最近在学习netty,里面提到了一个TCP拆包粘包的问题,查阅资料了解到了几种解决的办法,例如
- 使用特殊分隔符
- 定长数据帧以及
- 自定义消息头+消息体,在消息头中定义数据包的长度
关于最后一种实现手段,最典型的代表就是我们常见的HTTP协议。
关于Content-Length
Content-Length是HTTP头部的一个字段,用于表示HTTP的body数据的长度。但是在HTTP 1.0的时候,Content-Length字段可有可无,因为HTTP 1.0的每一个网络请求都是短连接,在发起TCP三次握手后,服务端返回数据,随后四次挥手,这个连接在HTTP请求结束后会立即关闭,浏览器在读到EOF(-1)的时候就可以认为数据传输完毕。下面用一个Java程序验证一下
public class HttpServer01 {
public static void main(String[] args) throws IOException {
ServerSocket ss = new ServerSocket(8888);
System.out.println("http simple server start ...");
while (true) {
final Socket socket = ss.accept();
new Thread(() -> {
try {
String response = "HTTP/1.0 200 OK\r\n" + //头部简单一点,没有Content-Length字段
"\r\n" +
"<h1>Hello world!</h1>"; //返回一段简单的html
socket.getOutputStream().write(response.getBytes());
} catch (IOException ex) {
ex.printStackTrace();
} finally {
try {
socket.close(); //写完数据就立马关闭TCP连接
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
}
}
运行程序,然后用浏览器访问http://localhost:8888,得到结果如下
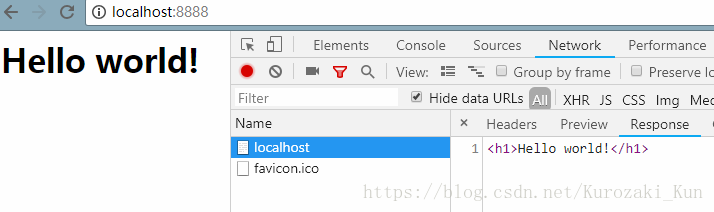
即使没有Content-Length,浏览器也能正确获取到返回的内容,这是因为在TCP连接断开时,浏览器认为服务器已经将数据传输完了。如果要加上Content-Length,后面的值就必须与Body的长度一致,如果过断数据会被截断
将上面的代码的一处做一下小改动
String response = "HTTP/1.0 200 OK\r\n" + //头部简单一点,没有Content-Length字段
"Content-Length: 10\r\n" + //这个长度显然小于下面BODY的长度
"\r\n" +
"<h1>Hello world!</h1>"; //返回一段简单的html然后再次访问,结果如下
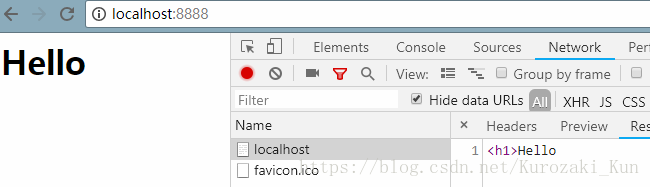
服务器输出的BODY被截断了,只剩下10个字符(hello后面还有个空格),说明Content-Length起到了作用。
如果Content-Length过长似乎还不会出现问题,当然前提是HTTP版本是1.0,可以自己验证一下。
HTTP 1.1的Content-Length
谈到HTTP1.1,不得不先说一个改进——Keep-Alive。使用KeepAlive后,可以达到多个HTTP请求复用一个TCP连接的目的,TCP连接在建立之后,会根据HTTP报文的Connection字段的值来判断是否关闭TCP连接,如果是keep-alive,则保持,如果为close,关闭TCP连接。Keep-Alive还可以单独设置保持连接的最大时长,超过时长自动断开TCP连接。
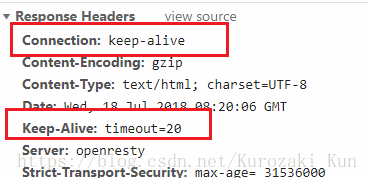
前面已经说过,在HTTP1.0的时候,可以认为连接关闭的时候数据就已经传输完成了,因此不需要Content-Length字段,但是HTTP1.1就变得不一样,需要Content-Length来协助了。
同样,如果Content-Length长度过短,会导致数据截断,如果过长,则会造成浏览器等待,看下面一段代码
public class HttpServer02 {
public static void main(String[] args) throws IOException {
ServerSocket ss = new ServerSocket(8888);
System.out.println("http simple server start ...");
while (true) {
final Socket socket = ss.accept();
new Thread(() -> {
try {
String response = "HTTP/1.1 200 OK\r\n" +
"Connection: keep-alive\r\n" +
"Content-Length: 64\r\n" +
"\r\n" +
"<h1>Hello world!</h1>";
socket.getOutputStream().write(response.getBytes());
} catch (IOException ex) {
ex.printStackTrace();
// 注意,这里变成了发生异常才关闭连接了,没发生异常时连接不会关闭
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
}
}
结果如下
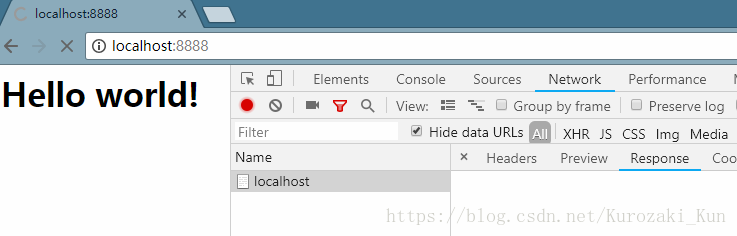
虽然被解析出来了,但是查看body的内容是一直为空的,并且左上角的标签会一直打转,表示“还有数据没传过来”,实际上本次请求的数据已经传输完毕了,这是content-length设置不当导致的。
Chunk编码
Content-Length需要提前知道BODY的长度,对于静态资源是没问题的,但是对于一些动态资源有时候就没有那么方便了。因此HTTP1.1还有一种Chunk编码的方式来传输数据。
使用Chunk编码的BODY会变成下面这样子(假设BODY的数据是“<h1>Hello world</h1>”)
4
<h1>
5
Hello
6
world
5
</h1>
0
也就是说body被切成了一个个小的数据块,因为整个body的长度不好计算,可是取其中一部分还是容易计算的,每个数据块都形如
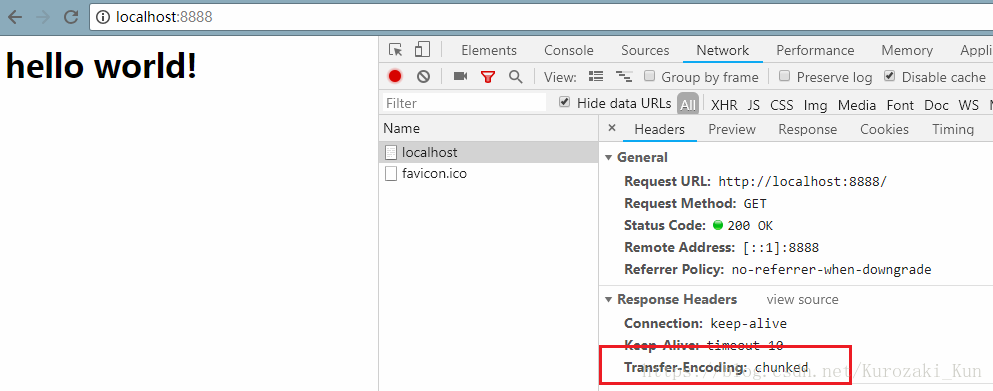
[size]
[data]
这样的格式,最后一个数据块大小为0,代表着本次请求的数据已经传完了。使用chunk编码需要在HTTP头部声明Transfer-Encoding: chunked。
下面用代码验证一下
public class HttpServer03 {
public static void main(String[] args) throws IOException {
ServerSocket ss = new ServerSocket(8888);
System.out.println("http simple server start ...");
while (true) {
final Socket socket = ss.accept();
new Thread(() -> {
try {
String response = "HTTP/1.1 200 OK\r\n" +
"Connection: keep-alive\r\n" +
"Keep-Alive: timeout=10\r\n" +
"Transfer-Encoding: chunked\r\n" + //使用chunk需要在请求头声明
"\r\n" +
"4\r\n" + // size = 4
"<h1>\r\n" +
"5\r\n" + // size = 5
"hello\r\n" +
"6\r\n" +
" world\r\n" +
"6\r\n" +
"!</h1>\r\n" +
"0\r\n" + // size = 0,代表结束
"\r\n";
socket.getOutputStream().write(response.getBytes());
} catch (IOException ex) {
ex.printStackTrace();
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
}
}
运行结果如下
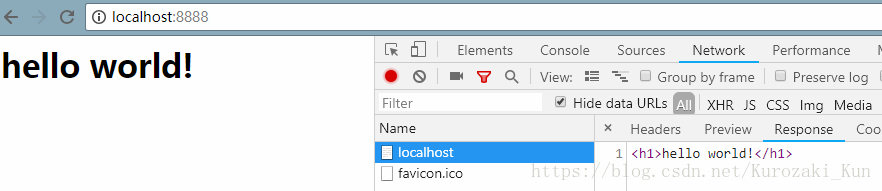
查看Header
注意
- chunk的每个数据块的size一定会与data对应,否则浏览器会解析错误,如Chrome下会报ERR_INVALID_CHUNKED_ENCODING
- 数据块的size用16进制表达
- 最后一个数据块的size为0,下面也会跟着空数据(即 "0\r\n\r\n" )
