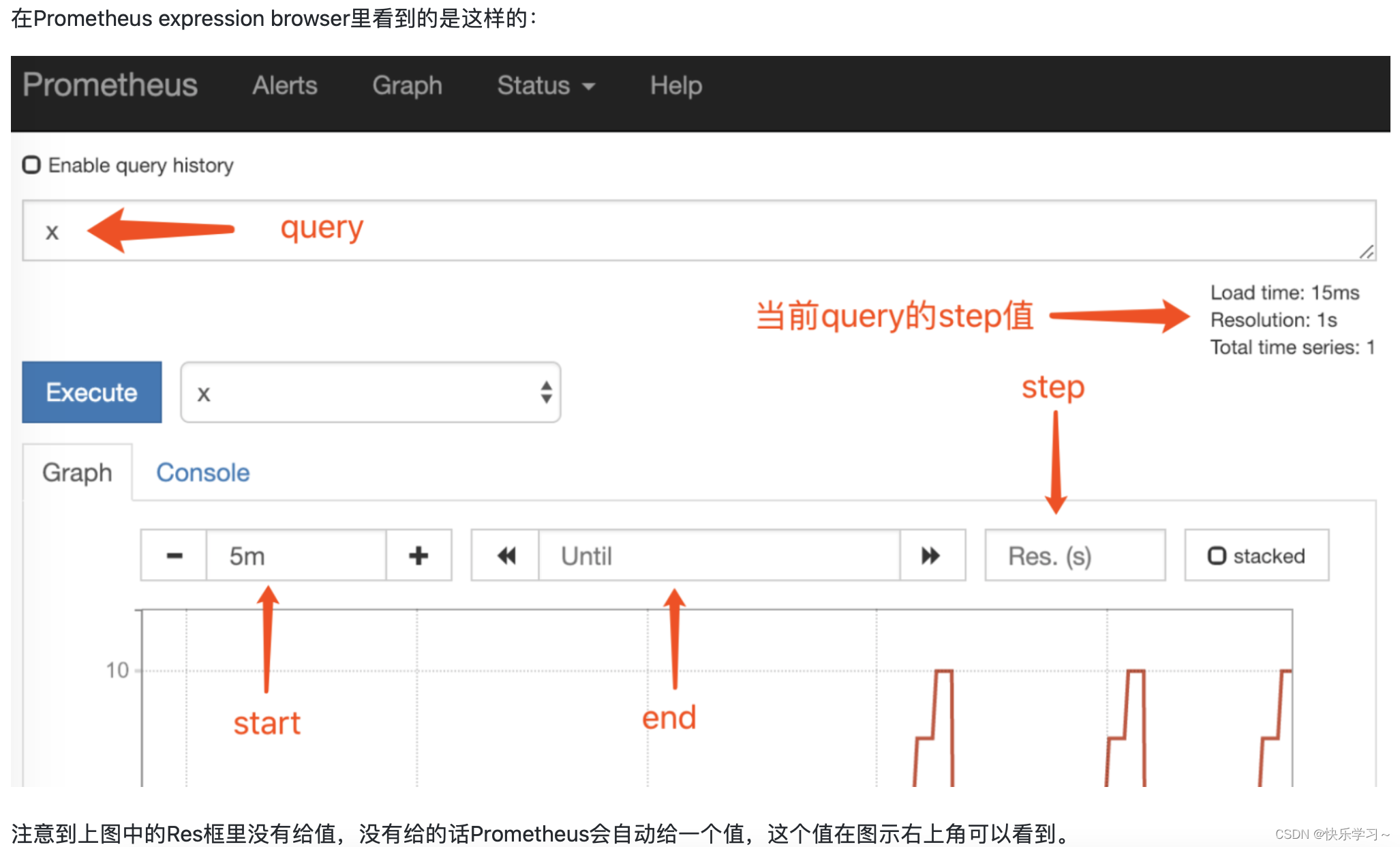

2-3、Instant vector selector与Range vector selector:
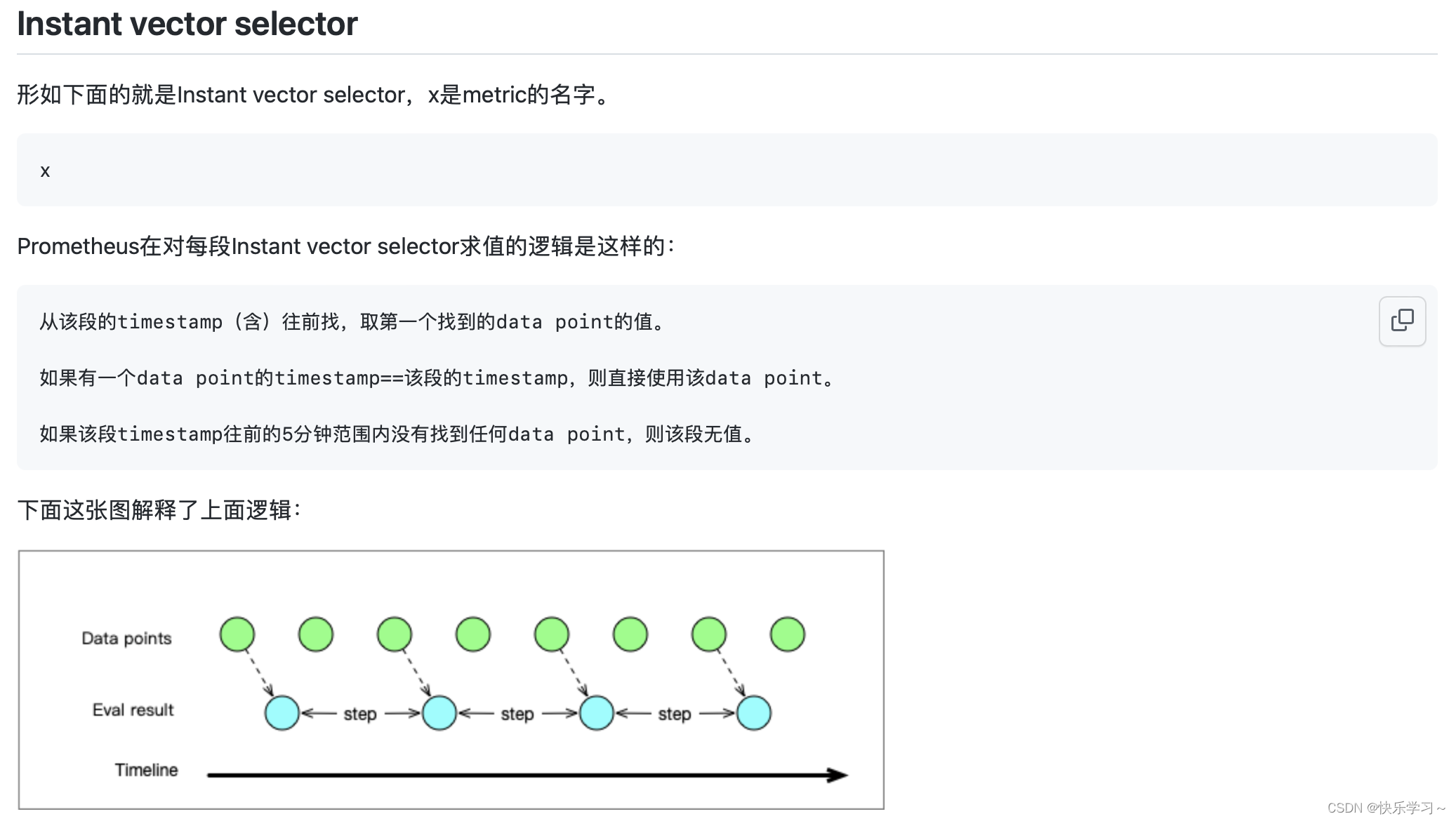
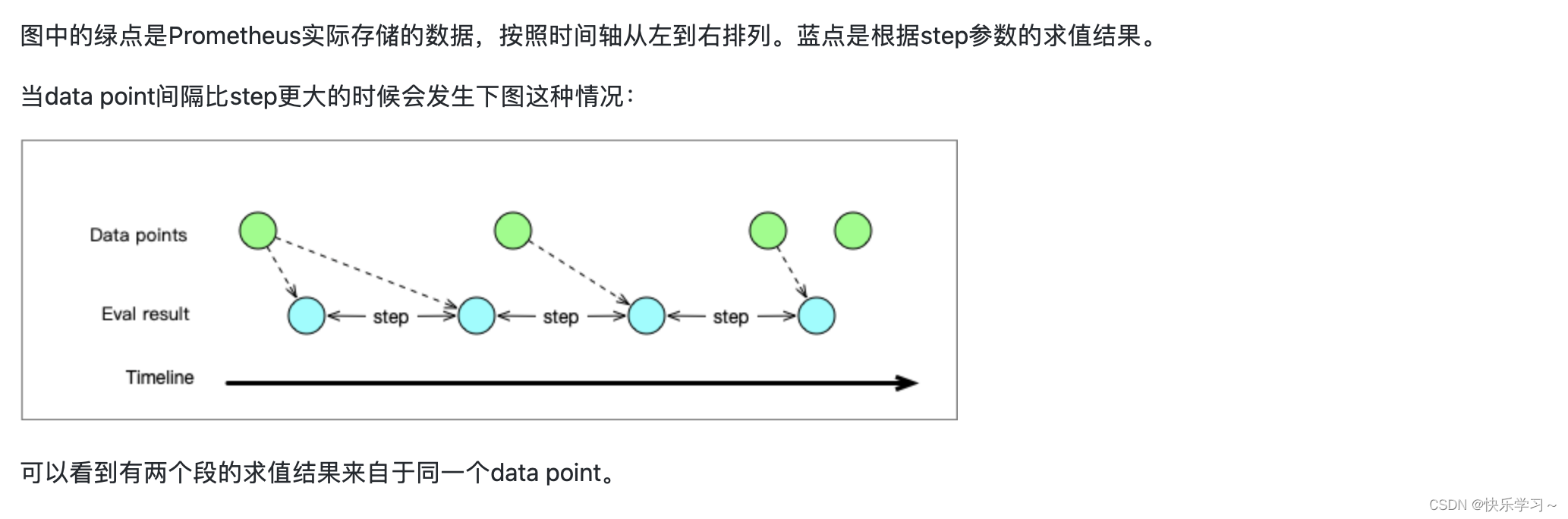
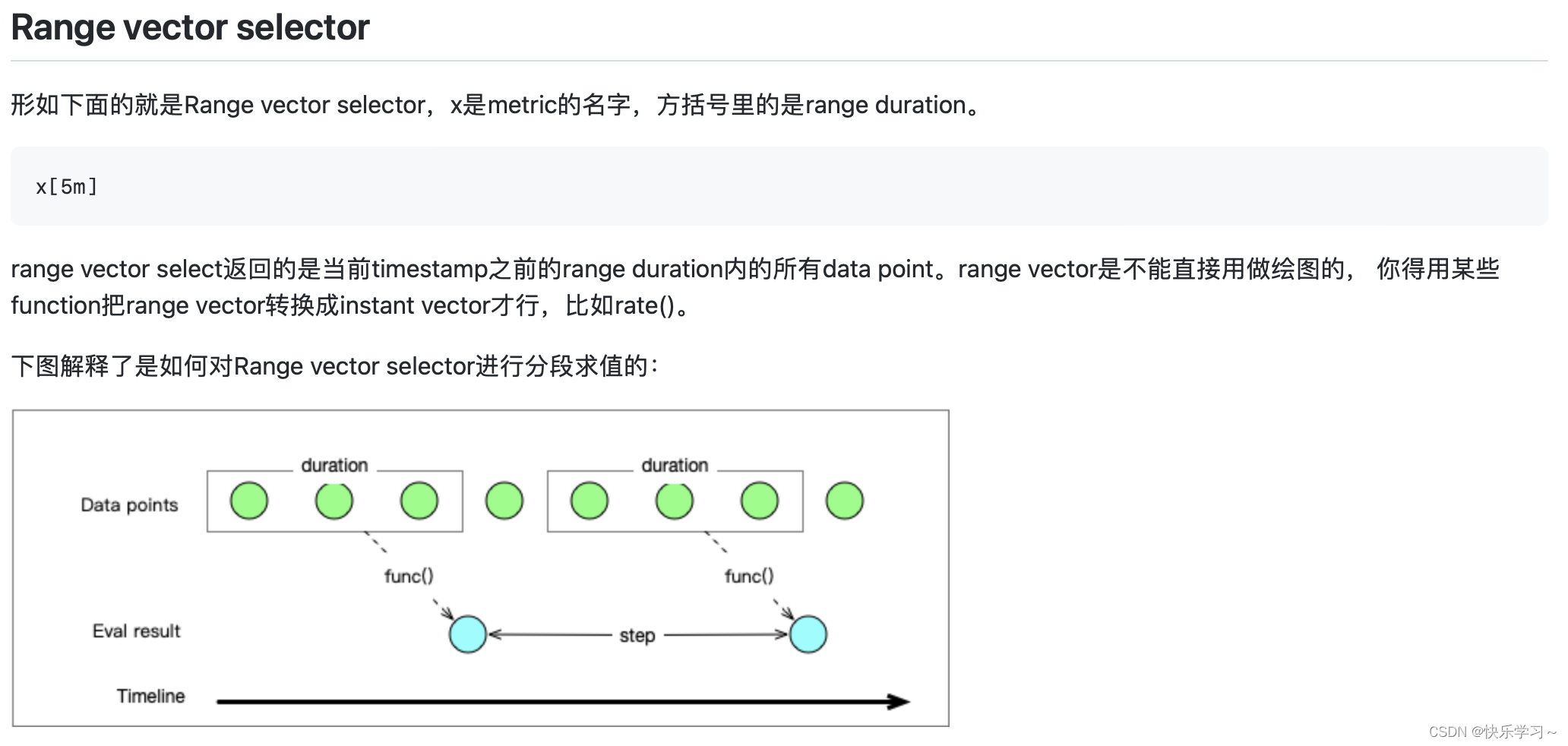
3、一条数据的查询结果受哪几个因素影响
3-1、影响因素:
1、scrape_interval
2、step
3、rate duration
4、query duration
3-2、rate查询语句格式:
rate(metrics_name[interval])
3-3、每个因素发挥的作用:
举例:查询最近3天x指标的增长速率:
curl ‘http://localhost:9090/api/v1/query_range?query=rate(x[10s])&start=2022-12-07T20:00:00.781Z&end=2022-12-10T20:00:00.781Z&step=30s’
1、scrape_interval:data point采样频率,决定了每个step计算值的时候,附近是哪些data point或者有没有data point
2、step:采样的步长,就是查最近3天的数据,对每step时长就计算一个速率值
3、rate duration:计算一个速率的值的时候的选择区间
4、query duration:查询的区间,就是最近3天
4、常见现象剖析
4-1、进行rate查询时,结果不同,甚至有时候严重失真
可能的错误结果1:展示时遗漏部分data point数据带来的错失部分峰值信息:
假设查询: rate(x[5s]),step为10s,查询过去一天的数据
结果分析: 那么rate在计算的时候会丢失一半的数据,两个分段之间的data point有一半没有被纳入计算。假设查询最近10s,然后rate每5s算一个点,但你每10s才收一个点来展示,展示漏了部分点,可能导致部分峰值信息被遗漏。
建议: 因此在使用rate()时,range duration得大于等于step。
可能的错误结果2:重复计算data point数据带来的部分假峰值信息:
假设查询: rate(x[5s]),scrape_interval为10s,step为5s,查询过去一天的数据
结果分析: 那么rate在计算的时候会重复计算一些数据,因为你step也是5s,那么rate每5s算一个点,且按照step来展示结果,但是你采集的时候10s才采集一个data point,那么其实多个step可能计算的时候取的是同一个data point。比如:采集点0s和10s,你按照step的5s来采集结果,那你在0s和5s时两个点都取了0s的结果,因为下一个data point在10s才有,可能导致部分峰值信息被遗漏。
建议: 因此在使用rate()时,range duration得大于等于scrape_interval和step。
4-2、同样的step,rate语句,time duration区间,但是对于历史时间点的结果有些变化或者消失了
假设查询: rate(x[5s]),scrape_interval为3s,step为5s,查询过去6小时的数据
重复执行多次,得到不同结果:查询今天0点到6点,和今天1点到7点这两段的数据,都包含了今天3点的数据结果,但是两次区间对今天3点附近的展示结果却不一样,可能按照0点到6点查询,3点的时候有峰值,按照1点到7点查询,则峰值不见卢,为什么对历史数据查询会不一样呢,历史数据不是既定事实了吗?
结果分析:因为你用不同的查询区间,那么step最近切出来start和end不一定一样,当时data point选择也不一样的。比如:
有data point:p1 p2 p3 p4 p5 p6
对应的值分别为:0,1000,0,1000,0
如果计算速率的时候,你start和end不定,查询区间如果起始是p1,数据点值选了0的几个,结果是:0
0,1000,0,1000,0
|----------|------------|
查询区间如果起始是p2,那么结果可能是选了两个1000的,(1000 + 1000)/2,结果:1000
0,1000,0,1000,0
-------|-----------|------------|
此时就会出现有的历史峰值存在,有的历史峰值不存在
建议:当你固定好时间区间的start和end,那么每次查询都是一样的
5、每个step如何取data point以及promql.LookbackDelta
-
在每一个时刻点上,使用该时刻点上(如果存在)的采样值
-
如果那个时间点上没有data point,则回溯到过去,使用最先遇到第一个采样值。
-
多个step可能回溯到相同的data point,比如:两个采样就能够跨好几个step(step很小的时候)。此时,就得到很多相同的采样值。
-
step向过去回溯时,最多回溯5min(promql.LookbackDelta = 5 * time.Minute),超过这个时长就不返回采样值啦。
6、step对谁起作用
答案:只对range query起作用。
-
查询instant query时,无需step。instant query求值时就使用一个时刻点。当前时刻点或自定义的时刻点(通过API查询时)。
-
查询range query时,step是有用的。先定出时刻点,然后,对于每一个时刻点,向过去回溯,使用最先遇到第一个采样值。
7、大跨度的时间查询如何保证峰值不丢失
解决方法:
当你进行大跨度的时间查询,比如:查询最近15天的cpu使用率,此时prometheus默认会以比较大的step去查询,那么就有部分峰值信息被遗漏了,此时可以通过手动指定较小的step进行查询,以避免遗漏部分峰值信息
注意点:
较小的step也就意味着较多的结果返回,如何进行处理,和对prometheus较大的查询压力,都是要考虑进去的
最佳实践
当查询一个信息的时候,要综合step,scape_internal,instant vector selector还是range vector selector,time duration,rate duration等因素进行综合考虑。切不可直接摘抄网上的查询语句进行查询,因为不同的业务场景下,区间和采集频率都不同
注意:rate() 函数需要在指定窗口下至少有两个样本才能计算输出。一般来说,比较好的做法是选择范围窗口大小至少是抓取间隔的4倍,这样即使在遇到窗口对齐或抓取故障时也有可以使用的样本进行计算,例如,对于 1 分钟的抓取间隔,你可以使用 4 分钟的 Rate 计算,但是通常将其四舍五入为 5 分钟。所以如果使用 query_range 区间查询,例如在绘图中,那么范围应该至少是步长的大小,否则会丢失一些数据。
