cube
- 数据立方体(Data Cube),是多维模型的一个形象的说法.(关于多维模型这里不讲述,在数据仓库设计过程中还挺重要的,有兴趣自行查阅)
- 立方体其本身只有三维,但多维模型不仅限于三维模型,可以组合更多的维度
- 为什么叫数据立方体?
- 一方面是出于更方便地解释和描述,同时也是给思维成像和想象的空间;
- 另一方面是为了与传统关系型数据库的二维表区别开来
下图为数据立方体的形象图
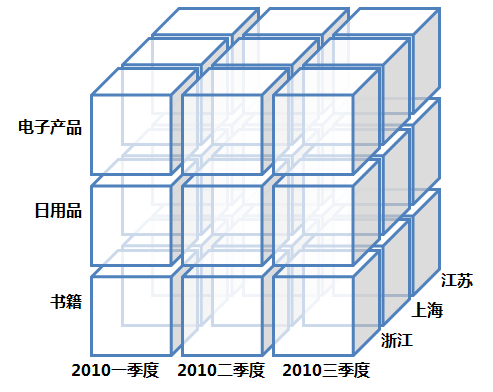
- 其实并不用把cube理解得很高大上,只要理解为分别按照不同维度进行聚合.
- hive中也有cube函数,可以实现多个任意维度的查询
- cube(a,b,c)则首先会对(a,b,c)进行group by,
- 然后依次是(a,b),(a,c),(a),(b,c),(b),(c),最后在对全表进行group by,他会统计所选列中值的所有组合的聚合
- 用cube函数就可以完成所有维度的聚合工作.
语法
select col1,col2,col3,col4, --维度字段
count(user_id), --聚合字段
GROUPING__ID, --聚合选取的组号(二进制表示,但是这里打印出来的是十进制)
rpad(reverse(bin(cast(GROUPING__ID AS bigint))),4,'0') --对其二进制化就能明白了,注意中间是两个下划线,因为在反转的时候会把末尾的0去掉,需要用rpad补充至维度个数
from table
group by col1,col2,col3,col4 --维度字段都要出现在group by中,这里不能使用1,2,3,4代替
with cube; --使用cube函数
- 如果我们想要手动实现cube函数就需要把所有维度的聚合都用union all来汇总.
- 可以说cube函数方便了用户的使用.
- 但是我并不用知道所有维度的聚合,我就想要col1,(col2,col3)的怎么办?
grouping sets
- 当不需要cube将所有维度都列出来的时候,当只需要部分维度的时候
- 可以使用grouping sets来进行决定聚合那些维度
语法
select col1,col2,col3, --维度字段
count(user_id), --聚合字段
GROUPING__ID, --聚合选取的组号(二进制表示,但是这里打印出来的是十进制)
rpad(reverse(bin(cast(GROUPING__ID AS bigint))),3,'0') --对其二进制化就能明白了,注意中间是两个下划线,注意中间是两个下划线,因为在反转的时候会把末尾的0去掉,需要用rpad补充至维度个数
from table
group by col1,col2,col3 --维度字段都要出现在group by中,并不能省略暂时不用到的字段,这里不能使用1,2,3,4代替
grouping sets(col1,(col2,col3)); --使用grouping sets来代替with cube
- 注意:当使用grouping sets()进行指定维度聚合的时候,仅仅聚合你给出的维度组合,并不会自动帮你组合维度.
- 例如 grouping sets(col1,(col2,col3)) 只聚合col1维度,(col2,col3)维度.
- 并不会自动聚合(col1,col2,col3)维度
rollup
- rullup函数是cube的子集,以最左侧维度为主,按照顺序依次进行聚合.
- 例如聚合的维度为 col1,col2,col3 使用rollup聚合的字段分别为 col1,(col1,col2),(col1,col3),(col1,col2,col3)
语法
select col1,col2,col3,col4, --维度字段
count(user_id), --聚合字段
GROUPING__ID, --聚合选取的组号(二进制表示,但是这里打印出来的是十进制)
rpad(reverse(bin(cast(GROUPING__ID AS bigint))),4,'0') --对其二进制化就能明白了,注意中间是两个下划线,注意中间是两个下划线,因为在反转的时候会把末尾的0去掉,需要用rpad补充至维度个数
from table
group by col1,col2,col3,col4 --维度字段都要出现在group by中,这里不能使用1,2,3,4代替
with rollup; --使用rollup函数
如何查看根据什么维度聚合呢?
select user_type,sales, --维度
count(user_id) as pv, --聚合字段
grouping__id,
rpad(reverse(bin(cast(GROUPING__ID AS bigint))),2,'0') as sign --grouping__id逆序
from user_info
group by user_type,sales
with cube;
查询结果如下
| user_type | sales | pv | grouping__id | sign |
|---|---|---|---|---|
| NULL | NULL | 10 | 0 | 00 |
| old | NULL | 3 | 1 | 10 |
| new | NULL | 7 | 1 | 10 |
| old | 3 | 1 | 3 | 11 |
| old | 2 | 1 | 3 | 11 |
| old | 1 | 1 | 3 | 11 |
| new | 6 | 1 | 3 | 11 |
| new | 5 | 2 | 3 | 11 |
| new | 3 | 1 | 3 | 11 |
| new | 2 | 1 | 3 | 11 |
| new | 1 | 2 | 3 . | 11 |
- 上面是使用cube函数聚合后的数据
- 可以根据 GROUPING__ID 的二进制表示形式(反向)直接看出.
- 这里使用聚合的维度有user_type和sales两个维度,如果使用当前维度,对应bin(grouping__id)数字为1
- 例如 第二行数据的 10 -> 使用了user_type维度,没使用sales
- 可以通过聚合后的数据看出
- 当改字段为NULL的时候,说明没有使用该字段维度.
- 例如 第二行数据 old NULL -> 使用了user_type维度,没使用sales
