Flink中的failover分为task的failover和Master的failover。
我们先来看task的failover,它有多种策略:
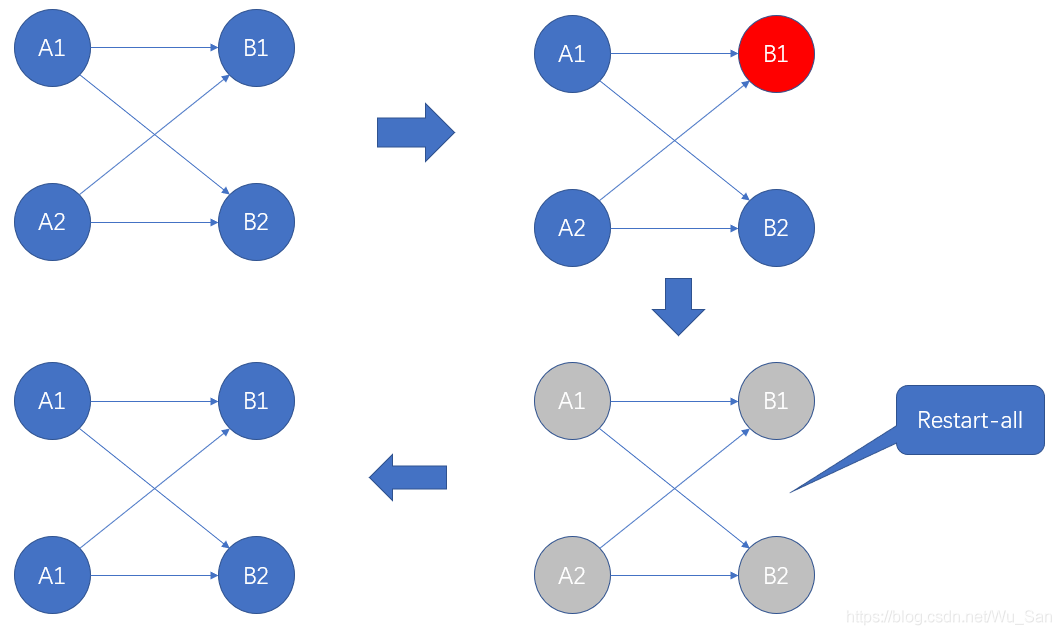
1.Restart-all
重启所有的task,从上次的Checkpoint开始重新执行。
2.Restart-individual
只重启出错的task,只适用于task间无连接的情况,应用场景有限。

3.Restart-region
重启pipeline region。因为block边数据落盘,可以直接读取,逻辑上仅需重启通过pipeline边关联的task。
(block边:数据有落盘。pipeline边:数据不落盘)
Flink中task的failover机制_Wu_San的博客
CSDN博客 · · 2755 次点击 · · 开始浏览这是一个创建于 的文章,其中的信息可能已经有所发展或是发生改变。
- 请尽量让自己的回复能够对别人有帮助
- 支持 Markdown 格式, **粗体**、~~删除线~~、
`单行代码` - 支持 @ 本站用户;支持表情(输入 : 提示),见 Emoji cheat sheet
- 图片支持拖拽、截图粘贴等方式上传
今日阅读排行

一周阅读排行
Flink中的failover分为task的failover和Master的failover。
我们先来看task的failover,它有多种策略:
1.Restart-all
重启所有的task,从上次的Checkpoint开始重新执行。
2.Restart-individual
只重启出错的task,只适用于task间无连接的情况,应用场景有限。
3.Restart-region
重启pipeline region。因为block边数据落盘,可以直接读取,逻辑上仅需重启通过pipeline边关联的task。
(block边:数据有落盘。pipeline边:数据不落盘)