目录
1、名词
CEP(Complex Event Processing):复杂事件处理、复合事件处理
EPL(Event Processing Language):SQL-LIKE的事件处理语言,用于描述CEP任务
2、CEP引擎
离线引擎
待补充。
实时引擎
Esper:
优点:更新活跃,轻量级嵌入式引擎,规则验证方便,本地导入包后,即可运行。官方提供的文档和case study很全面,支持标准SQL语法,唯一编译型CEP引擎,吞吐量很大单机600W/S。
缺点:分布式需要自己实现,EPL编写没有专门的IDE。
Fink CEP:
优点:分布式部署。
缺点:规则验证不方便,需要上线后才可验证,据说有性能问题。
Siddhi:
优点:轻量级,有web接口,语法编写有错误提示。
缺点:据说句法使用上不够灵活,功能支持不如Esper多,官方文档描述不够详细。
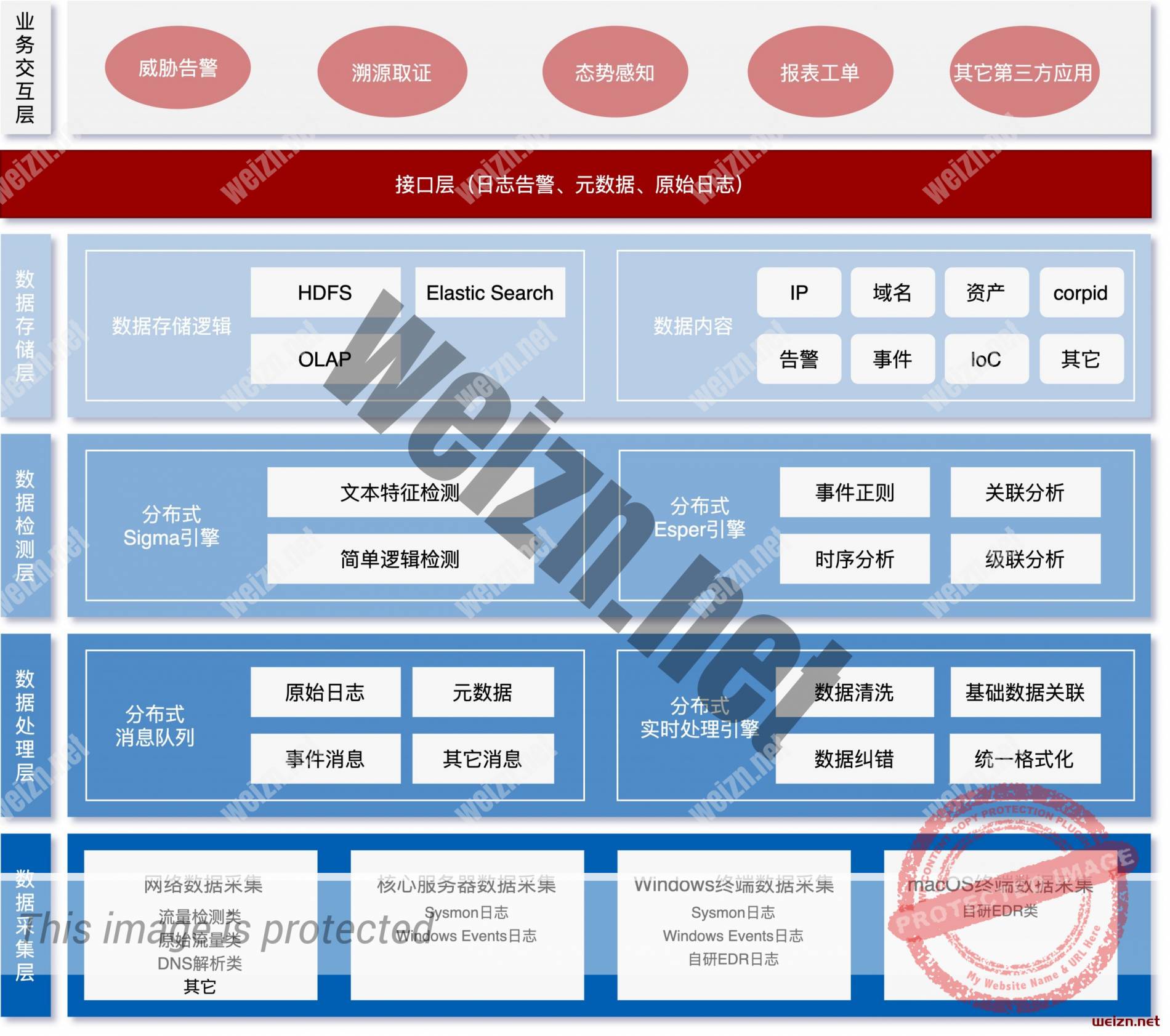
3、逻辑架构图
4、数据流图
选择采用Storm + Esper模式提供CEP能力,Storm拓扑中的大致数据流图如下:
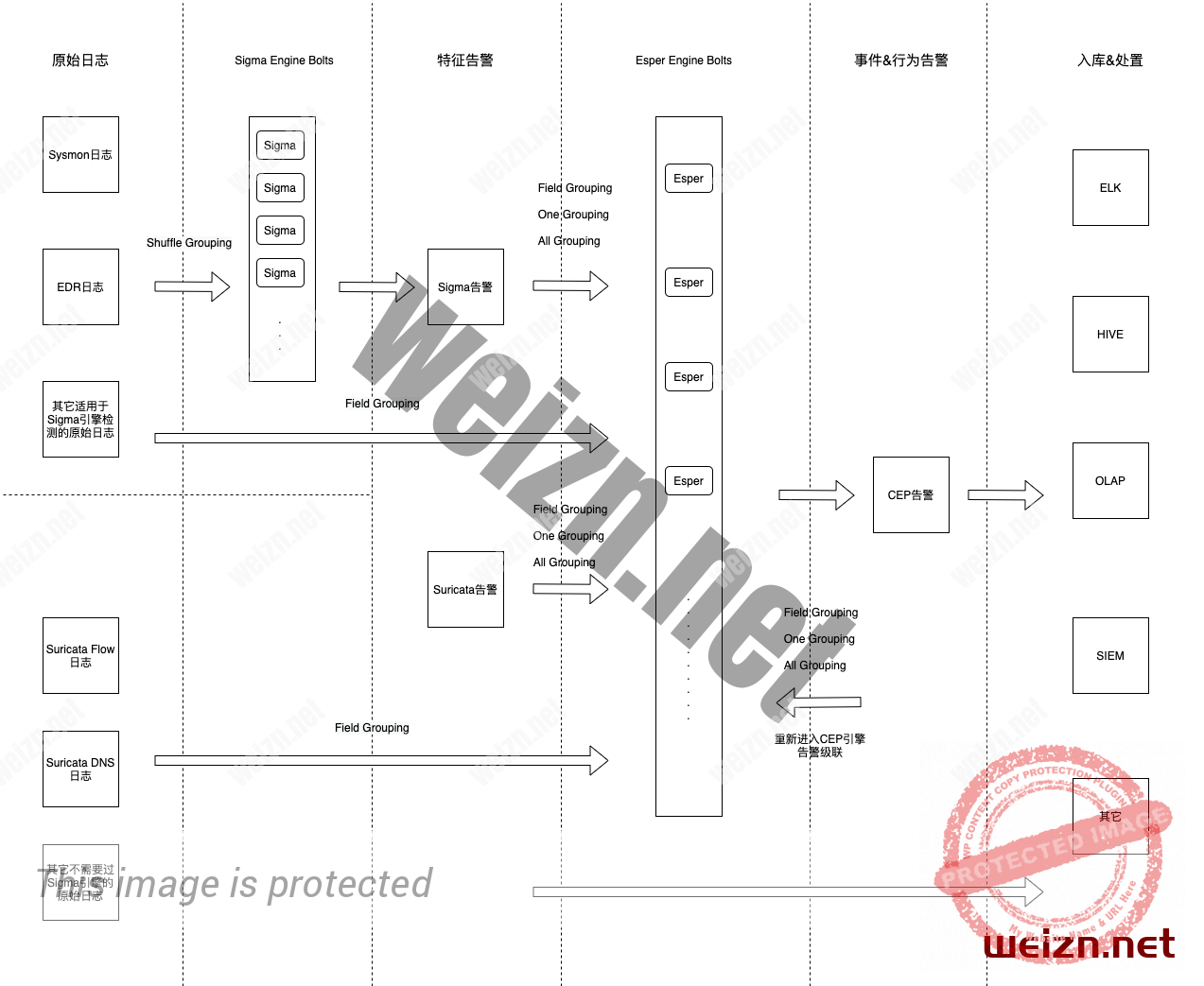
5、关于Storm中的数据分组
在Storm中,假如将嵌入了Esper引擎的bolt设置为500并发,以此来增大数据处理效率,而在Storm底层,实际是启动了500个Java虚拟机,每个虚拟机跑一个搭载了Esper引擎的bolt,这样就出现了一个问题,不同Esper引擎之间的数据是隔离的,上游的数据在传递给Esper Bolts的时候,会分散到不同的Esper引擎中,例如A日志给了A引擎,B数据给了B引擎,那么就无法将A和B进行关联分析,基于这样的问题,必须合理的规划分组方式,将需要关联分析的数据,全部发送给同一个bolt。
这里的Esper Bolts接收到了5种类型的日志,分别是:
a.终端EDR相关的原始日志
b.Suricata相关的原始日志
c.Sigma告警
d.Suricata告警
e.Esper引擎自己产生的CEP告警(CEP告警重入Esper引擎是为了方便告警级联分析)
a、b作为原始日志采用默认分组方式『field grouping』,例如suricata的tcp flow日志可以选择使用src_ip字段作为grouping,sysmon日志可以选择computer_name字段作为grouping。但这依然不能满足一些检测场景,例如需要聚合dest_ip字段,因为同一个dest_ip可能被分到了不同的Esper引擎,所以聚合的结果一定是不准确的,解决方案后文介绍。
b、c、d、e作为告警日志,采用了三种不同的分组方式:
Field Grouping:提取当前告警中指定的字段值,作为grouping条件。
One Grouping:将所有one grouping的告警都发送到同一个Esper引擎中。
All Grouping:将告警发送给每一个Esper引擎。
由于每个告警都需要对应的规则,那么在规则定义阶段,也可以指定好告警产生时的grouping方式,例如在一个Sigma规则中,可以如下定义:
# 告警产生后,在Esper引擎中的分组方式,不加此字段则会同时进行2种默认分组方式:
# 1、通过computer_name字段进行field grouping
# 2、one grouping方式,把所有告警发送到同一个bolt中,如果log_level为0则默认不进行one grouping
# 自定义分组方式:
# 1、all_grouping,当前告警发送给每一个bolt节点
# 2、one_grouping,当前告警发送给同一个节点
# 3、define_one_grouping,用户自定义one_grouping字段,后接一个随机HASH值,例如:『define_one_grouping:12345』
# 4、{field_name},直接填写告警中的字段名,则会提取这个字段值作为grouping id
# 示例:
# storm_grouping_field:
# - 'event_data.IpAddress' # 通过告警日志中的event_data.IpAddress字段来分组
# - 'one_grouping' # 通过one_grouping方式分组
# - 'all_grouping' # 通过all_grouping方式分组
# - 'define_one_grouping:12345' # 通过one_grouping方式分组,但是自定义分组ID为12345,
# # 相同的ID会分组到同一个bolt,不同的ID可能会分组到不同的bolt
storm_grouping_field:
- 'event_data.IpAddress'
- 'one_grouping'
这里使用了两种分组方式,『field grouping』和『one grouping』,也就是说告警进入Esper引擎时,不但会以『event_data.IpAddress』字段的值分组,还会以『one grouping』方式分组。
而对于Suricata告警,由于Snort不方便做如此详细的规则定义方式,所以需要额外的维护一个告警映射表,例如当Suricata告警产生后,给它添加一些附加信息,告警描述,威胁等级,引用链接,告警分类,标签等等,当然还有grouping方式,一个精简的示例模板如下:
# 匹配Suricata的规则名,支持模糊匹配算法
signature: 'SCWX * Privilege Escalation Attempt *CVE-2020-1472*'
# 告警描述
description: '源主机尝试探测了目标主机是否存在CVE-2020-1472(ZeroLogon)漏洞。'
# 一级分类
category_1: 漏洞利用
#二级分类
category_2: CVE漏洞
# 相关参考链接
references:
- https://cert.360.cn/warning/detail?id=ead0801e639052498d4bf396e08ef775
- https://www.freebuf.com/articles/system/249860.html
# 告警标签
tags:
- ZeroLogon
# 当前mapping的匹配优先级,如果同一个告警命中了多个mapping,优先使用precedence高的mapping,无此字段默认为0
precedence: 100
# 告警产生后,在Esper引擎中的分组方式,不加此字段则会同时进行2种默认分组方式:
# 1、通过attacker_ip字段进行field grouping
# 2、one grouping方式,把所有告警发送到同一个bolt中,如果log_level为0则默认不进行one grouping
# 自定义分组方式:
# 1、all_grouping,当前告警发送给每一个bolt节点
# 2、one_grouping,当前告警发送给同一个节点
# 3、define_one_grouping,用户自定义one_grouping字段,后接一个随机HASH值,例如:『define_one_grouping:12345』
# 4、{field_name},直接填写告警中的字段名,则会提取这个字段值作为grouping id
# 示例:
# storm_grouping_field:
# - 'http.hostname' # 通过告警日志中的http.hostname字段来分组
# - 'one_grouping' # 通过one_grouping方式分组
# - 'all_grouping' # 通过all_grouping方式分组
# - 'define_one_grouping:12345' # 通过one_grouping方式分组,但是自定义分组ID为12345,
# # 相同的ID会分组到同一个bolt,不同的ID可能会分组到不同的bolt
storm_grouping_field:
- 'attacker_ip'
已知了各种告警的分组方式,就可以选择合适的字段和分组方法,让多个需要关联的日志,发送到同一个Esper中。但假如非要指定原始日志的grouping方式,也可以使用变通的方式,先通过规则将需要关注的原始日志筛选出来,然后设置告警为内联告警,内联告警仅仅用于系统内部级联分析,不会入库和发出:
# 规则产生的告警日志等级,可为,0:系统内部级联告警,不输出,1:一级告警(普通告警),2:二级告警(运营告警),3:三级告警(应急告警)。 log_level: 3
然后再到Esper中写规则和分析这些被筛选出的日志即可。
6、实时Sigma引擎
Sigma规则基于yaml语言编写,学习成本很低,十分适用于基于文本特征和简单逻辑判断的日志检测场景,可以用它去做易于提取到强特征的攻击检测,也可以用它初筛原始日志后,做内部级联检测。
详情可看Wiki介绍:https://github.com/Neo23x0/sigma
但作者发布的Sigma引擎是用Python编写,基于ES,Splunk等平台离线计算检测原始日志,而且仅支持模糊匹配算法,不支持正则,这样存在两个问题:
1)离线计算实时性不高,不能达到微秒级检测,而且可能存在大量重复计算,比较浪费资源,再加上ES适用场景为小数据集,如果在海量数据面前,会存在性能以及稳定性的问题。例如TPS在50w以上,原始Sigma引擎这种离线计算的模式更是难以稳定和快速的完成检测。
2)模糊匹配算法在实际使用过程中,优点是易于理解和编写,缺点是不容易精细化的匹配特征,容易造成误报的情况。
基于以上问题,需要按照原始的Sigma规则逻辑,用Java重写整个引擎,使其可以运行在Storm中,并且增加支持正则的功能。
7、Esper规则模板
一个Esper规则由两部分构成:
1)用于描述检测逻辑的EPL语句。
2)用于处理通过EPL语句筛选出日志的Listener。
由于每个规则通过EPL筛选出来的日志可能不一样,所以Listener也不能有相同的处理流程,而在官方给出的Case Study中,Listener则全部由Java代码编写,虽然满足了灵活处理日志的能力,但在实践中却有诸多无法忍受的缺陷:
1)规则开发时间长,毕竟写代码本身就麻烦,后续还有经过线下规则验证,线上规则验证,不断调试代码,修改检测特征,总体下来耗时很长,规则无法快速添加和更新。
2)规则编写门槛较高,非Java开发人员无法参与规则编写。
3)规则不支持热更新,每一次规则的上线和更新,都需要重启线上Storm拓扑,导致监控中断,甚至在重启过程中可能导致日志丢失。
解决方法是将Esper编写规则的方式模板化,通过配置文件的方式来描述Esper规则,并且通过Java的反射机制来控制Listener的处理流程,可以继续使用YAML来定义整个Esper规则,以下简单描述Esper规则模板的关键构成。
首先定义EPL查询语句:
# EPL语句,多条EPL语句需要『;』符号分隔,并且两个换行符。
epl: '
@name("可疑进程通过1个单向匿名管道执行CMD命令_无周期性心跳_Sysmon_查询同时有两个行为的进程")
select * from pattern [
every-distinct(
a.computer_name, a.event_data_sourceip, a.event_data_destinationip, a.event_data_destinationport,
a.event_data_image, 8 hour
)
a=SysmonRawLogs(
event_id = "3"
and event_data_direction = "outbound"
and IPAddress4Utils.is_valid_ipv4(event_data_sourceip)
and IPAddress4Utils.is_valid_ipv4(event_data_destinationip)
and not StringUtils.wildcard_match(event_data_image, "*\\google\\*")
and not StringUtils.wildcard_match(event_data_image, "*\\inetsrv\\w3wp.exe")
and not StringUtils.wildcard_match(event_data_image, "*\\system32\\dns.exe")
and not StringUtils.wildcard_match(event_data_image, "*\\system32\\svchost.exe")
) ->
b=ComplexAttackAlerts(
rule_name = "通过绑定1个单向匿名管道执行CMD命令_Sysmon" and
a.computer_name = host_computer_name and
a.event_data_image = host_parent_images and
a.event_data_processguid = host_parent_guid and
a.event_data_processid = host_parent_pid
) where timer:within(8 hour)
];
'
# 需要添加回调函数的EPL语句索引编号,不加这个字段表示不添加回调函数,例如仅仅创建全局窗口的规则,就不需要加此字段
# 如果为多个语句添加回调函数,则写成数组形式,例如:
# listener_epl_index:
# - 0
# - 1
# - 3
listener_epl_index: 0
然后定义Listener的处理流程,可以先定义将会用到的局部常量和数据类型:
# 设置局部常量
# 表达式为『常量名: '数据类型:常量值'』
# 支持的基本数据类型有:
# String:字符串类型,不填数据类型则默认为String类型,例如:string_const: 'aaaaa'
# Integer:整数类型
# int:等同Integer
# Long:长整数类型
# long: 等同Long
# Boolean:布尔类型
# boolean:等同Boolean
# Float:浮点小数类型
# float:等同Float
# Double:双精度浮点小数类型
# double:等同Double
#
# 如果创建数组,则通过以下方式表达
# 字符串数组String[]的表达形式,只需要第一个元素申明基本类型即可:
# string_list:
# - 'String:aaaa'
# - 'bbbbb'
# - 'ccccc'
# 整数数组Integer[]的表达形式:
# integer_list:
# - 'int:111'
# - '222'
# - '333'
#
# 如果需要创建一个null常量,先申明数据类型,再通过『$null』关键字赋值为null,例如:
# string_null: 'String:$null'
# long_null: 'Long:$null'
local_constant:
total_alert_count: 'int:1'
end_unix_timestamp: 'Long:0'
splitRegex: 'String:,'
aboveDeep: 'int:30'
belowDeep: 'int:10'
procDeep: 'int:30'
event_id:
- 'String:1'
- '10'
- '17'
- '18'
- '3'
提取EPL返回的行:
# 提取EPL的返回值为局部变量
# 表达式为『变量名: '数据类型:EPL返回值中的字段名'』
# 数据类型一致
local_variable:
start_unix_timestamp: 'Long:a.unix_timestamp'
dest_ip: 'String:a.event_data_destinationip'
dest_port: 'int:a.event_data_destinationport'
proto: 'String:a.event_data_protocol'
computer_name: 'String:a.computer_name'
host_ip: 'String:a.host_ip'
user: 'String:b.host_users'
parentImage: 'String:b.host_parent_images'
parentCommand: 'String:b.host_parent_commandline'
parentGuid: 'String:b.host_parent_guid'
parentPid: 'String:b.host_parent_pid'
image: 'String:b.host_images'
command: 'String:b.host_commandline'
guid: 'String:b.host_guid'
pid: 'String:b.host_pid'
sysmonLogIdStr: 'String:b.sysmon_log_id'
如果需要调用一些方法来完成即席查询任务,只需提前写好UDF然后调用即可:
# 动态调用Java代码中EsperQueryUtils()类中的函数
# 表达式为『返回值的变量名: '数据类型:函数名(参数1, 参数2, 参数3, ......)'』
# 函数传参可以调用局部常量和局部变量,需要在局部变量/常量名前面加上『$』符号,如果不加『$』符号则表示传入当前字符串。
local_variable_invoke_function:
sysmonLogIdList: 'String[]:split($sysmonLogIdStr, $splitRegex)'
commandContextList: 'String[]:query_win_context_command_sysmon($computer_name, $pid, $parentGuid,
$parentPid, $parentImage, $start_unix_timestamp, $aboveDeep, $belowDeep, $command)'
processChainList: 'String[]:query_win_process_chain_sysmon($computer_name, $parentCommand, $parentImage,
$parentGuid, $parentPid, $command, $image, $guid, $pid, $procDeep)'
最后,将前面准备好的局部变量,填充到CEP告警模板中,生成一个完整的CEP告警:
# 动态调用Java代码中告警模板ComplexAttackAlert()类中的函数,向模板中添加告警信息字段
# 表达式为『函数名: '局部变量/常量名'』
# 如果对同一个函数进行多次调用传入不同的参数,则需要写成数组形式,例如:
# add_sysmon_log_id:
# - '$aid'
# - '$bid'
# - '$cid'
create_alert_invoke_function:
add_host_computer_name: '$computer_name'
add_host_user: '$user'
add_host_ip: '$host_ip'
add_total_alert_count: '$total_alert_count'
add_host_image: '$image'
add_host_guid: '$guid'
add_host_pid: '$pid'
add_host_commandline: '$command'
add_host_parent_image: '$parentImage'
add_host_parent_commandline: '$parentCommand'
add_host_parent_guid: '$parentGuid'
add_host_parent_pid: '$parentPid'
add_dest_ip: '$dest_ip'
add_dest_port: '$dest_port'
add_attacker_ip: '$dest_ip'
add_attacker_port: '$dest_port'
add_sysmon_log_id: '$sysmonLogIdList'
add_host_command_context: '$commandContextList'
add_host_process_chain: '$processChainList'
add_host_event_id: '$event_id'
8、Case Study
9、结尾
结尾有点仓促,很多东西没有交代,也是长时间不写博客了写到最后脑子疼,最后欢迎一起交流其它的CEP方案。

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~