
看完记得点个关注呦~,了解更多职场及大数据,人工智能,java等技术文章。
在了解slot、task、并行度相关概念和原理之前先看一下企业中与之相关的高频面试题
1.Flink的并行度了解吗?Flink的并行度设置是怎样的?
2.任务并行度与slot之间的关系?
3.Flink并行度设置优先级?
4.并行的任务,需要占用多少slot?
5. slot并行的条件?
6. taskmanager与slot之间的关系?
7.什么是slot共享,slot共享的好处?
8.一个流处理程序,到底包含多少个任务?
接下来的介绍相信你会对这些问题有一个答案,当然文章最后也有对应的参考答案
taskmanager:Flink中每一个worker(TaskManager)都是一个JVM进程,它可能会在独立的线程上执行一个Task。为了控制一个worker能接收多少个task,worker通过Task Slot来进行控制(一个worker至少有一个Task Slot)。
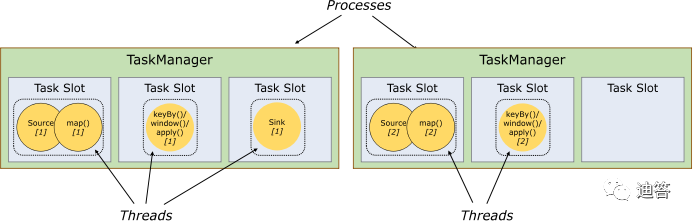
slot:每个task slot表示TaskManager拥有资源的一个固定大小的子集。假如一个TaskManager有三个slot,那么它会将其管理的内存分成三份给各个slot。资源slot化意味着一个task将不需要跟来自其他job的task竞争被管理的内存,取而代之的是它将拥有一定数量的内存储备。
需要注意的是,这里不会涉及到CPU的隔离,slot目前仅仅用来隔离task的受管理的内存
并行度:特定算子的子任务(subtask)的个数称之为并行度(parallel),一般情况下,一个数据流的并行度可以认为是其所有算子中最大的并行度。
一个程序中,不同的算子可能具有不同的并行度。
并行度设置四种方式:
直接在代码中对某一个算子指定并行度。
2.在代码环境中指定并行度。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);
3.在配置文件中指定任务并行度。
4.提交任务时候通过参数指定并行度。
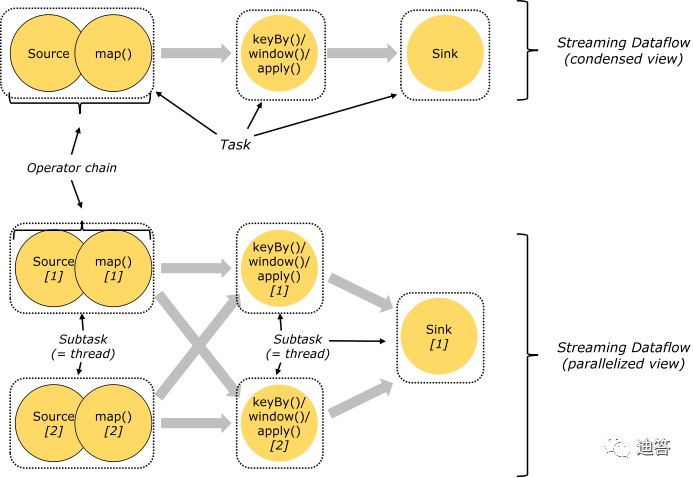
Task与SubTask:
一个算子就是一个Task. 一个算子的并行度是几, 这个Task就有几个SubTask
Operator Chains(任务链)
相同并行度的one to one操作,Flink将这样相连的算子链接在一起形成一个task,原来的算子成为里面的一部分。每个task被一个线程执行.
将算子链接成task是非常有效的优化:它能减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。链接的行为可以在编程API中进行指定。
每个 TaskManager 至少有一个 slot,这意味着每个 task 组都在单独的 JVM 中运行(例如,可以在单独的容器中启动)。具有多个 slot 意味着更多 subtask 共享同一 JVM。同一 JVM 中的 task 共享 TCP 连接(通过多路复用)和心跳信息。它们还可以共享数据集和数据结构,从而减少了每个 task 的开销。
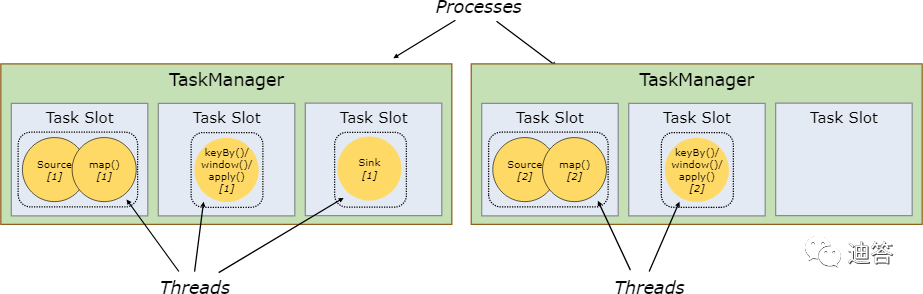
上边例子,从图中可以看出来5个subtask应该需要5个task slot来执行,事实是这样的吗?
不是的,默认情况下,上边例子只需要2个slot就可以了。
我们再看另外一个例子,当我们把并行度调大为6:
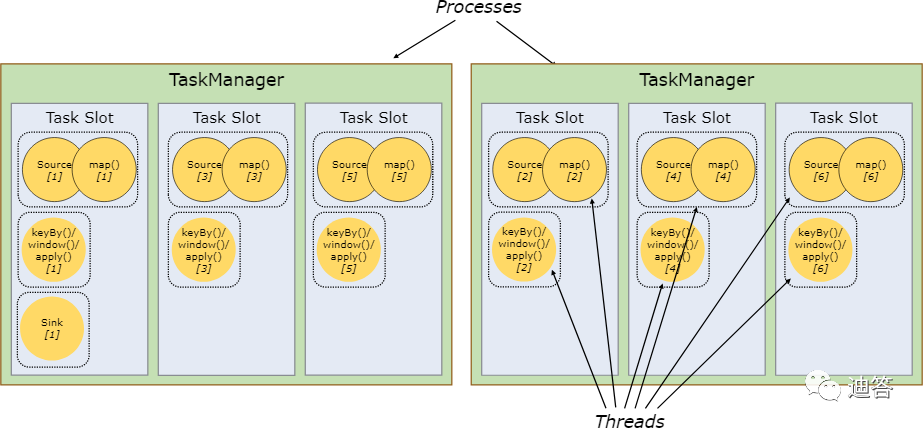
按照并行度拆开这个任务(task),我们发现会有13个subtask,那么是不是就意味着需要13个slot才能执行该任务呢?
答案是否定的,实际是只需要6个slot就够了。
这个出现的原因就要看两条规则:
默认情况下,Flink 允许子任务共享slot,即使他们是不同任务的子任务。这样的结果就是一个slot可以保存作业的整个pipeline。
Task slot 是静态的概念,指的是TaskManager具有的并发执行能力。
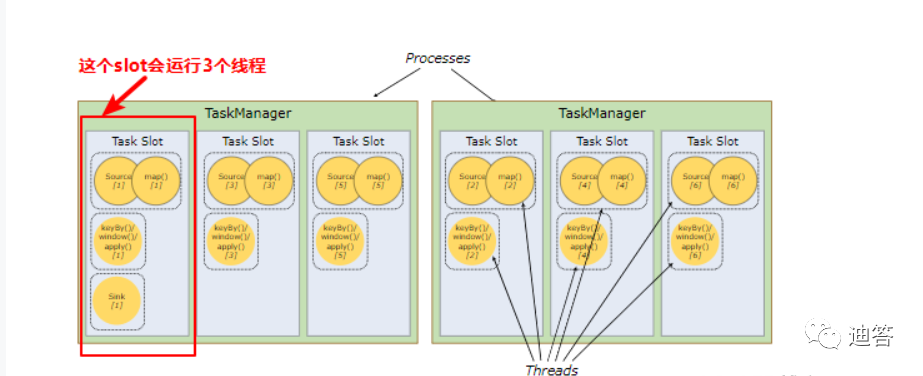
从图中可以看出来,第一个slot会运行3个subtask,也就是执行3个线程,前面提到slot只是做了内存隔离,并没有做CPU隔离,假设这样一种情况,我们的服务器是6核CPU的,也就是意味着每个slot就可以分到一个CPU资源,那么就意味着这3个子任务中,一个子任务执行时就有2个子任务在等待状态,所以我们在设置slot个数时,也要考虑一下集群的资源,尽量使得每个slot能使用得到合理的CPU资源。
如果不想实现slot共享,那么可以在代码中禁用算子链来实现。
//相同的插槽组有可能共享插槽。val kafkaStraem: DataStream[String] = env.addSource(consumer).slotSharingGroup("1")// 表示该算子不参与任务链的合并。kafkaStraem.flatMap(_.split(" ")).disableChaining()// 全局禁用operator chainsenv val env: StreamExecutionEnvironment =StreamExecutionEnvironment.getExecutionEnvironment;env.disableOperatorChaining()
Flink中slot是任务执行所申请资源的最小单元,同一个TaskManager上的所有slot都只是做了内存分离,没有做CPU隔离。
每一个TaskManager都是一个JVM进程,如果某个TaskManager 上只有一个 slot,这意味着每个 task 组都在单独的 JVM 中运行,如果有多个 slot 就意味着更多 subtask 共享同一 JVM。
一般情况下有多少个subtask,就是有多少个并行线程,而并行执行的subtask要发布到不同的slot中去执行。
Flink 默认会将能链接的算子尽可能地进行链接,也就是算子链,flink 会将同一个算子链分组内的subtask都发到同一个slot去执行,也就是说一个slot可能要执行多个subtask,即多个线程。
flink 可以根据需要手动地将各个算子隔离到不同的 slot 中。
一个任务所用的总共slot为所有资源隔离组所占用的slot之和,同一个资源隔离组内,按照算子的最大并行度来分配slot。
简单来说就是每个taskmanager至少需要有一个slot,一个算子就是一个task,算子具有的并行度就有几个subtask,而这几个subtask就需要相同数量的slot,slot本身可以实现共享,不同的算子的子任务在相同的共享组可以实现共享同一个slot,提高资源利用率,前提需要是同一个job。
Flink中的任务被分为多个并行任务来执行,其中每个并行的实例处理一部分数据。这些并行实例的数量被称为并行度。
我们在实际生产环境中可以从四个不同层面设置并行度:
操作算子层面(Operator Level)
执行环境层面(Execution Environment Level)
客户端层面(Client Level)
系统层面(System Level)
需要注意的优先级:算子层面>环境层面>客户端层面>系统层面。
2.Slots(槽位):就是分配好的一组资源,即分配资源的最小单位,然后在资源上执行任务,运行时一个任务就必须分配到一个slots上执行,占用一组特定的资源。默认一个taskmanager上开启一个slots。
任务并行度,是指一个flink任务提交后在整个集群的并行度。
numberOfTaskSlots与当前运行的job没有关系,他是taskmanager本身资源分配的静态属性,就是资源到底有几个。所以任务的运行与否与numberOfTaskSlots没有关系,而是与并行度有关系。
3.参考答案一
4.并行任务的每一个子任务都需要占用一个slot。但是流处理需要的slot个数,一个流程序的并行度,可以认为就是其所有算子中最大的并行度。
5.slot是否真正的并行得看taskManager分配的cpu核心,同一个taskmanager的slot可以独享内存,但是只能共享CPU,如果2个slot共用一个cpu线程,那么并不是真正的并行。只有一个slot独享一个cpu线程才是真正的并行。所以我们在设置slot个数时,也要考虑一下集群的资源,尽量使得每个slot能使用得到合理的CPU资源。
6.可以认为每一个taskmanager就是一个JVM进程,而里面执行的每一个任务可以认为是一个独立的线程,为了保障线程之间不互相影响,就给每个线程一个独立的内存空间,线程所占用的资源就叫做slot。因此,slot数量就是内存划分的数量,决定了一个taskmanager可以并行执行几个task,通过slot的数量可以控制taskmanager并行处理的能力。总之,一个taskmanager上的多个slot共享一个JVM,共享CPU,但是有独立的内存。
7.Slot共享:对于每一个数据而言,他的任务的先后顺序是无法改变的,不可能并行处理。不同数据之间具有时间顺序,并行度指的是不同数据,不同的数据可以并行分配到不同的slot中。同一个数据同一个时间只能执行一个任务。所以可以允许将前后发生的不同任务放到一个slot中,也就是需要不同的子任务共享slot。
好处:默认的共享组是default,共享组的优点资源利用率高,默认条件下是使用共享组的,除了有特殊需求。
1)保存整个作业管道:对于先后发生的任务,可以共享slot,一个数据执行完后可以执行下一步操作,这样一个slot就可以保存作业的整个管道,即保存了处理流程的每一步操作,所有的操作可以在同一个slot中完成。
2)可靠性:由于一个slot保存了整个处理流程,即便别的taskmanager的slot挂掉之后,也不会影响整个数据处理。
3)防止数据积压:不同的任务有不同的复杂程度,不同的算子可以对CPU资源的占用情况不同,比如window就是资源密集型的算子,而像source、map这样的操作对于CPU来说可能就是一瞬间。如果不同的算子分布到不同的slot,就有可能出现像source、map不停的读取数据,而window进行大量计算占用CPU资源,出现忙的忙死,闲的闲死,出现数据堆积产生背压。为了避免这种情况,让资源更加平均的分布开,就需要让忙闲做个搭配,CPU占用比较高的任务和CPU占用比较低的任务放在一起共享slot,当map处理完后可以先不着急读取新的数据,可以接下处理window,这样资源的利用率就会更高,也不会出现数据积压。
8.经过任务链合并后的子任务数,子任务数由每个算子的并行度决定。

扫码关注
有趣的灵魂在等你


