Linked大佬Jay Kreps曾发表过一篇博客,简单阐述了他对数据仓库架构设计的一些想法。从Lambda架构的缺点到提出基于实时数据流的Kappa架构。本文将在Kappa架构基础上,进一步谈数仓架构设计。
什么是Lambda架构?
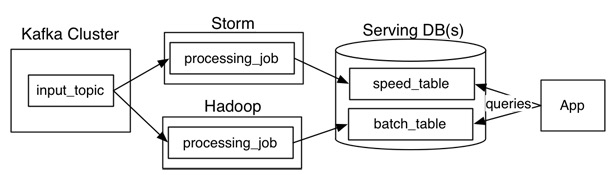
借用Jay Kreps的一张图来看,Lambda架构主要由这几部分构成:数据源(Kafka),数据处理(Storm,Hadoop),服务数据库(Serving DB)。其中数据源和服务数据库是整个架构数据的入口和出口。数据处理则是分为在在线处理和离线处理两部分。
当数据通过kafka消息中间件,进入Lambda架构后,会同时进入离线处理(Hadoop)和实时处理(Storm)两个处理模块。离线处理进行批计算,将大量T+1的数据进行汇总。而实时处理则是进行流处理或者是微批处理,计算秒级、分钟级的结果。最后都录入到服务数据库(Serving DB)中进行汇总,暴露给上层服务调用。
Lambda架构的好处是:架构简单,很好的结合了离线批处理和实时流处理的优点,稳定且实时计算成本可控。
此外,它对数据订正也很友好。如果后期数据统计口径变更,重新运行离线任务,则可以很快的将历史数据订正为最新的口径。
然而,Lambda也有很多问题。
其中Jay Kreps认为最突出的问题就是需要同时维护实时处理和离线处理两套代码的同时还要保证两套处理结果保持一致。这无疑是非常让人头疼的。
什么是Kappa架构
Jay Kreps认为通过非常,非常快地增加并行度和重播历史来处理重新处理实时数据,避免在实时数据处理系统上再“粘粘”一个离线数据处理系统。于是,他提出了这样的架构:

Kafka或者其他消息中间件,具备保留多日数据的能力。正常情况下kafka都是吐出实时数据,经过实时处理系统,进入服务数据库(Serving DB)。
当系统需要数据订正时,重放消息,修正实时处理代码,扩展实时处理系统的并发度,快速回溯过去历史数据。
这样的架构简单,避免了维护两套系统还需要保持结果一致的问题,也很好解决了数据订正问题。
但它也有它的问题:
1、消息中间件缓存的数据量和回溯数据有性能瓶颈。通常算法需要过去180天的数据,如果都存在消息中间件,无疑有非常大的压力。同时,一次性回溯订正180天级别的数据,对实时计算的资源消耗也非常大。
2、在实时数据处理时,遇到大量不同的实时流进行关联时,非常依赖实时计算系统的能力,很可能因为数据流先后顺序问题,导致数据丢失。
例如:一个消费者在淘宝网上搜索商品。正常来说,搜索结果里,商品曝光数据应该早于用户点击数据产出。然而因为可能会因为系统延迟,导致相同商品的曝光数据晚于点击数据进入实时处理系统。如果开发人员没意识到这样的问题,很可能会代码设计成曝光数据等待点击数据进行关联。关联不上曝光数据的点击数据就很容易被一些简单的条件判断语句抛弃。
对于离线处理来说,消息都是批处理,不存在关联不上的情况。在Lambda架构下,即使实时部分数据处理存在一定丢失,但因为离线数据占绝对优势,所以对整体结果影响很小。即使当天的实时处理结果存在问题,也会在第二天被离线处理的正确结果进行覆盖。保证了最终结果正确。
Flink(Blink)的解法
先整理一下Lambda架构和Kappa架构的优缺点:
|
|
优点 |
缺点 |
|
Lambda |
1、架构简单 2、很好的结合了离线批处理和实时流处理的优点 4、稳定且实时计算成本可控 5、离线数据易于订正 |
1、实时、离线数据很难保持一致结果 2、需要维护两套系统 |
|
Kappa |
1、只需要维护实时处理模块 2、可以通过消息重放 3、无需离线实时数据合并 |
1、强依赖消息中间件缓存能力 2、实时数据处理时存在丢失数据可能。 |
Kappa在抛弃了离线数据处理模块的时候,同时抛弃了离线计算更加稳定可靠的特点。Lambda虽然保证了离线计算的稳定性,但双系统的维护成本高且两套代码带来后期运维困难。
为了实现流批处理一体化,Blink采用的将流处理视为批处理的一种特殊形式。因此在内部维持了若干张张流表。通过缓存时间进行约束,限定在一个时间段内的数据组成的表,从而将实时流转为微批处理。
理论上只要把时间窗口开的足够大,Flink的流表可以存下上百日的数据,从而保证微批处理的“微”足够大可以替换掉离线处理数据。
但这样做存在几个问题:
1.Flink的流表是放在内存中,不做持久化处理的。一旦任务发生异常,内存数据丢失,Flink是需要回溯上游消息流,从而转为Kappa的结构。
2.数据窗口开的越大,内存成本越高。受限于成本,对大量数据处理仍然有可支持的物理空间上限。
3.下游接收的通常都是处理结果,对于内存中的流表数据是无法直接访问的。这样无形中增加了开发成本。
结合以上几个问题,我们提出了混合数仓架构。试图在综合实时数仓和离线数仓的优点,尽量规避各自的缺点。
混合数仓(Omega架构)的解法
什么是ECS设计模式
在谈我们的解法的时候,必须要先提ECS的设计模式。
简单的说,Entity、Component、System分别代表了三类模型。
实体(Entity):实体是一个普通的对象。通常,它只包含了一个独一无二的ID值,用来标记它是一个独立的对象。
组件(Component):对象一个方面的数据,以及对象如何和世界进行交互。用来标记实体是否需要进行这一方面的处理,通常使用结构体,类或关联数组实现。
系统(System):每个系统不间断地运行(就像每个系统运行在自己的私有线程上),处理标记使用了该系统处理的组件的每个实体。
Entity对应于数仓中的Table,Component对应Schema,System对应数仓中SQL逻辑。
对于数仓来说,每张表的意义是由一群schema决定的。而每一个schema只代表一个含义。SQL代码的作用是组装schema到对应的table中,实现它的业务意义。对于一个OLAP系统,我们喜欢大宽表的意义就是因为OLAP分析的是schema之间的关系,用大宽表可以很轻易的提取所需要的schema,组装一个业务所需的表。
ECS设计模式的核心思想就是,所有shcema都独立出来,整个数仓就是一个大宽表。当需要使用的时候,把对应的schema组装成具有业务含义的table。这就像一个个Component组装成一个Entity一样。而SQL在其中起到的作用是就是产出对应的schema和组装schema。
将ECS设计模式引入数仓设计,希望开发者可以更加关注于逻辑,关注数据如何处理,也就是S的部分。业务则由从列构建表的时候产生。将表结构和数据处理逻辑进行拆分,从而希望能提升SQL代码的可读性和结构性。
传统数仓的数据处理流程
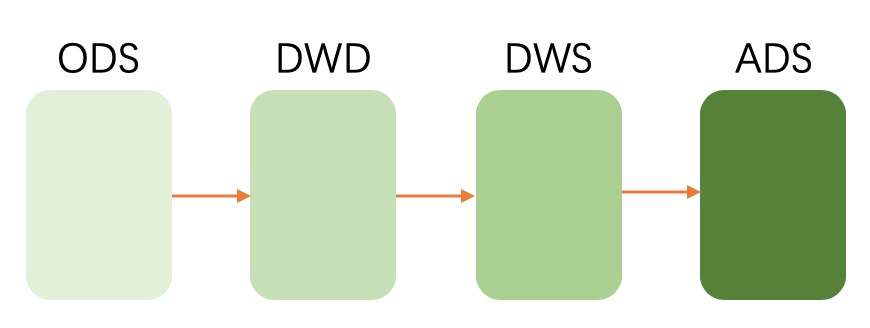
数仓通常是分为三层:ODS(原始数据),DW(数据仓库层),ADS(应用数据层)。ODS是从消息中间件中拿到的最原始的数据。DW层则是对数据进行加工后的数据,通常还是分为:DWS和DWD。DWD层中是对ODS层的数据进行清洗后提取的出来的。而DWS层是经过了一些轻度汇总后的数据。用户可以基于此层直接加工出ADS层所需的数据。ADS层则是产出应用最终所需的数据。
所以我们一般的数仓数据处理流程是:
基于ECS设计模式设计的混合数仓
在ECS的设计模式下,核心考虑的是Component是产出。产出具有业务含义的component,组装出具体的业务表(Entity)。
Schema的注册和Table注册
对应在数仓模型中,可以这么理解:数仓里的表,任何一个schema都是独立的。它们不具有业务含义,只是业务的一个属性。组合起来构成一个具有业务含义的表。
因此,我们需要一个专门管理schema的系统。这里包含了schema注册和shcema使用。schema注册系统主要负责对schema唯一性作保证,避免schema重复从而影响使用。同时规定好Schema从元数据中提取的规则(正则表达式或者拆分字符串),保证不论在什么系统中都可以得到唯一的提取结果。
schema的使用则依赖table注册系统。通过table注册系统,将一些具有相关含义的schema串联起来,形成table提供给业务使用。
如下图:
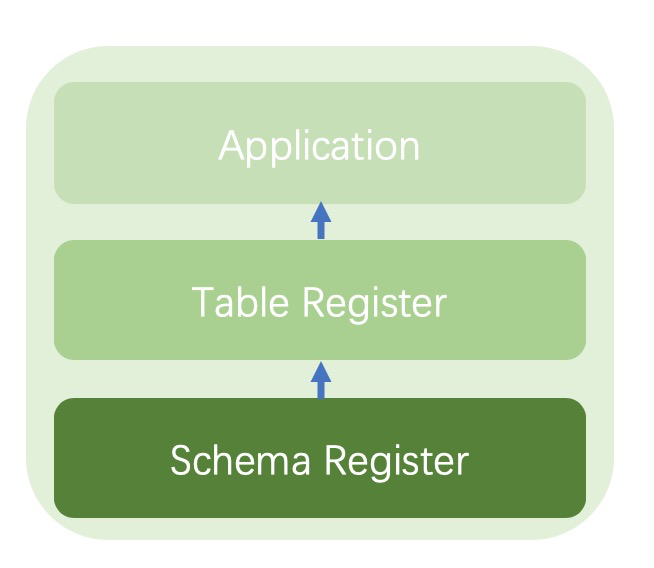
Schema开发与混合数仓架构
有了schema注册,就要提到schema产出的问题了。在上文提到过,在Lambda架构下,离线实时数仓需要同时维护两份代码,其实就是需要维护两份schema的注册和产出过程。在Kappa架构中,虽然只需要在实时数仓中做数据处理,但面对大量历史数据处理时需要消耗非常多的资源,而且中间结果复用能力有限,不适合复杂的业务。
由于我们将schema 注册抽离出来,在ECS的设计模式下,数据加工过程只有schema之间的交互,所以只需要关心数据加工部分代码。而对于Flink(Blink)与MaxCompute(ODPS)来说,数据处理部分的sql代码都遵循相近的SQL规范(这里没查到对应的SQL版本,但使用过程中感受是几乎一致,差别在于一些函数上。这一点可以通过UDF等方式解决。),所以可以保证很好的复用性。如果实时数仓和离线数仓数据处理层面的代码差异较大的话,可以引入编译器的形式解决。在任务提交的时候对代码进行差异化的编译,适用于对应的数仓。
从而我们可以画出以下的架构图:
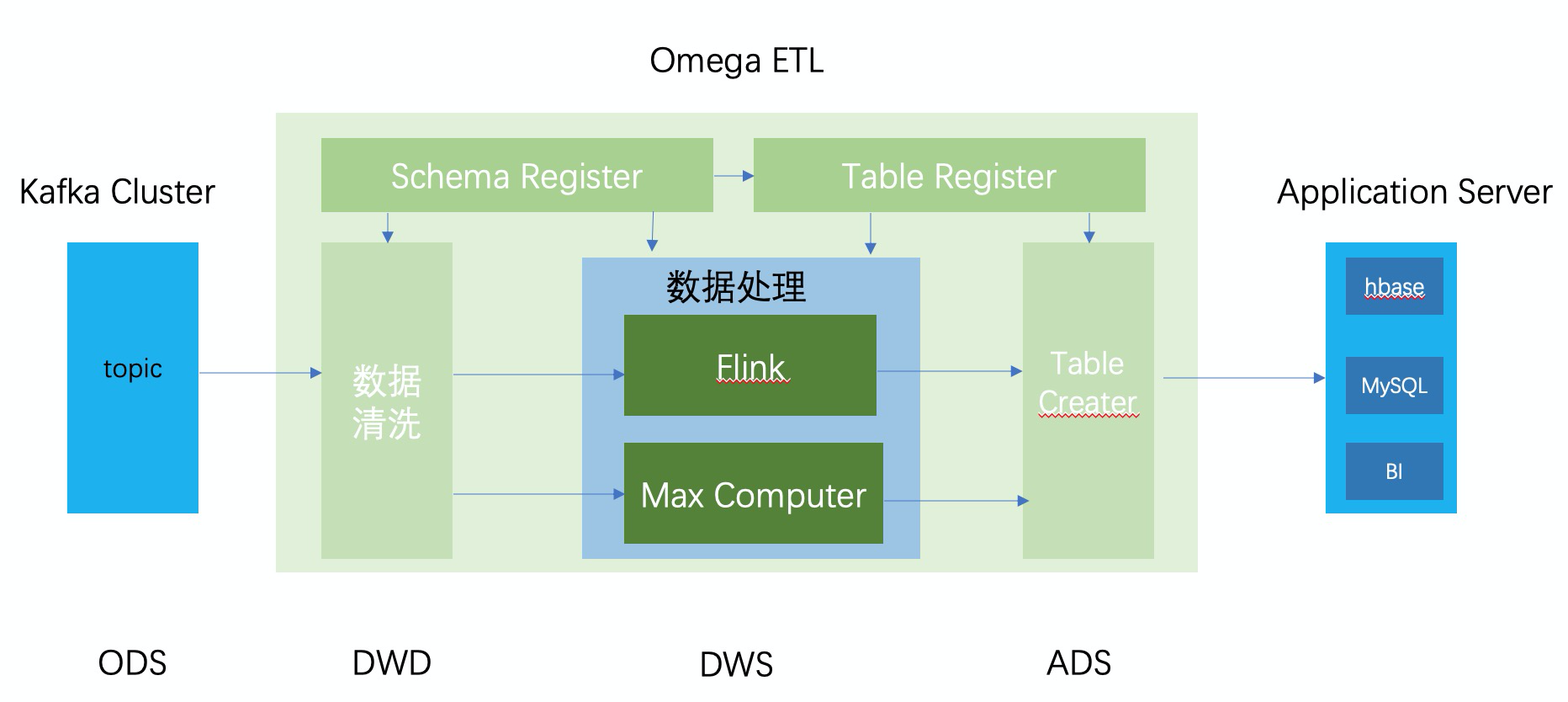
Kafka传入的消息是这套架构的ODS层,这一点上跟Lambda和Kappa架构是保持一致的。
数据进入数仓后,数据会被Schema Register中注册的规则提取出来,产出一个个对应的schema。即对应DWD层。
有了schema后,数据进入处理加工逻辑。即System部分。这里需要针对实时和离线数仓分别产出对应的加工代码,并执行具体的加工。此处对应的是DWS层。
最后,将加工后产出的schema和table Register系统结合,产出最终的ADS层的数据。
这套架构的好处是通过ECS设计模式的思想,将数据处理过程拆分成:数据声明(Schema Register,Table Register),数据处理(System)和结果拼接(Table Creater)三个流程。在这三个过程中,将Flink、Max Compute视为计算资源,将整体数据加工处理的逻辑独立在底层中间件之上,与开发环境解耦。从而实现工程化的管理数据仓库里的数据和加工过程。
但这套架构也存在一定的问题。例如,实时数据和离线数据是不互通的。如果统计过去180天UV总数时,需要离线和实时数据合并去重的处理就会遇到麻烦。
总结
我将这个架构命名为Omega架构,对应希腊字母中的Omega,含义是“终结”。我希望这套架构能解决目前实时数仓和离线数仓比较混乱的局面,可以让大数据开发、管理的能力更上一个台阶,让更多小伙伴可以更加方便的取数,加工,从而更好的服务于业务。
