Apache Hudi
http://hudi.apache.org/docs/quick-start-guide.html
Hudi是什么
Hudi将流处理带到大数据,提供新数据,同时比传统批处理效率高一个数量级。
Hudi可以帮助你构建高效的数据湖,解决一些最复杂的底层存储管理问题,同时将数据更快地交给数据分析师,工程师和科学家。
Hudi不是什么
Hudi不是针对任何OLTP案例而设计的,在这些情况下,通常你使用的是现有的NoSQL / RDBMS数据存储。Hudi无法替代你的内存分析数据库(至少现在还没有!)。Hudi支持在几分钟内实现近乎实时的摄取,从而权衡了延迟以进行有效的批处理。
增量处理
增量处理仅是指以流处理方式编写微型批处理程序。典型的批处理作业每隔几个小时就会消费所有输入并重新计算所有输出。典型的流处理作业会连续/每隔几秒钟消费一些新的输入并重新计算新的/更改以输出。尽管以批处理方式重新计算所有输出可能会更简单,但这很浪费并且耗费昂贵的资源。Hudi具有以流方式编写相同批处理管道的能力,每隔几分钟运行一次。
虽然可将其称为流处理,但我们更愿意称其为增量处理,以区别于使用Apache Flink,Apache Apex或Apache Kafka Streams构建的纯流处理管道。
Hudi基于MVCC设计
将数据写入parquet/基本文件以及包含对基本文件所做更改的日志文件的不同版本。

存储类型和视图
Hudi存储类型定义了如何在DFS上对数据进行索引和布局以及如何在这种组织之上实现上述原语和时间轴活动(即如何写入数据)。
反过来,视图定义了基础数据如何暴露给查询(即如何读取数据)。
| 存储类型 | 支持的视图 |
|---|---|
| 写时复制 | 读优化 + 增量 |
| 读时合并 | 读优化 + 增量 + 近实时 |
两种存储类型:
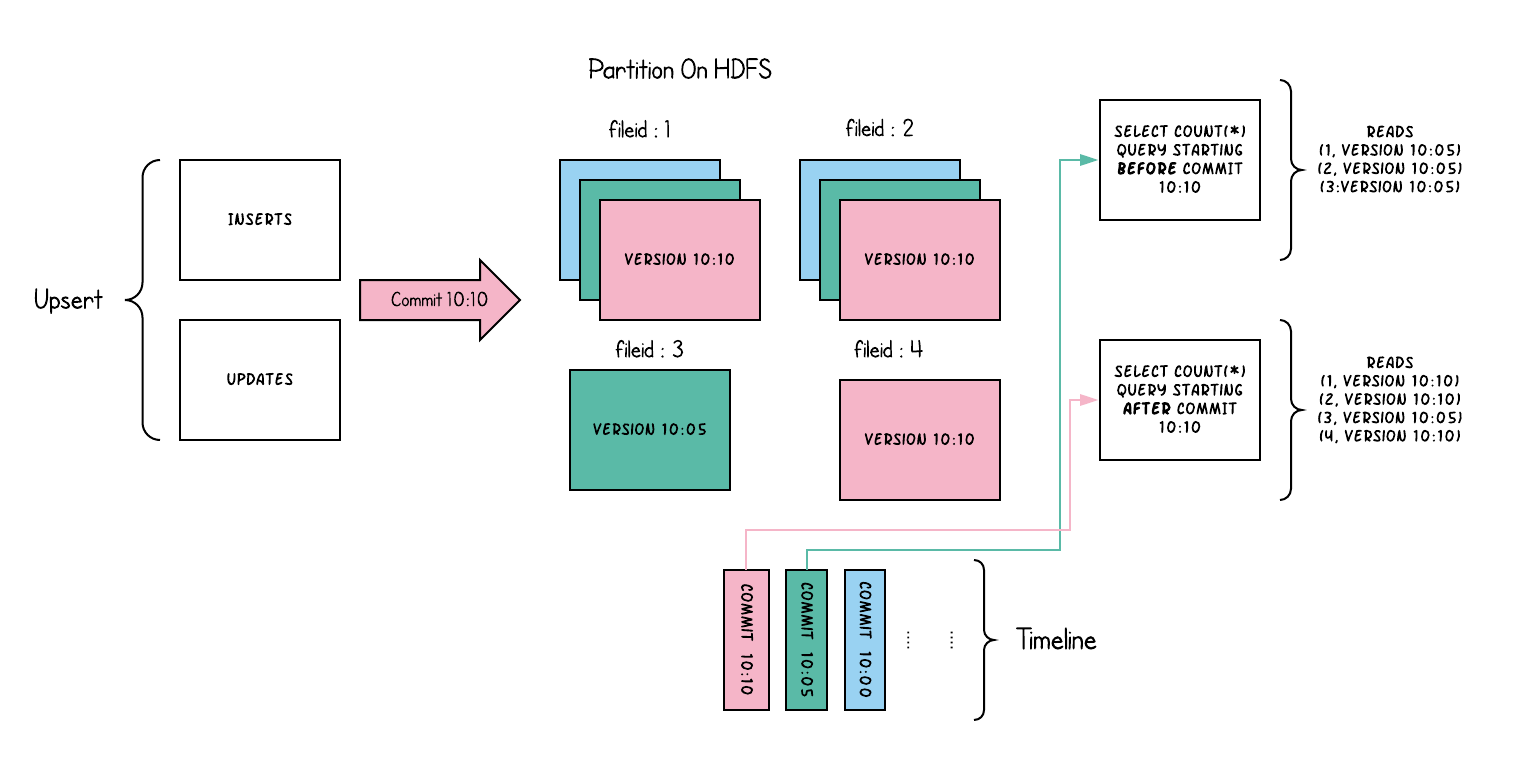
写时复制(copy on write):仅使用列式文件(parquet)存储数据。在写入/更新数据时,直接同步合并原文件,生成新版本的基文件(需要重写整个列数据文件,即使只有一个字节的新数据被提交)。此存储类型下,写入数据非常昂贵,而读取的成本没有增加,所以适合频繁读的工作负载,因为数据集的最新版本在列式文件中始终可用,以进行高效的查询。
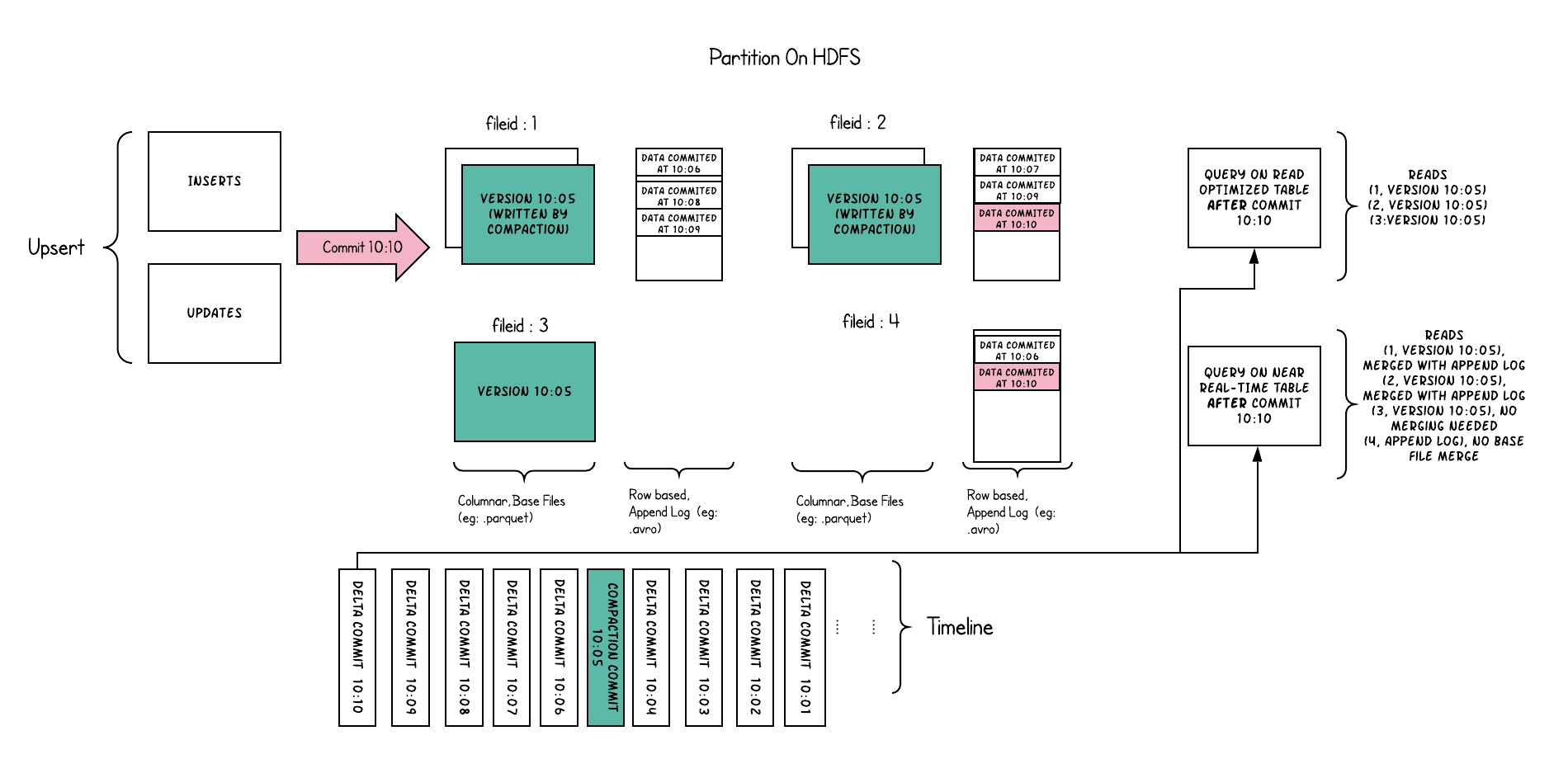
读时合并(merge on read):使用列式(parquet)与行式(avro)文件组合,进行数据存储。在更新记录时,更新到增量文件中(avro),然后进行异步(或同步)的compaction,创建列式文件(parquet)的新版本。此存储类型适合频繁写的工作负载,因为新记录是以appending 的模式写入增量文件中。但是在读取数据集时,需要将增量文件与旧文件进行合并,生成列式文件。
存储数据的视图(查询模式):
读优化视图(Read Optimized view):直接query 基文件(数据集的最新快照),也就是列式文件(如parquet)。相较于非Hudi列式数据集,有相同的列式查询性能
增量视图(Incremental View):仅query新写入数据集的文件,也就是指定一个commit/compaction,query此之后的新数据。
实时视图(Real-time View):query最新基文件与增量文件。此视图通过将最新的基文件(parquet)与增量文件(avro)进行动态合并,然后进行query。可以提供近实时的数据(会有几分钟的延迟)
写时复制存储
以下内容说明了将数据写入写时复制存储并在其上运行两个查询时,它是如何工作的:
读时合并存储
以下内容说明了存储的工作方式,并显示了对近实时表和读优化表的查询:
参考:
