一、前言
哈希存储引擎 是哈希表的持久化实现,支持增、删、改以及随机读取操作,但不支持顺序扫描,对应的存储系统为key-value存储系统。对于key-value的插入以及查询,哈希表的复杂度都是O(1),明显比树的操作O(n)快,如果不需要有序的遍历数据,哈希表就是your Mr.Right
B树存储引擎是B树的持久化实现,不仅支持单条记录的增、删、读、改操作,还支持顺序扫描(B+树的叶子节点之间的指针),对应的存储系统就是关系数据库(Mysql等)。
LSM树(Log-Structured Merge Tree)存储引擎和B树存储引擎一样,同样支持增、删、读、改、顺序扫描操作。而且通过批量存储技术规避磁盘随机写入问题。当然凡事有利有弊,LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。
二、 LSM树
传统关系型数据库使用btree或一些变体作为存储结构,能高效进行查找。但保存在磁盘中时它也有一个明显的缺陷,那就是逻辑上相离很近但物理却可能相隔很远,这就可能造成大量的磁盘随机读写。随机读写比顺序读写慢很多,为了提升IO性能,我们需要一种能将随机操作变为顺序操作的机制,于是便有了LSM树。LSM树能让我们进行顺序写磁盘,从而大幅提升写操作,作为代价的是牺牲了一些读性能。
磁盘读写时涉及到磁盘上数据查找,地址一般由柱面号、盘面号和块号三者构成。也就是说移动臂先根据柱面号移动到指定柱面,然后根据盘面号确定盘面的磁道,最后根据块号将指定的磁道段移动到磁头下,便可开始读写。整个过程主要有三部分时间消耗,查找时间(seek time) +等待时间(latency time)+传输时间(transmission time) 。分别表示定位柱面的耗时、将块号指定磁道段移到磁头的耗时、将数据传到内存的耗时。整个磁盘IO最耗时的地方在查找时间,所以减少查找时间能大幅提升性能。
LSM树原理把一棵大树拆分成N棵小树,它首先写入内存中,随着小树越来越大,内存中的小树会flush到磁盘中,磁盘中的树定期可以做merge操作,合并成一棵大树,以优化读性能。No-SQL数据库一般采用LSM树作为数据结构,HBase也不例外。
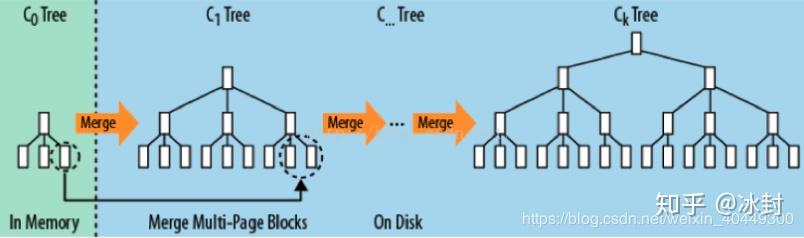

LSM和Btree差异就要在读性能和写性能进行取舍。在牺牲的同时,寻找其他方案来弥补。
1、LSM具有批量特性,存储延迟。当写读比例很大的时候(写比读多),LSM树相比于B树有更好的性能。因为随着insert操作,为了维护B树结构,节点分裂。读磁盘的随机读写概率会变大,性能会逐渐减弱。 多次单页随机写,变成一次多页随机写,复用了磁盘寻道时间,极大提升效率。
2、B树的写入过程:对B树的写入过程是一次原位写入的过程,主要分为两个部分,首先是查找到对应的块的位置,然后将新数据写入到刚才查找到的数据块中,然后再查找到块所对应的磁盘物理位置,将数据写入去。当然,在内存比较充足的时候,因为B树的一部分可以被缓存在内存中,所以查找块的过程有一定概率可以在内存内完成,不过为了表述清晰,我们就假定内存很小,只够存一个B树块大小的数据吧。可以看到,在上面的模式中,需要两次随机寻道(一次查找,一次原位写),才能够完成一次数据的写入,代价还是很高的。
3、LSM Tree放弃磁盘读性能来换取写的顺序性,似乎会认为读应该是大部分系统最应该保证的特性,所以用读换写似乎不是个好买卖。内存的速度远超磁盘,1000倍以上。而读取的性能提升,主要还是依靠内存命中率而非磁盘读的次数。
LSM数据更新只在内存中操作,没有磁盘访问,因此比B+树要快。对于数据读来说,如果读取的是最近访问过的数据,LSM树能减少磁盘访问,提高性能。 LSM树实质上就是在读写之间得取衡平,和B+树比相,它牲牺了部份读性能,用来大幅进步写性能。
三、LSM Tree优化方式
1、Bloom filter: 就是个带随即概率的bitmap,可以快速的告诉你,某一个小的有序结构里有没有指定的那个数据的。于是就可以不用二分查找,而只需简单的计算几次就能知道数据是否在某个小集合里啦。效率得到了提升,但付出的是空间代价。
2、compact:小树合并为大树:因为小树他性能有问题,所以要有个进程不断地将小树合并到大树上,这样大部分的老数据查询也可以直接使用log2N的方式找到,不需要再进行(N/m)*log2n的查询了
四、Hbase对LSM-Tree的使用方式
hbase在实现中,是把整个内存在一定阈值后,flush到disk中,形成一个file,这个file的存储也就是一个小的B+树,因为hbase一般是部署在hdfs上,hdfs不支持对文件的update操作,所以hbase这么整体内存flush,而不是和磁盘中的小树merge update。内存flush到磁盘上的小树,定期也会合并成一个大树。整体上hbase就是用了lsm tree的思路。
因为小树先写到内存中,为了防止内存数据丢失,写内存的同时需要暂时持久化到磁盘,对应了HBase的HLog(WAL)和MemStore
MemStore上的树达到一定大小之后,需要flush到HRegion磁盘中(一般是Hadoop DataNode),这样MemStore就变成了DataNode上的磁盘文件StoreFile,定期HRegionServer对DataNode的数据做merge操作,彻底删除无效空间,多棵小树在这个时机合并成大树,来增强读性能。
数据写(插入,更新):数据首先顺序写如hlog (WAL), 然后写到MemStore, 在MemStore中,数据是一个2层B+树(图2中的C0树)。MemStore满了之后,数据会被刷到storefile (hFile),在storefile中,数据是3层B+树(图2中的C1树),并针对顺序磁盘操作进行优化。
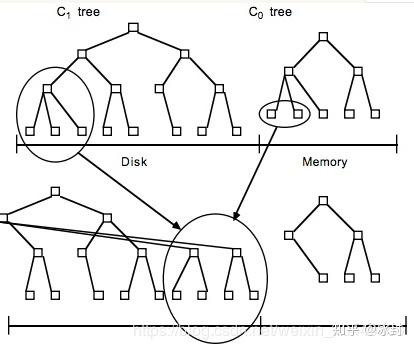
数据读:首先搜索BlockCache,再搜索MemStore,如果不在MemStore中,则到storefile中寻找。
数据删除:不会去删除磁盘上的数据,而是为数据添加一个删除标记。在随后的major compaction中,被删除的数据和删除标记才会真的被删除。
