1. Cache:缓存区,是高速缓存,是位于CPU和主内存之间的容量较小但速度很快的存储器,因为CPU的速度远远高于主内存的速度,CPU从内存中读取数据需等待很长的时间,而 Cache保存着CPU刚用过的数据或循环使用的部分数据,这时从Cache中读取数据会更快,减少了CPU等待的时间,提高了系统的性能。
Cache并不是缓存文件的,而是缓存块的(块是I/O读写最小的单元);Cache一般会用在I/O请求上,如果多个进程要访问某个文件,可以把此文件读入Cache中,这样下一个进程获取CPU控制权并访问此文件直接从Cache读取,提高系统性能。
2. Buffer:缓冲区,用于存储速度不同步的设备或优先级不同的设备之间传输数据;通过buffer可以减少进程间通信需要等待的时间,当存储速度快的设备与存储速度慢的设备进行通信时,存储慢的数据先把数据存放到buffer,达到一定程度存储快的设备再读取buffer的数据,在此期间存储快的设备CPU可以干其他的事情。
Buffer:一般是用在写入磁盘的,例如:某个进程要求多个字段被读入,当所有要求的字段被读入之前已经读入的字段会先放到buffer中。
假设某地发生了自然灾害(比如地震),居民缺衣少食,于是派救火车去给若干个居民点送水。
救火车到达第一个居民点,开闸放水,老百姓就拿着盆盆罐罐来接水。
假如说救火车在一个居民点停留100分钟放完了水,然后重新储水花半个小时,再开往下一个居民点。这样一个白天来来来回回的,也就是4-5个居民点。
但我们想想,救火车是何等存在,如果把水龙头完全打开,其强大的水压能轻易冲上10层楼以上, 10分钟就可以把水全部放完。但因为居民是拿盆罐接水,100%打开水龙头那就是给人洗澡了,所以只能打开一小部分(比如10%的流量)。但这样就降低了放水的效率(只有原来的10%了),10分钟变100分钟。
那么,我们是否能改进这个放水的过程,让救火车以最高效率放完水、尽快赶往下一个居民点呢?
方法就是:在居民点建蓄水池。
救火车把水放到蓄水池里,因为是以100%的效率放水,10分钟结束然后走人。居民再从蓄水池里一点一点的接水。
我们分析一下这个例子,就可以知道Cache的含义了。
救火车要给居民送水,居民要从救火车接水,就是说居民和救火车之间有交互,有联系。
但救火车是“高速设备”,居民是“低速设备”,低速的居民跟不上高速的救火车,所以救火车被迫降低了放水速度以适应居民。
为了避免这种情况,在救火车和居民之间多了一层“蓄水池(也就是Cache)”,它一方面以100%的高效和救火车打交道,另一方面以10%的低效和居民打交道,这就解放了救火车,让其以最高的效率运行,而不被低速的居民拖后腿,于是救火车只需要在一个居民点停留10分钟就可以了。
所以说,蓄水池是“活雷锋”,把高效留给别人,把低效留给自己。把10分钟留给救火车,把100分钟留给自己。
从以上例子可以看出,所谓Cache,就是“为了弥补高速设备和低速设备之间的矛盾”而设立的一个中间层。因为在现实里经常出现高速设备要和低速设备打交道,结果被低速设备拖后腿的情况。
以PC为例。CPU速度很快,但CPU执行的指令是从内存取出的,计算的结果也要写回内存,但内存的响应速度跟不上CPU。CPU跟内存说:你把某某地址的指令发给我。内存听到了,但因为速度慢,迟迟不见指令返回,这段时间,CPU只能无所事事的等待了。这样一来,再快的CPU也发挥不了效率。
怎么办呢?在CPU和内存之间加一块“蓄水池”,也就是Cache(片上缓存),这个Cache速度比内存快,从Cache取指令不需要等待。
当CPU要读内存的指令的时候先读Cache再读内存,但一开始Cache是空着的,只能从内存取,这时候的确是很慢,CPU需要等待。
但从内存取回的不仅仅是CPU所需要的指令,还有其它的、当前不需要的指令,然后把这些指令存在Cache里备用。
CPU再取指令的时候还是先读Cache,看看里面有没有所需指令,如果碰巧有就直接从Cache取,不用等待即可返回(命中),这就解放了CPU,提高了效率。(当然不会是100%命中,因为Cache的容量比内存小)
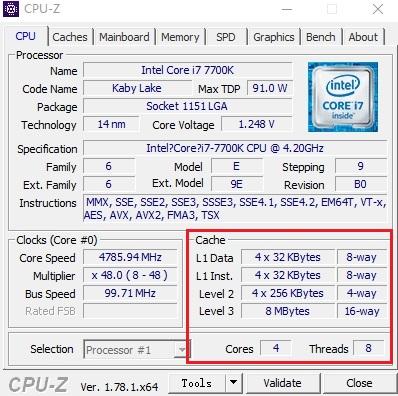
CPU的Cache,可以有好几层,而且还分数据Cache和指令Cache
磁盘缓存也是一样,刚才说内存是慢速设备,所以需要片上缓存,但这个“慢”是相对于CPU而言的,相对于机械硬盘HDD,内存的速度可快多了。对于磁盘的读写操作,在很久以前,读写过程需要CPU参与,后来出现了“DMA/直接内存访问"就不再需要CPU了,但即使如此,高负荷、长时间的磁盘读写也非常的耗时,因为磁盘是机械旋转部件,其读写速度相比CPU和内存条的二进制电压变化速度,那就是蒸汽机和火箭速度的差别。
为了加快数据的读写速度,在磁盘和内存之间也插入一层Cache(Windows在内存里划分出一块区域作为Cache,硬盘也有板载Cache。)
写入数据的时候先写入到Cache里;因为Cache很快,所以数据很快就写入。
比方说,1G的数据,如果直接写入硬盘需要10秒,但写入Cache(也就是系统内存)只需要1秒。
这样一来用户就有了系统速度很快的“幻觉”。但这只是障眼法,数据暂存在Cache里并没有被真正写入磁盘,等系统空闲的时候再慢慢写入。
同理,在读数据的时候,除了所需的数据,还有一堆目前不需要的数据也都被读出来放到内存的Cache里。下次再读的时候,如果恰巧Cache里有所需的数据就可直接读入(命中),这就避免了从慢速的HDD读数据的尴尬。用户的体验同样也是速度很快。(同样不会100%命中,因为RAM的容量远小于硬盘容量)
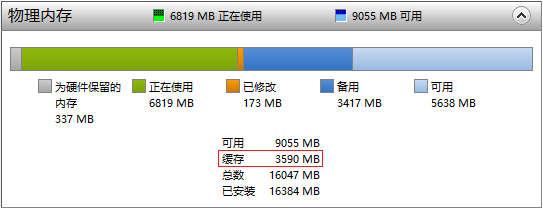
PC有16G的内存,磁盘Cahce占用了3.59G,这是动态的,会自动调整大小

硬盘也内置了Cache。某品牌硬盘的广告强调了大缓存的优势
以上举了3个栗子:蓄水池、CPU的Cache、磁盘的Cache
Cache的存在是为了解决什么问题?速度太慢了,要加快速度!
那么buffer呢? 请允许我再次举起栗子。
比如说吐鲁番的葡萄熟了,要用大卡车装葡萄运出去卖
果园的姑娘采摘葡萄,当然不是前手把葡萄摘下来,后手就放到卡车上,而是需要一个中间过程“箩筐”:摘葡萄→放到箩筐里→把箩筐里的葡萄倒入卡车。
也就是说,虽然最终目的是“把葡萄倒入卡车”,但中间必须要经过“箩筐”的转手,这里的箩筐就是Buffer。是“暂时存放物品的空间”。
注意2个关键词:暂时,空间
再换句话说,为了完成最终目标:把葡萄放入卡车的空间,需要暂时把葡萄放入箩筐的空间。
以BT为例,BT下载需要长时间的挂机,电脑就有可能24小时连轴转,但BT下载的数据是碎片化的,体现在硬盘写入上也是碎片化的,因为硬盘是机械寻址器件,这种碎片化的写入会造成硬盘长时间高负荷的机械运动,造成硬盘过早老化损坏,当年有大量的硬盘因为BT下载而损坏。
于是新出的BT软件在内存里开辟了Buffer,数据暂时写入Buffer,攒到一定的大小(比如512M)再一次性写入硬盘,这种“化零为整”的写入方式大大降低了硬盘的负荷。
这就是:为了完成最终目标:把数据写入硬盘空间,需要暂时写入Buffer的空间。
再以编程为例,假设要实现一个功能:接受用户键入的字符串,并赋值给一个字符串变量
其过程如下:
1:在内存中开辟一个”键盘缓冲区“接受用户键入的字符串
2:把缓冲区中的字符串copy到程序中定义的字符串变量指向的内存空间(也就是赋值过程)
也就是说,为了完成最终目标:把字符串放入字符串变量指向的空间,需要暂时把字符串放入“键盘缓冲区”的空间。
以上举的3个栗子:箩筐、BT的Buffer,键盘缓冲区的Buffer
Buffer的存在是为了解决什么问题?找个临时的存储空间!
Cache和Buffer的相同点:都是2个层面之间的中间层,都是内存。
Cache和Buffer的不同点:Cache解决的是时间问题,Buffer解决的是空间问题。
为了提高速度,引入了Cache这个中间层。
为了给信息找到一个暂存空间,引入了Buffer这个中间层。
为了解决2个不同维度的问题(时间、空间),恰巧取了同一种解决方法:加入一个中间层,先把数据写到中间层上,然后再写入目标。
这个中间层就是内存“RAM”,既然是存储器就有2个参数:写入的速度有多块(速度),能装多少东西(容量)
Cache利用的是RAM提供的高读写速度,Buffer利用的是RAM提供的存储容量(空间)。
2、Cache(缓存)则是系统两端处理速度不匹配时的一种折衷策略。因为CPU和memory之间的速度差异越来越大,所以人们充分利用数据的局部性(locality)特征,通过使用存储系统分级(memory hierarchy)的策略来减小这种差异带来的影响。
3、假定以后存储器访问变得跟CPU做计算一样快,cache就可以消失,但是buffer依然存在。比如从网络上下载东西,瞬时速率可能会有较大变化,但从长期来看却是稳定的,这样就能通过引入一个buffer使得OS接收数据的速率更稳定,进一步减少对磁盘的伤害。
4、TLB(Translation Lookaside Buffer,翻译后备缓冲器)名字起错了,其实它是一个cache.
监控linux资源时,在输入top命令后,发现内存相关MEM和SWAP的buffer与Cache,顺便研究了一下。
什么是Cache?什么是Buffer?二者的区别是什么?
Buffer和Cache的区别 buffer与cache操作的对象就不一样。
1、buffer(缓冲)是为了提高内存和硬盘(或其他I/O设备)之间的数据交换的速度而设计的。
2、cache(缓存)
从CPU角度考虑,是为了提高cpu和内存之间的数据交换速度而设计的,例如平常见到的一级缓存、二级缓存、三级缓存。 cpu在执行程序所用的指令和读数据都是针对内存的,也就是从内存中取得的。由于内存读写速度慢,为了提高cpu和内存之间数据交换的速度,在cpu和内存之间增加了cache,它的速度比内存快,但是造价高,又由于在cpu内不能集成太多集成电路,所以一般cache比较小,以后intel等公司为了进一步提高速度,又增加了二级cache,甚至三级cache,它是根据程序的局部性原理而设计的,就是cpu执行的指令和访问的数据往往在集中的某一块,所以把这块内容放入cache后,cpu就不用在访问内存了,这就提高了访问速度。当然若cache中没有cpu所需要的内容,还是要访问内存的。
从内存读取与磁盘读取角度考虑,cache可以理解为操作系统为了更高的读取效率,更多的使用内存来缓存可能被再次访问的数据。
缓冲(buffers)是根据磁盘的读写设计的,把分散的写操作集中进行,减少磁盘碎片和硬盘的反复寻道,从而提高系统性能。linux有一个守护进程定期清空缓冲内容(即写入磁盘),也可以通过sync命令手动清空缓冲。
简单来说,buffer是即将要被写入磁盘的,而cache是被从磁盘中读出来的。 buffer是由各种进程分配的,被用在如输入队列等方面。一个简单的例子如某个进程要求有多个字段读入,在所有字段被读入完整之前,进程把先前读入的字段放在buffer中保存。
cache经常被用在磁盘的I/O请求上,如果有多个进程都要访问某个文件,于是该文件便被做成cache以方便下次被访问,这样可提高系统性能。
